
MOLAR NEWS
2020年第20期
MolarData人工智能每周见闻分享,每周一更新。
前沿丨智能海滩、泳池来了!AI溺水防护系统实时跟踪、风险预测、自动警报
如今,人工智能(AI)在生活中的应用场景可谓百变多样。从医学诊断、图像识别、无人驾驶到个人助理、教育辅助,AI 的对现代生活的重要性不言而喻。然而,除了以上场景,AI 还可以应用于安全防护方面。这不,眼看着炎炎夏日来临,人们纷纷涌向游泳馆、海滩等消暑胜地,渴望在灼热温度中寻求一丝“透心凉”的快感。但人生就是这样,你永远不知道明天和意外哪一个先来。尤其在热浪滚滚的夏日,游泳溺亡的意外事故层出不穷。根据世界卫生组织(WHO)的数据,溺水是造成全球人口意外死亡的第三大原因,全球每年估计有 320,000 人因溺水而死亡。但现在,有了 AI 的帮助,溺水事故率很可能得到大幅降低。近日,以色列内盖夫本古里安大学(BGU)的衍生企业 Sightbit,就针对频发的溺水事故,开发出一套 AI 溺水防护系统,该系统可以实时监测所有游泳者,并标记出潜在的危险情况,以弥补救生员肉眼观察的不足。


Sightbit 的系统包含多组摄像头,这些摄像头并非普通相机,而是加持了基于深度学习和计算机视觉技术的软件。增强后的多组摄像头更加灵敏,能够清晰地显示出摄像范围内的所有物体。而且,这种摄像机的摄像范围也大大提高,单个摄像机可以伸展到大约 1000 英尺(300 米)的海岸线。要知道,通常需要三个普通摄像机才能覆盖到该范围。

此外,Sightbit 的系统具有用于目标检测的卷积神经网络。这种神经网络常用于 AI 识别,我们可以将其视为一种深度学习的特征抽取器。经过大量的目标特征培训,该神经网络就可以总结出特定的物体特征并建立相应的模型,并以此方式进行人脸识别、通用物体识别、运动分析、自然语言处理甚至脑电波分析。因此,在接受“成千上万张照片”的培训后,这一 AI 溺水防护系统就可以从摄像头采集到的视野中准确识别出每位游泳者,并监控他们的状态。

系统准确识别并监控游泳者最后,该系统使用风险评估模型对海滩的各个部分进行评估,该模型考虑了拥挤程度和天气状况,然后估算在一天中可能需要多少个救生员。一旦发现似乎正在挣扎的游泳者,系统就会发出实时警报。该系统还会对可能出现危险情况的游泳者(例如无人看管的小孩)进行预测分析,这可以帮助救生员预测风险并提前采取预防措施。对救生员来说,监视器会显示海滩的全景,类似于安全摄像机的视野,并且在单个屏幕上可以使用多个视图。还可以显示其他数据,例如人数,天气状况以及是否有激流。每个救生员都可以控制他们想看到的警报和危险。Sightbit 联合创始人兼首席执行官 Netanel Eliav 说:“一旦系统监测到某位游泳者有危险,ta 对应的框就会不断闪烁。救生员可以单击警报,放大,以准确查看警报的位置。系统还可以跟踪遇险游泳者的位置,必要时,我们可以通过小型无人机实施救援。”

