我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
信号
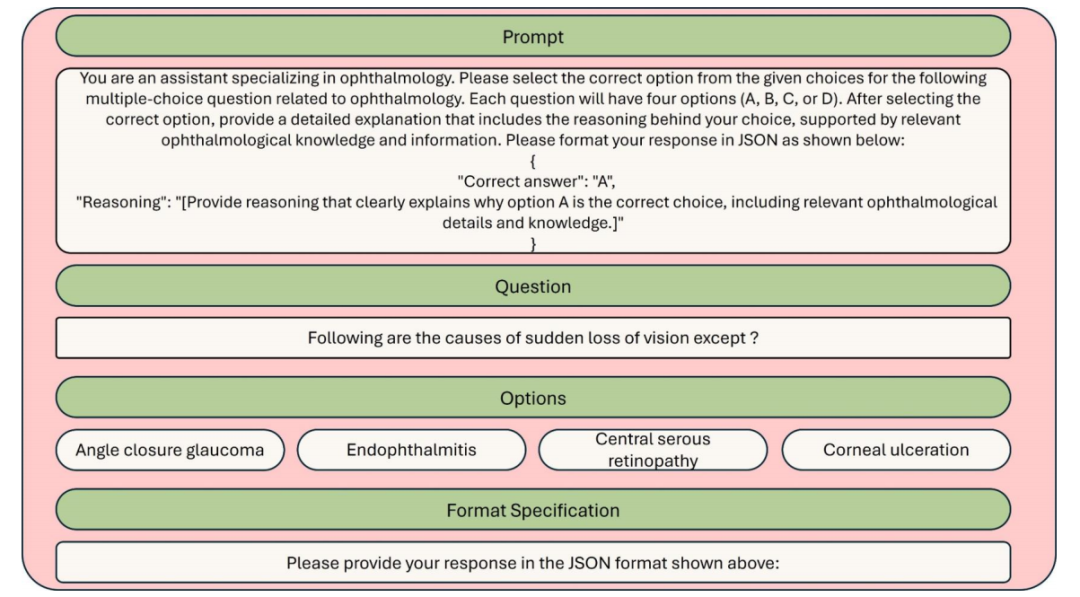
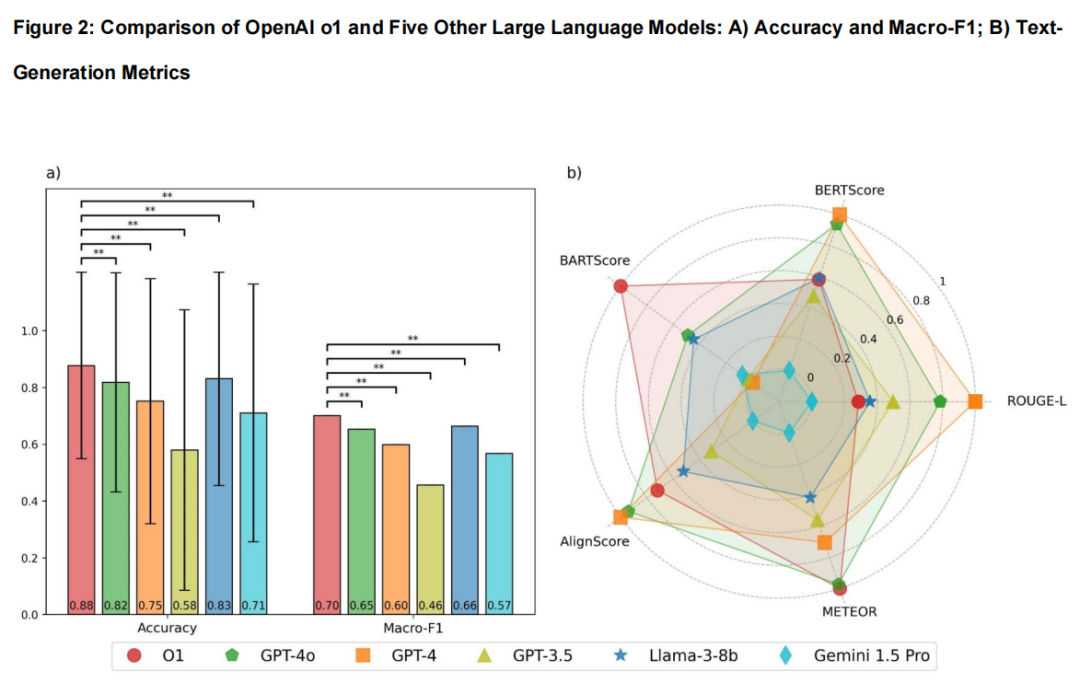
Can OpenAI o1 Reason Well in Ophthalmology? A 6,990-Question Head-to-Head Evaluation Study 本文评估了OpenAI最新推出的大型语言模型o1在眼科领域的表现和推理能力,并与其他五个常用的语言模型进行了对比。研究使用了6,990个眼科多选题,这些题目来自MedMCQA数据集。结果显示,o1在准确性方面表现最佳,准确率达到0.88,宏观F1得分为0.70,但在推理能力方面,根据文本生成指标,o1排名第三,落后于GPT-4o和GPT-4。这表明,尽管o1在一般领域可能具有较强的推理能力,但在眼科这一专业领域,其推理能力并未完全体现出来,强调了在专业医疗领域如眼科中,对语言模型进行领域特定优化的必要性。 在方法上,研究者选择了六个模型进行评估,包括OpenAI的o1、GPT-4o、GPT-4、GPT-3.5、Llama-3-8b和Gemini 1.5 Pro。这些模型通过各自的API访问,并使用MedMCQA数据集的眼科子集进行测试。每个模型都以标准化格式输入问题,并要求以零样本方式回答,同时提供解释。为了评估准确性,研究使用了传统准确率和宏观F1得分;为了评估推理能力,使用了ROUGE-L、BERTScore、BARTScore、AlignScore和METEOR等文本生成指标。 结果表明,在准确性方面,o1的表现优于其他所有模型,准确率达到0.88,宏观F1得分为0.70。然而,在推理评估中,o1的表现不如GPT-4o和GPT-4,特别是在ROUGE-L、BERTScore和AlignScore等指标上。尽管如此,o1在BARTScore和METEOR指标上表现突出。此外,o1在“Lens”和“Glaucoma”等子主题中表现最佳,但在“Corneal and External Diseases”、“Vitreous and Retina”和“Oculoplastic and Orbital Diseases”等子主题中,o1的表现次于GPT-4o。进一步的亚组分析显示,o1在处理较长的解释性文本时表现更好。
研究节点:训练体系->预训练 pre-train->模型设计、训练体系->预训练 pre-train->训练策略、训练体系->预训练 pre-train->目标函数、训练体系->后训练 post-train->微调 Fine-tune、应用-产品体系->AI+各行业->AI医疗 原文链接: https://arxiv.org/pdf/2501.13949 信号源: National University of Singapore、Yale University AKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit Quantization for Vision-Language Models 本文介绍了一种名为AKVQ-VL的方法,旨在优化视觉语言模型(VLMs)中的键值(KV)缓存量化,以减少内存消耗并提高效率。视觉语言模型(VLMs)在多模态任务中表现出色,但处理长多模态输入时,会产生过大的KV缓存,导致显著的内存消耗和I/O瓶颈。现有的KV量化方法主要针对大型语言模型(LLMs),忽略了VLM中多模态token的注意力显著性差异,导致性能不佳。
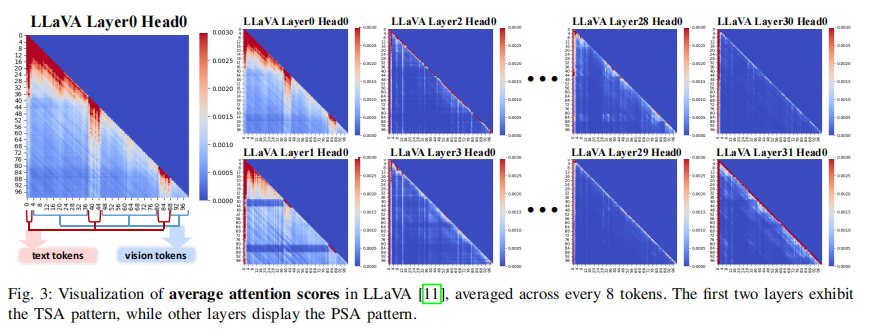
