
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!



HuggingFace&Github
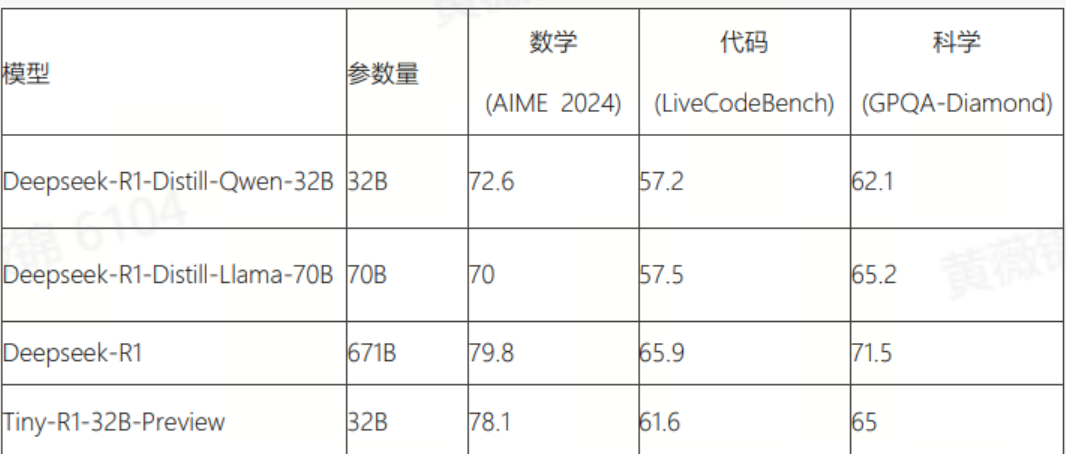
TinyR1-32B-Preview:仅用 5% 的参数接近 R1 模型的性能
Tiny-R1-32B-Preview是由北大计算机学院与360公司联合发布的32B模型,仅以5%参数,逼近Deepseek-R1-671B的性能。结合DeepSeek-R1蒸馏、DeepSeek-R1-Distill-32B增量训练、模型融合等技术,使用360-LLaMA-Factory训练而来。
-
数学领域:逼近原版R1模型,远超Deepseek-R1-Distill-Llama-70B
-
综合性能:在编程(LiveCodeBench 61.6分)、科学(GPQA-Diamond 65.0分)领域全面领先最佳开源70B模型Deepseek-R1-Distill-Llama-70B;
-
效率跃迁:仅需5%参数量,推理成本大幅降低。
Tiny-R1-32B-Preview基于DeepSeek-R1生成海量领域数据,分别训练数学、编程、科学三大垂直模型。
https://huggingface.co/qihoo360/TinyR1-32B-Preview
学习
大模型彻底进入fp8时代-DeepGEMM
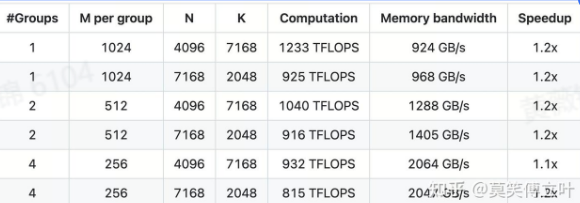
DeepGEMM 是一个专为高效的 FP8 通用矩阵乘法(GEMM)设计的库,支持普通 GEMM 和混合专家(MoE)组 GEMM。它通过 CUDA 实现,采用即时(JIT)编译方式,避免了安装时的编译过程,所有内核在运行时即时编译。该库目前仅支持 NVIDIA Hopper 架构的张量核心,并且为解决 FP8 张量核心累积中的不精确性,采用了 CUDA 核心的两级累积提升技术。虽然 DeepGEMM 借鉴了 CUTLASS 和 CuTe 的一些设计概念,但其简化设计使得它成为一个容易理解和使用的资源,适合学习 Hopper FP8 矩阵乘法的优化技术。
DeepGEMM 提供了三种主要的矩阵乘法实现:普通 GEMM、MoE 模型的连续布局分组 GEMM 和 MoE 模型的掩码布局分组 GEMM。针对 MoE 模型,连续布局分组 GEMM 允许对 M 轴进行分组,而 N 轴和 K 轴保持固定,专为多个专家处理不同 Token 的场景而设计。掩码布局分组 GEMM 则在推理解码阶段使用掩码,仅计算有效部分,适用于动态 Token 数量的场景。
性能方面,DeepGEMM 在多种矩阵形状下表现出色,并在一些情况下超过了其他优化库的表现。通过对矩阵的分块和内存对齐进行精细优化,该库能够有效利用 Hopper 架构的 TMA(张量内存加速器)特性,实现更高效的内存加载和存储,进一步提升了性能。
为了确保性能,DeepGEMM 采用了持久的 Warp 专用化设计,能够重叠数据移动、张量核心的 MMA 指令和 CUDA 核心的提升。它还优化了 SM 利用率和 L2 缓存重用,并通过 JIT 编译动态选择最佳的配置,以适应不同的矩阵形状和计算需求。通过调整块大小、warpgroup 数量以及流水线阶段的配置,DeepGEMM 提高了小尺寸形状的矩阵运算性能,类似于 Triton 编译器的做法。
DeepGEMM 还支持未对齐的块大小分配,这样可以更好地利用 SM 资源,避免块对齐到 2 的幂时的资源浪费。此外,该库在优化 FP8 GEMM 过程中,使用了 FFMA SASS 交错技术,通过修改编译后的二进制文件中的 FFMA 指令,进一步提高了细粒度缩放 FP8 GEMM 的性能。
总的来说,DeepGEMM 是一个高效、简洁的库,专注于 FP8 GEMM 内核的优化,能够充分发挥 Hopper 架构的硬件特性,提供卓越的性能,适用于各种 AI 模型的推理加速。
https://zhuanlan.zhihu.com/p/26436168971
ColossalAI重大Bug揭秘:DeepSeek-R1模型微调陷阱