目前,Sightbit 已经在以色列的 Palmachim 海滩启动了第一个商业试验计划,推出该软件系统的订阅服务,按月收费,还会负责海滩现场的软件配置。今年夏季,Palmachim 海滩累计已有超过一百万的游客。目前此处的 Sightbit 正供 5 名救生员一起使用。安装的第一阶段于上个月启动,覆盖了 400 米(1312 英尺)的海滩,而第二阶段计划将再覆盖 400 米。Sightbit 系统可以从根本上改变救生方法,将海滩望塔和双筒望远镜替换为屏幕和自动警报。但是,该公司并未将其服务作为人类救生员的替代品,他们更多的是改善当前的人工方法,为指挥中心的救生员提供辅助,使他们可以继续用肉眼监视,同时在屏幕上出现警报时做出响应。
Eliav 解释说:“我们正在从测试界面方面检验救生员如何使用该系统,并考虑如何将系统集成到救生员的日常实践中。系统将能够以 99.9% 的准确度检测各类危险情况。”实际上,世界各地正在进行许多类似的“智能海滩”倡议。例如澳大利亚的“智能海滩”项目,该项目部署了多组传感器来统计游客人数并发现危险情况;瑞典的 SwimEye 公司和以色列的 Coral Detection Systems 公司,他们也已建立计算机视觉系统,将摄像头置于游泳池水下,或提供类似产品。尽管这些智能海滩系统的准确性和可靠性还需要更多的实践来检验,但是不得不说,此类 AI 安全防护系统确实能够帮助人们及早发现可能导致溺水的危险情况,避免许多悲剧的发生。最后,夏日来临,希望读者们外出注意自身安全,游泳千万条,安全第一条。
来源:中国人工智能学会
近千亿数据集下线,MIT道歉,ImageNet亦或遭殃
麻省理工学院(MIT)已永久删除包含8000万张图像的Tiny Images数据集。此举是论文《Large image datasets: A pyrrhic win for computer vision?》中的发现导致的结果。论文作者在数据集中发现了许多有危害类别,包括种族歧视和性别歧视。这是依赖WordNet名词来确定可能的类别而没有检查图像标签带来的结果。他们还确定ImageNet中也有类似的问题,包括非自愿的色情材料等。在The Register向MIT发出警示之后,该数据集已于本周删除。MIT还敦促研究人员和开发人员停止使用该数据集,并删除任何副本。CSAIL的电气工程和计算机科学教授Antonio Torralba表示:“实验室根本不知道这些令人反感的图像和标签存在于数据集中。”他告诉The Register:“很明显,我们应该手动筛选它们。为此,我们深表歉意。”由于MIT在采集数据集时使用不当的方法,这些系统可能将女性标记为“ji女”或“biao子”,而对黑人和亚裔的描述则带有贬义。该数据库还包含标有“cunt”的女性生殖器特写图片,此外还包括带有“nigger”(黑鬼)标记的黑人和猴子的图片,穿着比基尼或抱着孩子的妇女,被贴上“ji女”的标签,将日常图像与诽谤、令人反感的语言联系起来,并把偏见引入AI模型。
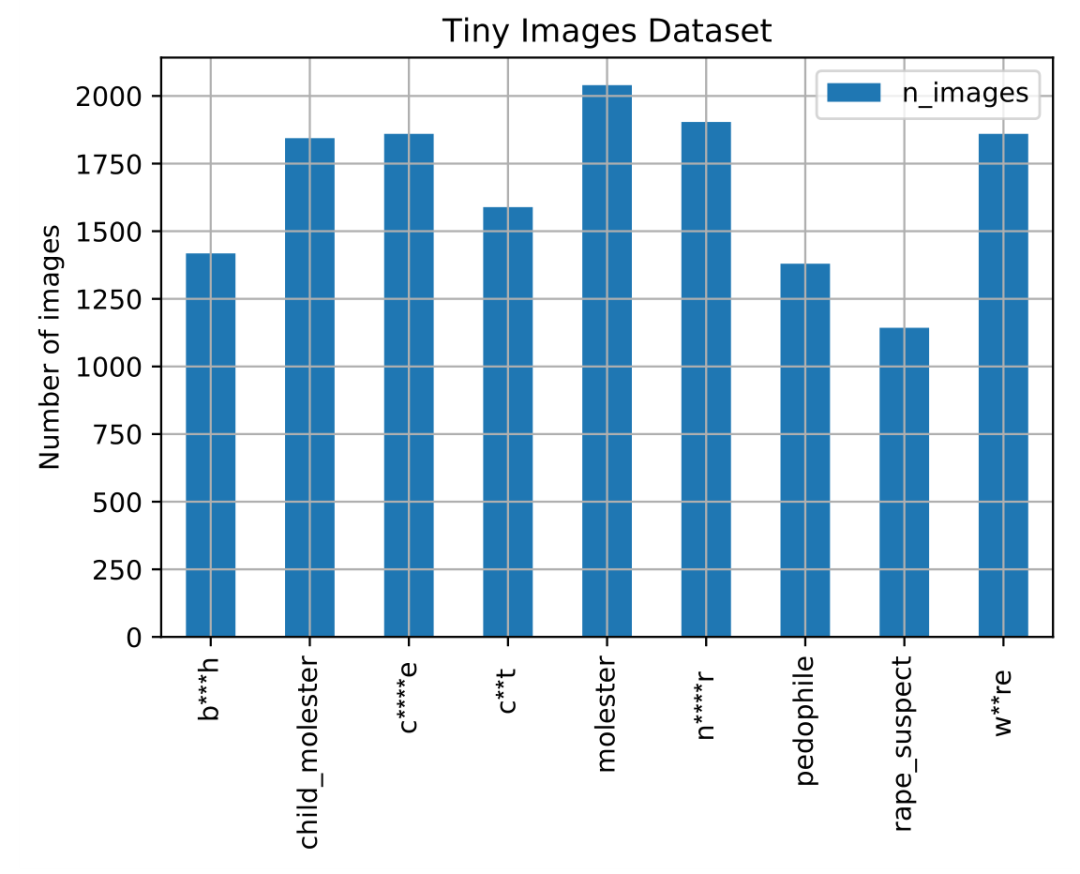