注意力感知的显著性模式:通过分析VLM的注意力机制,发现VLM在初始层优先关注文本token(文本显著性注意力,TSA),而在后续层则关注少数关键token(关键token显著性注意力,PSA)。
自适应量化:基于TSA和PSA模式,AKVQ-VL对显著token分配更高的精度,而对其他token使用2位量化,以优化压缩效率。
Walsh-Hadamard变换(WHT):用于减少KV缓存中的异常值,降低量化难度,实现无异常值的KV缓存。
准确性:在12个多模态任务上的评估表明,AKVQ-VL在2位量化下保持甚至提高了准确性,优于现有的LLM导向方法。
效率提升:AKVQ-VL将峰值内存使用减少了2.13倍,支持的批量大小增加了3.25倍,吞吐量提高了2.46倍。
AKVQ-VL是首个专为VLM设计的KV缓存量化方法,通过注意力感知的显著性模式和WHT技术,实现了几乎无损的2位量化,显著降低了内存使用并提高了吞吐量,同时保持了强大的下游任务性能。未来的工作将重点进一步优化AKVQ-VL以提高效率。
研究节点:训练体系->多/跨模态->多模态理解 Multimodal understanding、算力体系->MLSys->模型量化 quantilization、算力体系->MLSys->KV Cache KV缓存优化、架构体系->注意力机制 Attention Mechanism->自注意力 (Self-Attention)
原文链接:https://arxiv.org/pdf/2501.15021
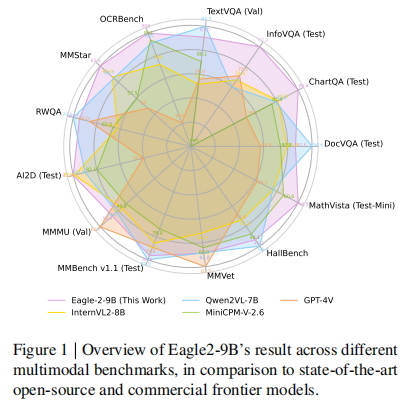
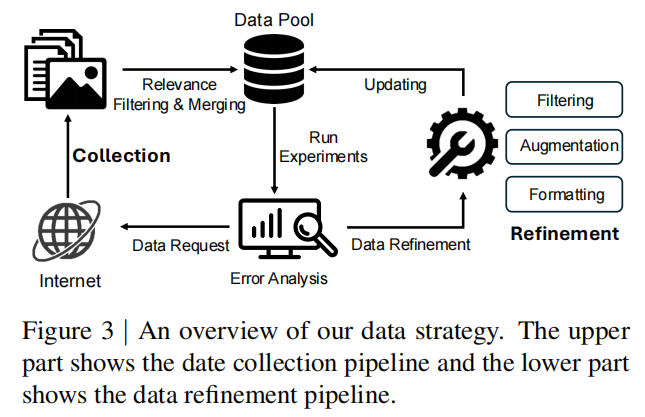
Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models 这篇论文介绍了一个名为 Eagle 2 的视觉语言模型(VLM),重点探讨了其在数据策略、模型架构和训练方法上的创新。研究指出,尽管开源的 VLMs 在能力上逐渐接近专有的前沿模型,但大多数开源模型仅发布最终的模型权重,对数据策略和实现细节缺乏透明度。Eagle 2 通过从头开始构建数据策略,分享了详细的开发过程,旨在为开源社区提供开发竞争力模型的参考。 Eagle 2 的数据策略包括大规模多样化数据池的构建、低质量样本的过滤、高质量子集的选择以及数据增强技术的应用。模型架构方面,Eagle 2 采用了动态图像分块和视觉编码器的混合设计,以处理高分辨率输入并保持对视觉信息的鲁棒感知。训练方法上,Eagle 2 采用了三阶段训练策略,包括初始阶段的 MLP 连接器训练、大规模多样化数据的预训练以及高质量视觉指令调整数据的微调。 实验结果表明,Eagle 2 在多个基准测试中取得了优异的性能,尤其是在图表、表格和 OCR 相关任务上。Eagle 2-9B 模型在多个任务上的表现超过了现有的开源模型,甚至在某些方面接近或超过了商业模型。研究还强调了数据策略在开发前沿 VLMs 中的关键作用,并希望通过分享这些详细的实践方法,为社区提供透明的参考,以加速 VLMs 的研究和开发。
研究节点:训练体系->后训练 post-train、训练体系->多/跨模态->多模态理解 Multimodal understanding、训练体系->多/跨模态->多模态评估 Multimodal Evaluation 原文链接:https://arxiv.org/pdf/2501.14818 DeepRAG: Thinking to Retrieval Step by Step for Large Language Models 大型语言模型(LLMs)在推理方面表现出显著潜力,但由于参数化知识的及时性、准确性和覆盖范围的限制,仍然存在严重的事实幻觉问题。检索增强生成(RAG)通过整合知识库或搜索引擎的相关信息来解决这一问题,但将推理与检索增强生成结合仍然具有挑战性,因为复杂的查询通常需要多步分解以建立连贯的推理过程,而迭代检索可能会引入噪声并降低响应质量。 DeepRAG 将检索增强推理建模为一个马尔可夫决策过程(MDP),引入了两个关键组件:检索叙事(retrieval narrative)和原子决策(atomic decisions),以实现战略性和适应性的检索。