本文深度剖析了ColossalAI框架在DeepSeek-R1模型微调中出现的重大技术缺陷。通过逐层拆解框架的初始化机制、参数加载流程,最终定位到LoRA适配器引入导致的参数命名空间污染问题。研究结果表明:动态模型架构适配需要配套的参数映射机制
提出的参数重映射解决方案经过实践验证,能够有效恢复模型训练性能。期待ColossalAI框架能尽快推出官方修复方案。
https://zhuanlan.zhihu.com/p/26682456562
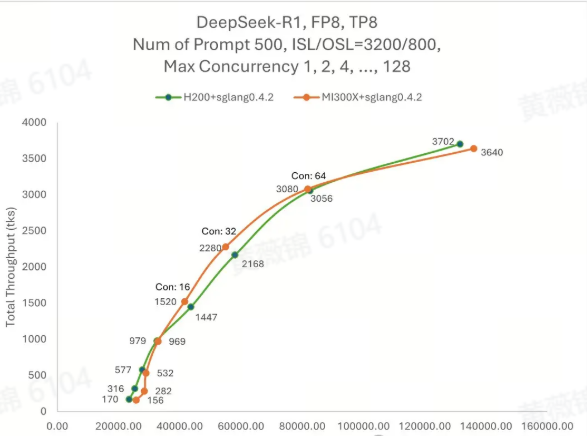
解锁DeepSeek-R1 671B FP8推理性能:5,921 token/s @ AMD MI300X
本文讨论了如何通过使用 AMD Instinct™ MI300X GPU 实现 DeepSeek-R1 的竞争性能,并与 H200 性能进行比较。通过在 MI300X 上优化 DeepSeek-R1 和 V3 模型,用户可以在单节点上高效部署这些模型,并实现显著的性能提升。特别是在短短两周内,通过使用 SGLang 框架优化,推理速度提升了四倍,显著降低了延迟和提高了吞吐量,尤其适合大规模 AI 工作负载处理。MI300X 的高带宽内存(HBM)和强大的计算能力使其能高效支持更长序列的推理,满足复杂的现实世界应用需求。
DeepSeek-R1 是一个包含超过 640GB 参数的复杂模型,在多头潜在注意力(MLA)和混合专家(MoE)架构下,执行推理任务时需要经过高度优化的内核以确保性能。因此,调整 FP8 精度的 GEMM 内核对最大化吞吐量和性能至关重要。SGLang 框架,作为高效的开源 LLM 服务框架,针对 AMD Instinct GPU 进行了特别优化,支持大规模模型的推理服务。
SGLang 提供了通过 Docker 镜像在 MI300X 上运行 DeepSeek-R1 模型的能力,预构建的 Docker 镜像简化了用户的部署过程,提供了一个开箱即用的体验。在基准测试中,使用 SGLang 后,DeepSeek-R1 在 MI300X 上的推理性能提升了四倍,性能表现优异,特别是对于并发请求较多的场景,其每个输出令牌的处理时间(TPOT)在 50 毫秒以下,适合在线推理等低延迟应用。对于离线工作负载,系统可以进一步优化吞吐量,满足大规模推理需求。
除了提升性能,AMD 与 SGLang 还在进一步优化中,未来将加入 MoE 内核融合、MLA 内核融合、推测解码等技术,以提升 DeepSeek-R1 的推理体验。预计这些优化将进一步提高扩展性和推理速度,使其更加高效地支持现实世界应用。
总的来说,MI300X GPU 的强大性能为 DeepSeek-R1 提供了出色的推理支持,尤其是在处理长序列和高并发场景下。借助 SGLang 框架,开发者可以利用 AMD Instinct GPU 的优势,快速部署和优化大规模语言模型,充分释放硬件潜力。
https://zhuanlan.zhihu.com/p/26678527011
大模型辅助编程手册
华泰证券金融工程发布的《大模型辅助编程手册》详细介绍了多种大模型辅助编程工具及其应用。这些工具分为插件类和IDE类,旨在提升开发效率和代码质量。插件类工具如Github Copilot、CodeGPT、MarsCode、Codeium和Cline,通过集成到开发环境中提供代码补全、生成和解释等功能。其中,Cline以其自动化编程能力和多模型适配性脱颖而出,支持用户嵌入模型API并处理复杂任务。IDE类工具如Cursor、Windsurf和MarsCode IDE,提供更全面的编程辅助,支持多文件编辑和全局代码理解。Cursor的Composer功能特别适用于大型项目,能够根据高级指令生成整个应用程序。报告推荐结合VSCode+Cline+DeepSeek与Cursor的配置,以兼顾开发灵活性与深度交互需求。这些工具在量化策略开发等实际应用中展现出显著的效率和质量提升潜力。
https://mp.weixin.qq.com/s/ZmJVV__xG1XNRMkjMZ0mMw
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/43165.html