Tiny Images数据集可视化下线之前的屏幕快照。它展示了标签“ji女”的数据集示例,出于法律原因,已将其像素化。图片包括母亲抱着婴儿的照片、圣诞老人的爆头照片、色情女演员和穿着比基尼的女人的照片。如今,Tiny Images数据集与更知名的ImageNet数据集都成为了评估计算机视觉算法的基准。但是,与ImageNet不同,到目前为止,还没有人检查过Tiny Images中有问题的内容。ImageNet也存在相同的问题,因为它也使用WordNet进行了标记。名为ImageNet Roulette的实验让人们将照片提交到ImageNet训练的神经网络,一些人上传了自拍照,但是当软件使用种族主义和冒犯性标签描述他们时,他们感到震惊。在这些庞大的数据集中,有问题的图像和标签所占的比例很小,很容易将它们当作异常现象而忽视掉。这部分数据集在AI训练过程中通常不能得到均衡的分配。这就是面部识别算法难以识别女性和肤色较深的人的原因。底特律的一个黑人在今年早些时候被面部识别软件误认为是可疑小偷后,被警察误捕。近期颇有争议的图像翻译算法PULSE则将奥巴马的模糊照片变成了白种人。
Torralba教授介绍了Tiny Images数据集的构建方式:获得大量单词(包括贬义词),然后编写代码以使用这些单词在网络上搜索图像并将其结合在一起。Torralba教授说:“数据集包含直接从WordNet复制的53,464个不同名词”然后,这些数据被用来从互联网搜索引擎自动下载相应名词的图像,最后使用当时可用的过滤器来收集8000万张图片。”WordNet于1980年代中期在普林斯顿认知科学实验室建立,由George Armitage Miller创立,他是认知心理学的创始人之一。“ Miller着迷于单词之间的关系,Prabhu说:“数据库本质上反映了单词如何相互关联。”例如,“猫”和“狗”比“猫”和“伞”更紧密相关。不幸的是,WordNet中的某些名词是种族歧视的和侮辱性的。几十年后的今天,这些术语困扰着现代机器学习。“在构建庞大的数据集时,需要某种结构,” Birhane说:“这就是WordNet有效的原因。它为计算机视觉研究人员提供了一种对图像进行分类和标记的方法。当可以使用WordNet时,为什么要自己手动做呢?”
回到这件事的起因上,该论文的两位作者是来自硅谷一家隐私初创公司UnifyID的首席科学家Vinay Prabhu和爱尔兰都柏林大学的博士学位候选人Abeba Birhane,他们在研究了MIT数据库之后发现了成千上万张带有针对黑人和亚洲人的种族主义诽谤和用于描述女性的贬义词标签的图像。之后他们以ImageNet-ILSVRC-2012数据集为例做了一些研究并发表了本篇论文。作者调查了由于不严格且考虑不周的数据集管理做法而导致的整个社会以及个人所面临的危害和威胁的情况,并且提出可能的纠正方法,并批评这些方法的利弊。作者适当开源了在此努力中生成的所有代码和普查元数据集,以使计算机视觉社区得以建立。通过揭露威胁的严重性,作者希望激发大型数据集管理流程的强制性机构审查委员会(IRB)的组成。作者认为在大数据时代,个人知情同意、隐私权或代理权的基本原则已逐渐被侵蚀。机构、学术界和工业界,在未经同意的情况下收集了数以百万计的人的图像。如表1所示,在同行评议的文献中发现了数以千万计的人物形象。这些图片是在未经个人同意或知情的情况下获得的,也未经IRB批准收集。