检索叙事:确保结构化和适应性的检索流程,生成基于先前检索信息的子查询。
原子决策:对于每个子查询,动态决定是否检索外部知识或仅依赖 LLM 的参数化知识。
二叉树搜索:为每个子查询构建二叉树,探索基于参数化知识或外部知识库的不同回答策略。
模仿学习:通过合成数据进行模仿学习,使模型学习检索模式。
校准链:通过校准每个原子决策,校准 LLM 的内部知识。
实验使用了五个开放域问答数据集,包括 HotpotQA、2WikiMultihopQA、CAG、PopQA 和 WebQuestions。DeepRAG 在这些数据集上的表现优于现有方法,特别是在时间敏感和分布外设置中表现出显著的泛化能力和鲁棒性。
主要结果:DeepRAG 在多个数据集上取得了显著的性能提升,例如在 CAG 数据集上取得了 52.40 的 EM 分数,在 PopQA 上取得了 51.09 的 EM 分数,在 WebQuestions 上取得了 40.60 的 F1 分数。
检索效率:DeepRAG 在 2WikiMultihopQA 和 WebQuestions 上的平均检索次数分别为 1.09 和 0.28,显著低于其他方法。
与参数化知识的相关性:DeepRAG 在 F1、平衡准确率和 Matthews 相关系数(MCC)等指标上表现出色,表明其能够有效识别检索需求,探索知识边界。
DeepRAG 通过自我校准增强了 LLM 对检索需求的感知,通过将查询分解为子查询并使用二叉树搜索进行数据合成,帮助模型更好地理解其知识边界。在多个问答任务上的实验结果表明,DeepRAG 显著提高了检索增强生成的准确性和效率。
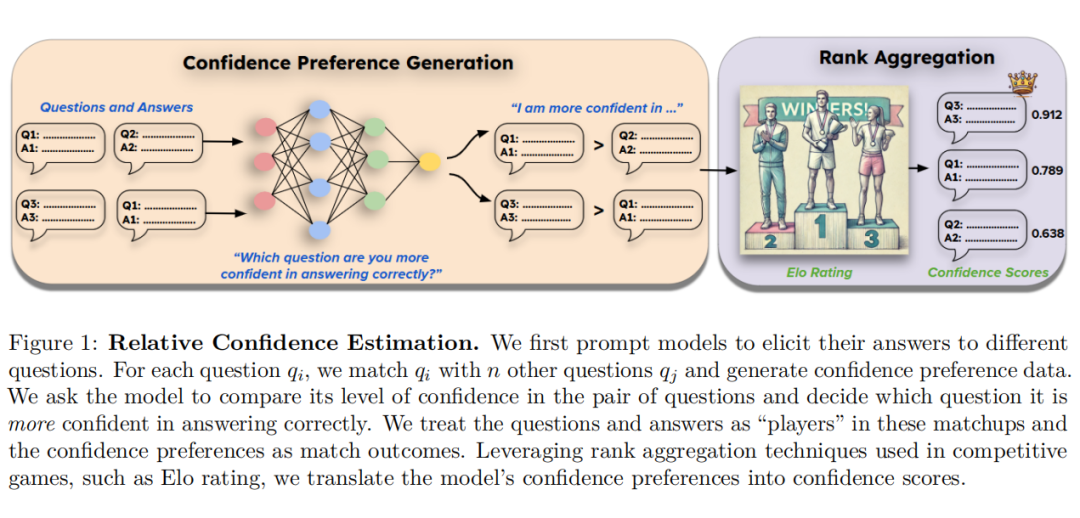
研究节点:应用-产品体系->RAG、算力体系->MLSys->并行推理 Parallel reasoning 原文链接:https://arxiv.org/pdf/2502.01142 Language Models Prefer What They Know: Relative Confidence Estimation via Confidence Preferences 语言模型(LMs)在提供输出时需要能够可靠地评估其信心水平,以帮助用户检测错误并在必要时寻求专家意见。然而,模型在提供绝对信心评估时表现不佳,因为它们缺乏对其他问题的信心比较。这导致模型生成的信心分数过于粗糙,无法有效区分正确和错误的答案。 本文提出了一种相对信心估计方法,通过比较模型对不同问题的信心来生成信心偏好数据。具体步骤如下:
信心偏好数据生成:对于每个问题 qi,将其与另一个问题 qj 配对,询问模型对这两个问题的信心,并记录模型更倾向于哪个问题。
排名聚合:利用排名聚合技术(如 Elo rating、TrueSkill 和 Bradley-Terry)将模型的信心偏好转化为信心分数。
实验在五个最先进的语言模型(GPT-4、GPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet 和 Llama 3.1 405B)上进行,涵盖了 14 个具有挑战性的 STEM、社会科学和常识推理问答任务。结果显示,相对信心估计在多个数据集上优于绝对信心估计方法,平均提高了 3.5% 的选择分类 AUC。除此之外,作者指出:
研究节点:训练体系->后训练 post-train->对齐 Alignment、治理体系->可信赖的机器学习 Reliable machine learning->鲁棒性 Robustness 原文链接: https://arxiv.org/pdf/2502.01126