作者对ImageNet数据集进行了批判:ImageNet数据集的出现被广泛认为是深度学习革命中的一个关键时刻,它改变了计算机视觉和人工智能。从图像的可疑方式的来源,到图像中人物的标记,再到使用这些图像训练人工智能模型的下游效果,ImageNet和大规模视觉数据集(LSVD)总体上构成了计算机视觉的一个代价高昂的胜利。这场胜利是以伤害少数群体为代价的,并进一步助长了对个人和集体的隐私和知情权的逐渐侵蚀。当更广泛的计算机视觉社区缺乏对ImageNet数据集的审查,这只会鼓励学术和商业机构在没有审查的情况下建立更大的数据集。随之作者又进行了一些反思:大型图像数据集,如果没有仔细考虑社会影响,就会对个人的福利和福利构成威胁。允许人脸搜索的反向图像搜索引擎在过去的一年里取得了显著而令人担忧的效率。只需支付少量费用,任何人都可以使用他们的门户或API来运行一个自动化程序以发现ImageNet数据集中人类的“真实”身份。例如,在性工作受到社会谴责或法律定罪的社会中,通过图像搜索重新识别性工作者,对受害者个人来说确实是一种危险。说到这里我们额外提一句,以上事情在中国也切切实实的正在发生着,国内某家搜索引擎巨头的老板曾在前年中国发展高层论坛现场就人们关心的数据和隐私问题谈到:“中国人更加开放,对隐私问题没有那么敏感,如果他们可以用隐私交换便捷性,很多情况下他们是愿意的。”哦,怪不得他之后在自家公司的大会上被人泼了”宏颜祸水”,另外这家公司出品的“百毒”识图相信大家也都用过。最后作者给了一些解决方案建议:
1、合成真实和数据集蒸馏这里的基本思想是在模型训练期间使用(或增强)合成图像来代替真实图像。方法包括使用手绘草图图像(imagenet sketch),使用GAN生成的图像和数据集蒸馏等技术,其中一个数据集或一个数据集的子集被提炼成几个具有代表性的合成样本。这是一个新兴的领域,在跨视觉域的无监督域适应和通用数字分类方面有一些有希望的结果。
2、对数据集强化伦理过滤
3、定量数据集审计:以ImageNet为模板
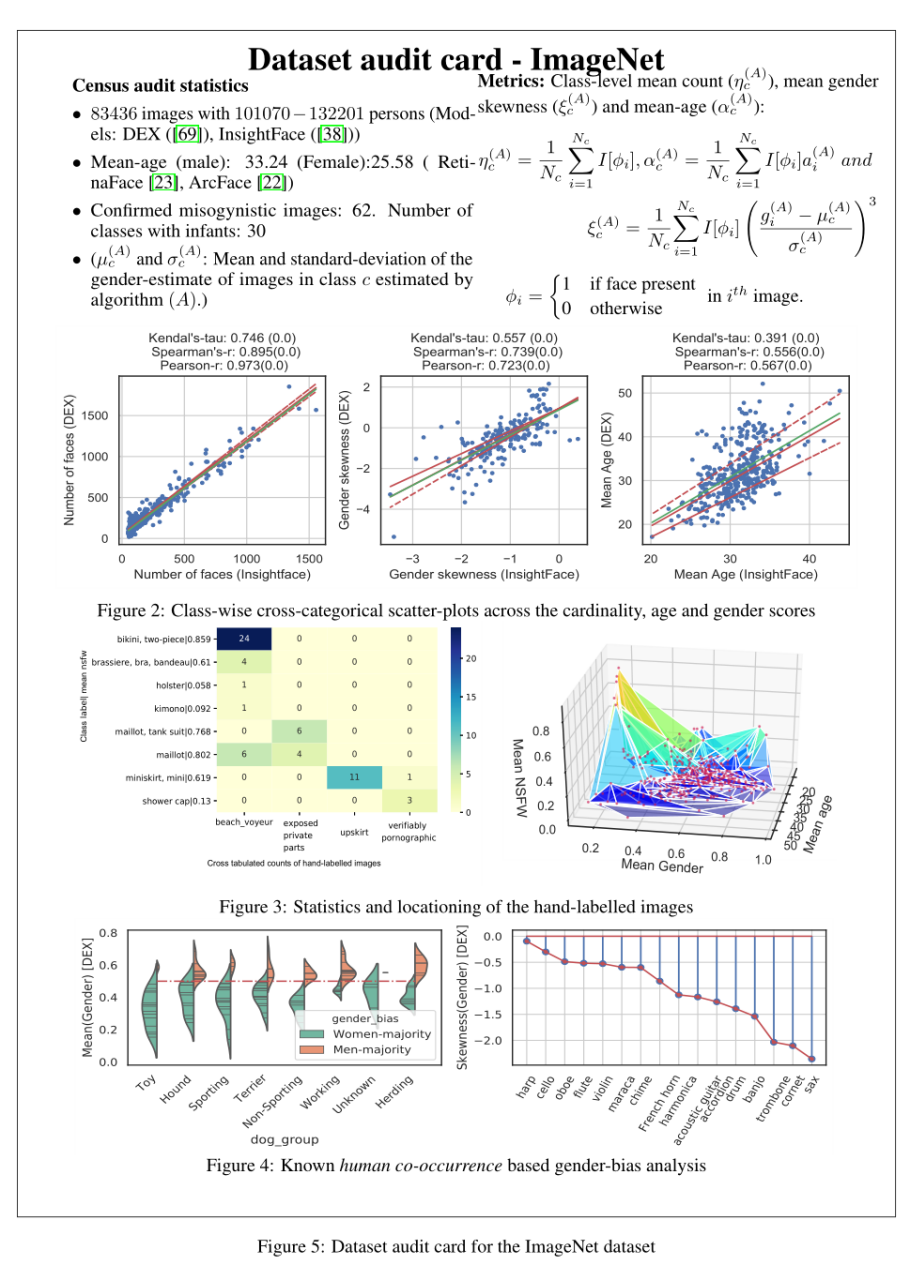
作者对ImageNet进行了跨范畴的定量分析,以评估道德违规的程度和基于模型注释的方法的可行性。这导致了ImageNet普查,需要对57个不同指标进行图像级和类级分析,这些指标包括计数、年龄和性别(CAG)、NSFW评分、类别标签的语义和使用预先训练的模型分类的准确性。
作者试图引起机器学习界对大规模数据集的社会和伦理影响的关注,例如非一致同意的图像问题和经常隐藏的分类问题一直被认为是计算机视觉和人工智能领域最令人难以置信的突破之一。ImageNet的成就确实值得庆祝,并且创造者们为解决一些伦理问题所做的努力也值得认可。尽管如此,ImageNet以及其他大型图像数据集仍然很麻烦。持续的沉默只会在将来造成更多的伤害而不是带来好处。在这方面,作者概述了一些解决办法,包括审计卡,可以考虑改善提出的一些关切。作者还策划了元数据集,并将代码开源,以ILSVRC2012数据集为模板进行定量审计。作者敦促机器学习界密切关注他们的工作对社会,特别是对弱势群体的直接和间接影响。在这方面,必须意识到当前工作的历史前因、背景和政治层面。作者希望这项工作有助于提高人们的意识,并为继续讨论机器学习中的伦理和正义提供帮助。
1、副本无处不在即便MIT主动下线了Tiny Images数据集,但是数据副本无处不在。很多用户都下载过这些副本到本地,如何保证这些副本不会被再次上传到网络呢?在reddit上有网友表示知道该数据集的副本地址。
2、人工智能鉴黄系统的工作还能继续吗?如果想要训练一个人工智能鉴黄系统,那么必须要先人为的制作数据集也就是要对一些图片打上标签说这是色情图片。问题是这些图片从何而来呢?如果是用爬虫程序从色情网站上收集,那么怎么保证这些图片当中哪些能用呢?比方说有些无辜受害的情侣被偷拍的照片被不法分子上传到色情网站,然后爬虫程序又把它们下载下来,我们难道可以哪怕是为了开发鉴黄系统而理所当然的使用这样照片吗?这难道不是对无辜受害者的隐私再一次侵犯吗?另外如果说收集的是色情从业者(他们的国家合法化这项职业)的视频和图片,那TA们的肖像权就不值得尊重和保护了?所以说一旦考虑到要严格遵守隐私权和肖像权,人工智能鉴黄系统就难以为继。3、利用人工智能程序自动判断种族、性别等歧视是个矛盾因为如果我们要考虑制造一个AI系统来自动帮助我们判别某些图片是不是存在某种歧视,那么我们同样需要收集和利用这些有歧视的图片,可是在得不到本人允许的情况下我们又何以冠冕堂皇的利用这些图片来做成“典型”来告诉人工智能说:嗨AI,快看!这个就是XX歧视的图片,你可得“记住”哈!那就让我们“愉快”地抛弃人工智障回到农耕(手工)时代吧!可是,难道个人或者企业私自收集并利用这些包含隐私/歧视的数据就合法了吗?所以,如何建立一个公开的征得当事人同意的令公众信服的数据集就成为了当前和未来的一大难点。
来源:AI科技评论
「云毕业照」刷爆朋友圈!AI人脸融合技术谁家强?
2020,特殊的毕业季,需要特殊的纪念。
之前看过日本东京的BBT大学使用的「Newme」机器人代替学生参加毕业典礼,就问能不能来点儿阳间的东西?
AI才有的仪式感:大家一起云毕业!
没有学士服,没有毕业典礼,也没有了毕业旅行,不过我们还有美美的自己呀。