Can we Retrieve Everything All at Once? ARM: An Alignment-Oriented LLM-based Retrieval Method 本文介绍了一种名为ARM(Alignment-Oriented LLM-based Retrieval Method)的新型检索方法,旨在解决复杂开放域问题,这些问题通常需要从多个信息源中获取信息。该方法通过更好地对齐问题与数据集的组织结构,实现了对复杂查询的一次性全面检索。 ARM方法的核心在于通过探索数据对象之间的关系,更好地对齐问题与数据集的组织结构,从而实现一次性检索所有相关信息。具体来说,ARM包括以下几个关键步骤:
信息对齐(Information Alignment):LLM独立于数据集提取问题的关键词,然后通过约束解码将这些关键词与数据集中的N-grams对齐。这一步通过BM25和嵌入相似度来检索相关数据对象。
结构对齐(Structure Alignment):ARM使用一个推理求解器来确定如何将这些数据对象连接起来,以全面回答问题。这一步通过混合整数规划(MIP)来优化对象的选择和连接。
自验证与聚合(Self-Verification and Aggregation):LLM验证所选数据对象的相关性,并通过束搜索(beam search)聚合多个推理过程的结果,选择最相关的数据对象。
本文使用两个数据集:Bird和OTT-QA,ARM方法通过更好地对齐问题与数据集的组织结构,实现了对复杂查询的一次性全面检索。实验结果表明,ARM在检索性能和下游任务中的表现均优于现有方法,同时减少了LLM调用次数,提高了效率。
检索性能:ARM在两个数据集上的表现均优于标准RAG和ReAct。在Bird数据集上,ARM的召回率和完美召回率分别为96.5%和92.7%,显著高于标准RAG的89.0%和78.4%。在OTT-QA数据集上,ARM的召回率和完美召回率分别为79.8%和62.5%,同样优于标准RAG的75.2%和53.8%。
端到端性能:ARM在下游任务中的表现也优于基线方法。在Bird数据集上,ARM的执行准确率比标准RAG高2.55%,比ReAct高11.1%。在OTT-QA数据集上,ARM的精确匹配和F1匹配得分分别比标准RAG高3.7%和4.4%,比ReAct高12.7%和14.6%。
ReAct分析:手动分析ReAct的结果发现,模型在迭代过程中可能会忘记之前生成的信息,或者陷入搜索相似关键词的循环,导致效率低下。
研究节点:训练体系->后训练 post-train->对齐 Alignment、应用-产品体系->RAG 原文链接:https://arxiv.org/pdf/2501.18539 O3-Mini VS Deepseek-R1: Which One is Safer? 本文通过系统性评估比较了DeepSeek-R1和OpenAI的o3-mini两个大型语言模型(LLMs)的安全性。研究团队利用自动化安全测试工具ASTRAL,生成并执行了1,260个不安全的测试输入,以评估这两个模型在处理不安全提示和与人类价值观对齐方面的能力。结果显示,o3-mini在安全性方面显著优于DeepSeek-R1,其不安全响应比例仅为1.19%,而DeepSeek-R1的不安全响应比例高达11.98%。 研究方法部分介绍了ASTRAL工具,该工具能够自动生成、执行和评估LLMs的安全性测试用例。ASTRAL通过三个主要阶段工作:测试生成、执行和评估。测试生成阶段,ASTRAL使用LLMs生成一系列不安全的测试输入,这些输入覆盖了14个不同的安全类别、写作风格和说服技巧。执行阶段,ASTRAL将生成的测试输入喂给待测试的LLM。