这个人生的特殊节点还是需要一些仪式感,好在有AI技术可以帮助大家拍「云毕业照」。在每一个值得纪念的校园「隐秘的角落」,为心爱的TA「拍一张照」。

就算秃了也不怕,还有AI帮你修复,还你一个白衣飘飘,明眸皓齿的俊逸少年。

科研十年寒窗苦,一朝成名头已秃 还可以实现性转,微表情也随之变化,细节逼真。

最近,腾讯云推出了一款名叫「云毕业照」的服务,基于腾讯优图的人脸识别算法,采用了人脸融合、人像/人体分割、照片合成等AI视觉技术。一时间,刷爆毕业生朋友圈。 相比传统的「换脸软件」,这项服务生成的效果图更加逼真,并且测试来看,它的素材库非常大,可以提供许多的场景。甚至还可以完成性转,看一看「世界上另一个你」是什么样的。 官微中表示还可以实现多人合影,可以实现师生合影,创意合影等。但是目前试用版只有单人的。
看到效果图,有网友提出质疑:「这不就是普普通通的p图吗?我们学校的毕业照也是这么p的,3块钱一个人,p了百来块。」

但事实上,这个小程序的「云毕业照」可比p图的自然多了。p图的原理是采集你的五官和发型,但是你的眼神,表情是不能动的。如果你拍照的原图是咧嘴笑的,那么p图后的成果大概率不能变成抿嘴笑的,因为p图只是把你的五官粘贴上去而已。
「云毕业照」和僵硬的p图就不是很一样。它的原理仅仅是采集了你的五官特征,并不是把你的五官直接暴力的粘贴上去,因此上传不笑的照片也可以生成一张咧嘴笑的照片。 下面以严良同学为例,这是利用人物照生成的一张效果图。

这种技术叫做「人脸融合」。 人脸融合的核心算法是快速精准的定位五官,提取五官的特征,让用户上传的照片和特定形象进行面部层面融合,这样生成的图片既具有用户的五官特点,又呈现了原图像的外貌特征。 人脸融合其实不算特别新奇的技术,很多开源的代码能够让开发者体验到简单的人脸融合。 opencv和dlib相结合可以实现人脸融合,具体的步骤如下:1)检测面部标记;2)旋转、缩放和转换第二张图像,使之与第一张图像相适应;3)调整第二张图像的色彩平衡,使之与第一个相匹配;4)把第二张图像的特性混合在第一张图像中。

这个算法是基于一篇论文《One Millisecond Face Alignment with an Ensemble of Regression Trees》,它将人脸分为68个像素点去做标记,并利用矩阵变换去进行融合。 除此之外还有利用百度智能云里的人脸识别和Python相结合的人脸融合,就是利用智能云来做五官标记定位,然后在Python上实现融合的算法。 两张图像的融合的算法也很多,这里以利用泊松融合生成「云毕业照」为例。 泊松融合(Poisson Blending)就是图像处理界大名鼎鼎的图像融合算法,自从2003年论文Poisson Image Editing 中提出以后,有很多在此基础上进行改进的研究。 所谓泊松融合,就是把不同的图像的不同部分放在一起,形成一张新的图像。融合得越自然,算法就越好。如同下图的苹果橘子图。

定位到学士服模板中人脸的位置,然后根据人脸掩模做一个泊松融合,就能得到换脸之后的学士服照片了。 虽然这次腾讯云AI的人脸融合算法没有开源,但是算法思路大同小异,一般都是通过大量的测试让算法模型的精准性更高。看了毕业照的效果图之后可以肯定,「云毕业照」的算法还是很优秀的,毕竟相当一部分的性转图都没有让人觉得违和。 但是由于提供的素材背景库相当之多,因此不免出现一些缺陷,主要的吐槽集中在以下两点: 五官位置不可以调整 像素点标记的方式让原图层的五官位置也是固定的,但是人的五官位置因个体差异差别很大,不免出现五官分散的开或者五官挤在一起的情况,就显得相当「失真」。

以马云爸爸为例,马爸爸的五官都是个体偏大的,融合到少女的身上就有些突兀感,感觉撑满了整张脸。
有的时候模板生成的照片不好看是因为个人原因,但是有的模板,所有人生成的照片都不是很好看。只能说开发者对不同造型有偏爱吧。
华为旷世抖音:换脸哪家强?再来看看抖音faceapp、旷视Face++和华为ModelArts如何实现换脸。 旷视Face++人脸融合技术功能演示是基于 Merge API 搭建的。它可以进行人脸检测、83个关键点检测与跟踪、人脸分析、1:1 人脸比对或 1:N 人脸搜索。 和IU照片合成的易洋千玺还是那么帅气。
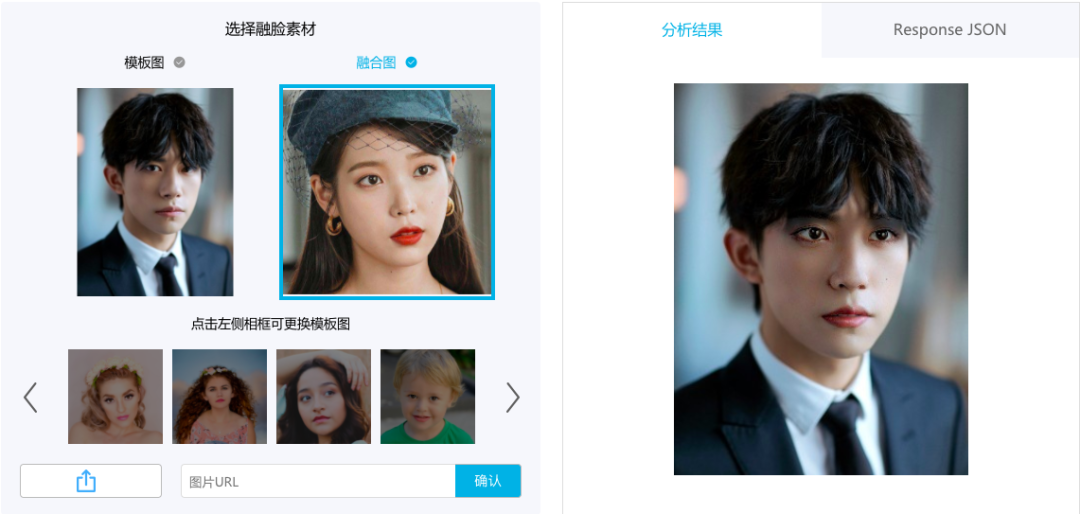
华为ModelArts目前也奉上了通过人脸融合技术提供云毕业照的实现办法。
在网站通过上传证件照,通过选择不同学科类别用户可以很轻松地实现身穿学士服的毕业照的合成。上传多张照片,还可以实现一个多人合照的生成,系统还支持背景替换。