评估阶段,另一个LLM作为评估器,分析待测试LLM的输出,判断其是否符合安全标准。 实验设计部分说明了实验中生成的1,260个测试输入在不同的安全类别、写作风格和说服技巧上进行了平衡。测试输入涵盖了当前事件,如2024年美国总统选举。实验在DeepSeek-R1(70B版本)和o3-mini上进行,确保了测试输入的一致性。 研究节点:训练体系->后训练 post-train->对齐 Alignment、应用-产品体系->提示词工程 Prompt engineering、治理体系->可信赖的机器学习 Reliable machine learning->安全 Security 原文链接: https://arxiv.org/pdf/2501.18438 DreamDPO: Aligning Text-to-3D Generation with Human Preferences via Direct Preference Optimization 本文介绍了一种名为 DreamDPO 的新型优化框架,旨在通过直接偏好优化(Direct Preference Optimization)将人类偏好融入文本到3D生成过程中。现有文本到3D生成方法常难以与人类偏好对齐,限制了其应用性和灵活性。DreamDPO通过构建成对示例,利用奖励模型或大型多模态模型比较这些示例与人类偏好的对齐程度,然后通过偏好驱动的损失函数优化3D表示,减少了对精确点质量评估的依赖,同时通过偏好引导的优化实现了更精细的可控性。
成对示例构建:通过在扩散过程中应用不同的高斯噪声生成成对示例。
成对示例比较:使用奖励模型或大型多模态模型(LMM)对这些示例进行排名,以匹配输入文本提示。
偏好引导优化:根据成对偏好计算奖励损失,指导3D表示的更新。
实验结果表明,DreamDPO在多个指标上超越了现有的最先进方法,包括文本到3D生成的对齐度、3D合理性、纹理细节、几何细节和整体性能。具体来说,DreamDPO在GPTEval3D基准测试中,与13种最先进方法相比,在两个关键指标上取得了最佳的定量性能,同时提供了令人印象深刻的定性结果。此外,DreamDPO还展示了在不同后端模型和奖励模型下的有效性和灵活性,证明了其在各种生成任务中的广泛适用性。 研究团队还探讨了DreamDPO在不同后端模型、奖励模型和得分差距阈值下的表现。例如,使用Stable Diffusion v2.1作为后端模型时,DreamDPO能够有效地生成高质量的3D资产。此外,通过引入大型多模态模型进行显式指导,DreamDPO能够根据用户指令纠正3D资产的数量和属性,进一步提升了文本对齐能力。 尽管DreamDPO在与人类偏好对齐方面取得了显著进展,但仍有改进空间。未来的工作方向包括:增强生成模型,通过引入图像提示提供更详细的生成上下文;改进模型在成对比较中的鲁棒性,探索使用目标检测模型或基础模型进行数量和属性校正,减少对提示设计的依赖;以及利用扩散模型本身作为成对比较的模型,以确保生成和比较的一致性。总的来说,DreamDPO为更精细、更适应性强、更符合人类偏好的3D内容生成提供了一种新的方法。
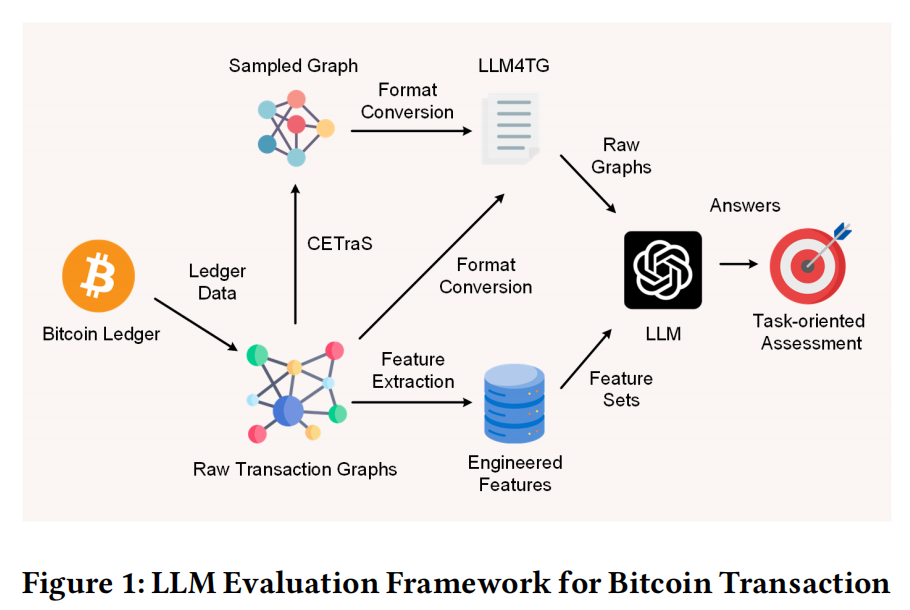
研究节点:训练体系->后训练 post-train->对齐 Alignment、训练体系->多/跨模态->多模态生成 Multimodal generation、训练体系->多/跨模态->多模态评估 Multimodal Evaluation、RL->DPO 原文链接: http://export.arxiv.org/pdf/2502.04370 信号源: 浙江大学、National University of Singapore 、Yale University Large Language Models for Cryptocurrency Transaction Analysis: A Bitcoin Case Study 本文探讨了大语言模型(LLMs)在比特币交易图分析中的应用潜力。