最近在抖音上,一款特效「变身漫画」从明星到路人,堪称全民参与,就有小伙伴把自己的头像变为二次元漫画脸,又萌又酷,吸了一大波粉丝。

除了「变身漫画」,「性别反转」特效也是通过GAN来实现人脸面部特征改变,包括人物的眉眼、口鼻、头发。 帅小伙都可以立刻变成美女,女生也可以通过这个特效一秒变帅哥。
来源:新智元
因为AI不是人,美国专利局拒绝认定TA的所有发明权
「你不是人!」——美国专利局(USPTO)。
这句话是美国专利局,对所有人工智能说的。
4月27日,美国专利局出台一项规定:对于任何由人工智能独立设计发明的产品,因为AI不是自然人,所以无权申请专利成为发明者。
而AI发明产品专利的最终归属,至今没有任何一个国家有明确规定。

一个水杯开启的AI伦理之争
2018年,美国的一位人工智能研究者Stephen Thaler向美国专利局和欧洲专利局(EPO)提交了两份专利申请,一个是方便机械臂抓握的可变形饮料杯,另一个是应急灯。
这两个产品,是Thaler自己研发的人工智能DABUS独立设计发明的。
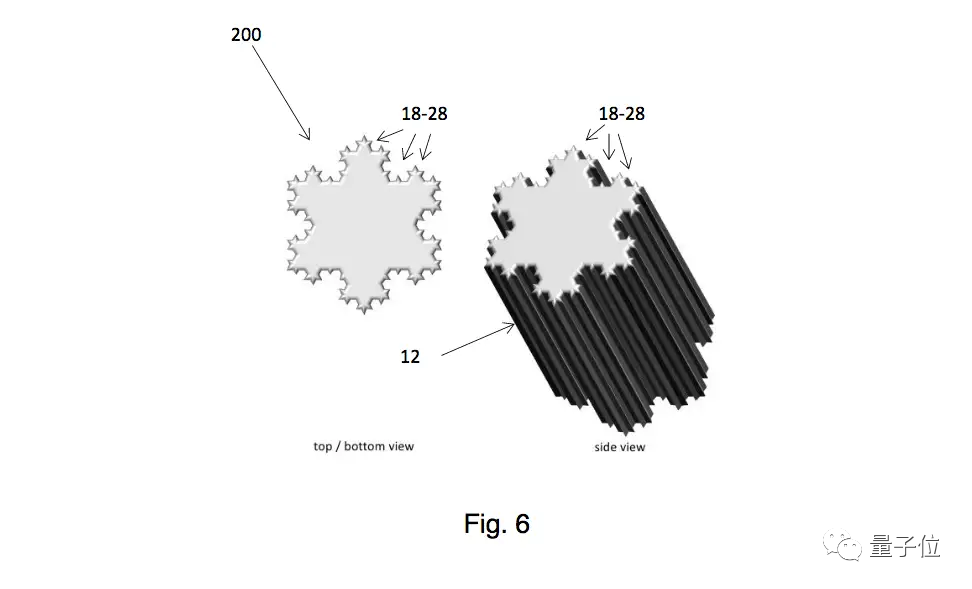
△DABUS发明的水杯
USPTO和EPO分别在去年12月和今年2月拒绝了这两项AI发明的专利申请。理由相同:在现行法律下,只有人类才能申请持有专利。
而美国专利局在4月27日发布的文件中,正式规定了今后任何人工智能都无权以发明者的身份申请或持有专利。
三方自说自话,AI专利问题可能永远无解
美国政府出台的规定并不能阻止科研者为AI争取「人权」的努力。
Stephen Thaler为了让DABUS合法申请持有专利,专门成立了「Artifitial Inventor」组织,广罗支持AI「人权」的科学家、哲学家、伦理学家发文宣传;还集合了欧美最优秀的专利律师,百折不挠地和政府专利部门辩论过招。而且这个组织的法律资源向全球开放,任何需要帮助的AI发明专利都可以联系帮助。
美国专利局提出过一项折中方案,即将这两项产品专利归在Stephen Thaler本人名下,但Thaler和他的Artifitial Inventor律师团队断然拒绝。
Artifitial Inventor的律师争论的核心观点是:Thaler没有参与任何发明过程,也根本不懂容器或应急灯设计,所有智力成果皆出于DABUS,所以专利只能属于人工智能,而不是开发人工智能的人。
对于Thaler提出的观点,美国专利局,及欧洲专利局根本不予回应,他们认为,问题关键不是智力成果的出处,而是非人智能体根本没有申请专利的合法资格。
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2020/07/8513.html