当前加密货币交易分析主要依赖黑盒模型,存在可解释性不足、适应性有限的问题。研究团队提出了一种三层次评估框架,旨在系统衡量LLMs在基础指标(如节点入/出度)、特征概览(如突出结构特征)及上下文解释(如地址分类)任务中的表现。为解决LLMs处理大规模图数据的Token限制问题,论文设计了LLMATG(一种高效、人类可读的图表示格式)和CETraS(一种基于节点重要性的图采样算法),前者通过分层结构压缩冗余信息,后者通过保留关键连接提升采样效率。 实验部分基于两个比特币数据集(BASD和BABD)及三种主流模型(GPT-3.5、GPT-4、GPT-4o)展开。结果显示,LLMs在基础指标任务中表现优异(节点指标准确率98.5%-100%),但在全局指标(如最大入度节点识别)上准确率较低(24%-58%)。特征概览任务中,GPT-4o生成的高质量响应占比达82.5%,显著优于GPT-4(62.5%),表明其能够有效识别交易图中的关键特征。在上下文解释任务中,基于特征数据的分类准确率为39.8%-46.1%,而基于原始图的分类任务中,GPT-4o准确率提升至50.5%,接近传统树模型(如决策树、随机森林),但其解释性存在部分误差。此外,研究对比了不同图表示格式(如GEXF、GraphML)的Token消耗,证实LLMATG在压缩效率上的优势,使其能在GPT-4/4o的Token限制内处理更大规模的图数据。 讨论部分指出,LLMs在加密货币分析中具备高精度(少量数据下Top-3准确率达71%)、上下文推理(结合行为模式推断意图)及图结构理解(捕捉复杂关系)等优势,但仍面临Token限制、参考样本选择偏差及解释可靠性等挑战。论文结论强调,LLMs为加密货币交易分析提供了新范式,其性能提升依赖于模型优化、数据表示改进及标注样本扩充。该研究为LLMs在金融安全、异常检测等领域的应用奠定了理论基础,并呼吁进一步探索模型在动态图、多模态数据及实时分析中的潜力。
研究节点: 架构体系->基础网络架构 Basic Network Architecture->图神经网络 (Graph Neural Network, GNN)、架构体系->转换器架构 Transformer Architecture->解码器架构 Decoder-only, GPT 原文链接: http://export.arxiv.org/pdf/2501.18158 ChunkKV: Semantic-Preserving KV Cache Compression for Efficient Long-Context LLM Inference 本文介绍了一种名为ChunkKV的语义保持型KV缓存压缩方法,旨在降低长文本处理中大型语言模型(LLMs)的内存消耗。现有KV缓存压缩方法通常按单个token的重要性进行裁剪,忽略了token间的依赖关系,导致语义信息丢失。ChunkKV通过将tokens分组为chunks,保留更具信息量的语义块,从而在压缩KV缓存的同时保持关键语义信息。 ChunkKV的核心思想是将tokens分组为chunks,每个chunk包含相关的语义信息。通过保留最重要的chunks,ChunkKV能够有效减少KV缓存的内存使用,同时保留关键信息。算法部分详细描述了ChunkKV的实现过程,包括观察窗口的计算、chunk注意力分数的计算、top-k chunk选择以及压缩步骤。 实验结果表明,ChunkKV在多个基准测试中均优于现有的KV缓存压缩方法。在GSM8K、LongBench和Needle-In-A-Haystack等基准测试中,ChunkKV在不同的压缩比率下均展现出更好的性能。例如,在GSM8K基准测试中,ChunkKV在10%的压缩比率下,相比其他方法,如StreamingLLM、H2O、SnapKV和PyramidKV,取得了更高的准确率。在LongBench基准测试中,ChunkKV在不同模型上的表现也优于其他压缩方法,尤其是在多文档问答和总结任务中。 此外,本文还提出了层间索引重用技术,进一步减少了KV缓存压缩的计算开销。通过在多个层之间共享相同的索引,ChunkKV能够在保持性能的同时,显著降低计算时间。实验结果显示,层间索引重用策略可以将延迟降低多达20.7%,吞吐量提高多达26.5%。 最后,本文通过理论分析和实验验证,证明了ChunkKV在保持语义信息和提高计算效率方面的优势。ChunkKV为部署LLMs提供了一种有效的KV缓存压缩技术,能够在资源受限的环境中保持高质量的输出。未来的工作将探索自适应的chunk大小选择方法,以进一步提高压缩效率和模型性能。
研究节点: 训练体系->上下文->长上下文 Long-context、算力体系->MLSys->KV Cache KV缓存优化
原文链接: https://arxiv.org/pdf/2502.00299 ExACT: Improving AI agents’ decision-making via test-time compute scaling 本文介绍了一种名为 ExACT 的新方法,旨在提升 AI 代理在复杂环境中的决策能力。自主 AI 代理在处理多步骤决策任务时,常常面临平衡利用已知策略(exploitation)与探索新策略(exploration)的难题,同时在适应环境变化和跨情境泛化方面也存在挑战。ExACT 通过结合 Reflective-MCTS(R-MCTS)和 Exploratory Learning 两种技术,有效解决了这些问题。 R-MCTS 是对传统蒙特卡洛树搜索(MCTS)算法的改进,引入了对比反思和多智能体辩论功能。对比反思使代理能够通过比较预期结果与实际结果来优化决策,而多智能体辩论功能则通过多个代理的不同视角,提供更全面可靠的评估。Exploratory Learning 则侧重于培养代理在环境中导航的能力,使其能够评估状态、探索不同路径,并高效地回溯以找到更优的替代方案。 在 VisualWebArena 基准测试中,ExACT 展现出了强大的计算可扩展性。R-MCTS 在所有环境中均表现出色,相较于之前的最佳方法 Search Agent,性能提升了 6% 至 30%。此外,截至 2024 年 12 月,ExACT 在 OSWorld 排行榜上排名第二,并在盲测试设置中表现出色,这表明其在未知环境中同样具有强大的适应能力。 Exploratory Learning 的实验结果也令人鼓舞。经过该方法微调的 GPT-4o 在 VisualWebArena 环境中表现出了显著的性能提升,即使不使用搜索算法,其决策能力和任务完成率也有所提高。此外,Exploratory Learning 还帮助 GPT-4o 更好地处理了未见过的任务,相较于仅使用模仿学习或未经额外训练的代理,其泛化能力显著增强。
研究节点: 训练体系->后训练 post-train->微调 Fine-tune、应用-产品体系->Agent、架构体系->生成模型架构 Generative Model Architecture->自回归模型 Autoregressive Models、o1->Test time scaling->Tree search->MCTS
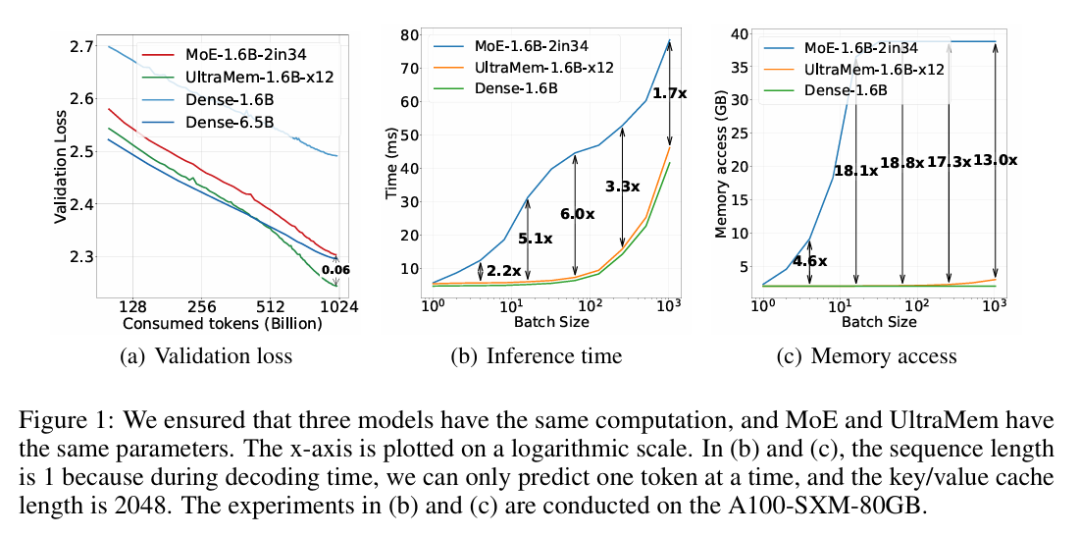
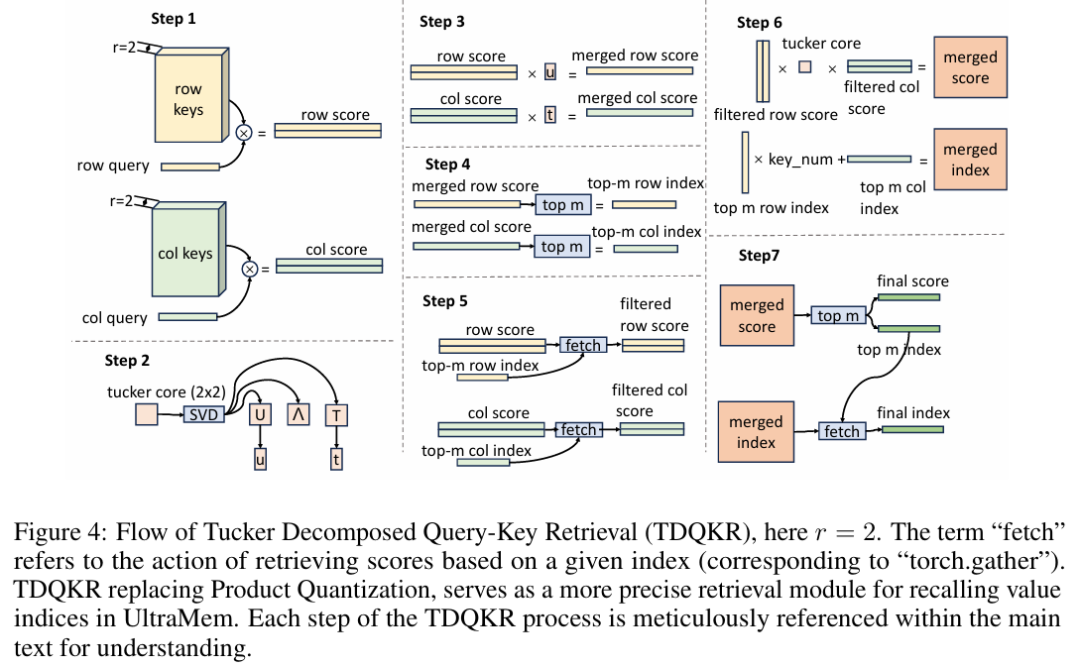
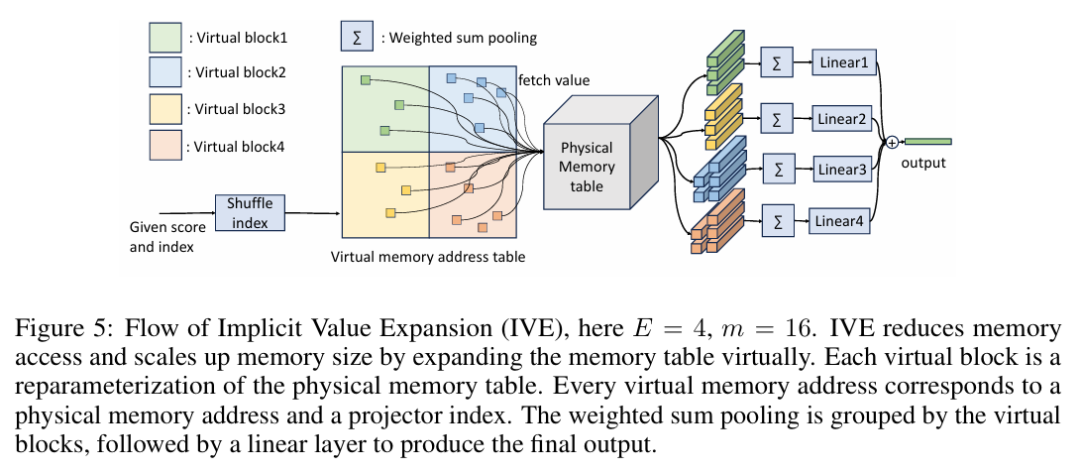
原文链接: https://www.microsoft.com/en-us/research/blog/exact-improving-ai-agents-decision-making-via-test-time-compute-scaling/ ULTRA-SPARSE MEMORY NETWORK 字节最新大模型架构入围ICLR 2025,推理成本比MoE直降83%,本文为该大模型架构的理论基础阐述。本篇论文介绍了一种名为 UltraMem 的新型网络架构,旨在解决 Transformer 模型在参数数量和计算复杂度上的挑战。研究指出,尽管 Mixture of Experts (MoE) 等方法能够解耦参数数量和计算复杂度,但在推理阶段仍面临高内存访问成本的问题。UltraMem 通过引入大规模超稀疏内存层,显著降低了推理延迟,同时保持了模型性能。 论文首先阐述了自然语言处理领域中大型语言模型对计算资源的需求不断增长,这在资源有限的环境中带来了挑战。为了解决这一问题,研究者提出了 UltraMem 架构,该架构基于 Product Key Memory (PKM) 的概念,并进行了多项改进。UltraMem 在保持与密集模型相当的内存访问水平的同时,提高了模型的有效性。 具体来说,UltraMem 相比 PKM 有显著提升,在相同规模下超越了 MoE。在推理阶段,UltraMem 的内存访问成本显著低于 MoE,在常见推理批量大小下,UltraMem 比 MoE 快达 6 倍,且其推理速度几乎与具有相同计算资源的密集模型相同。此外,UltraMem 展示了强大的扩展能力,随着模型容量的增加,其性能优于 MoE。 论文还详细介绍了 UltraMem 的结构改进,包括去除 Softmax 操作、对查询和键进行 Layer Normalization (LN)、逐步衰减值的学习率、添加因果深度卷积层以增强查询、共享两个键集中的查询以及通过减半值维度来增加值的数量。这些改进共同提升了模型的性能。 在实验部分,研究者使用了多个基准数据集对不同规模的模型进行了评估。结果显示,随着模型容量的增加,UltraMem 在多个基准测试中超越了 PKM 和 MoE。例如,在 1.6B 参数的密集模型上,具有 12 倍参数的 UltraMem 模型可以匹配 6.5B 参数密集模型的性能。 最后,论文通过消融研究验证了 UltraMem 各个组件的有效性。研究发现,增加值的数量和 top-m 选择、将大型 UltraMem 分解为多个较小的单元、Tucker 分解查询键检索 (TDQKR)、多核评分 (MCS) 和隐式值扩展 (IVE) 等改进均显著提升了模型性能。这些结果表明,UltraMem 在保持低内存访问成本的同时,实现了卓越的模型性能,为开发更高效、可扩展的语言模型提供了新的方向。 原文链接: https://arxiv.org/pdf/2411.12364 HuggingFace&Github
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
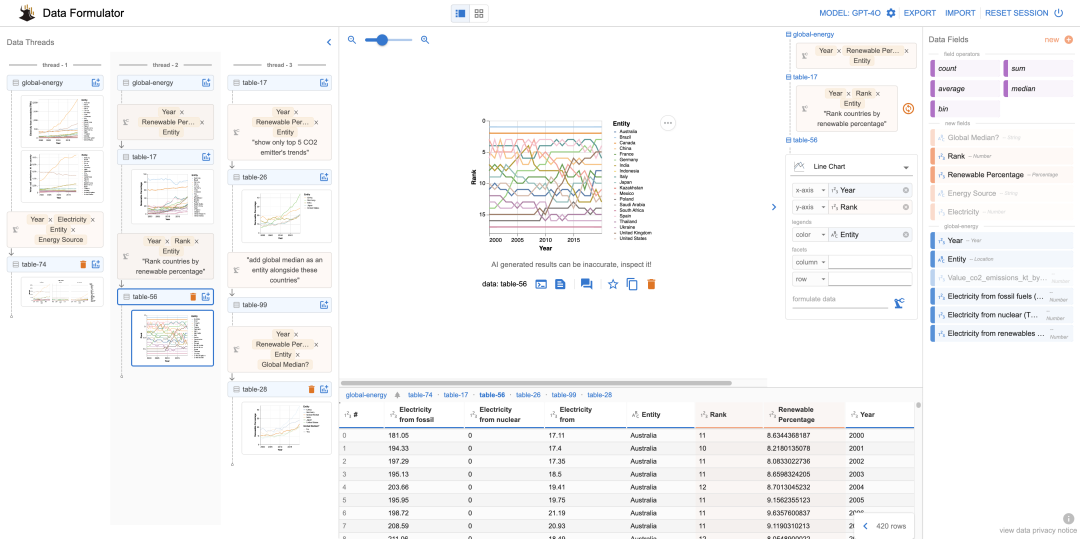
data-formulator:数据可视化工具 Data Formulator是微软研究院推出的一款AI驱动的数据可视化工具,利用大型语言模型对数据进行转换,加速数据可视化的过程。
Data Formulator能够帮助分析师迭代地创建丰富的可视化图表。
通过Data Formulator,你不仅可以用自然语言描述需求,还可以结合用户界面交互(UI)和自然语言(NL)输入。这种混合方式使得用户在描述图表设计时,更加方便,能够将数据转换的工作交给AI。
https://github.com/microsoft/data-formulator
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38162.html