我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
OpenAI 引入了 MLE-bench,这是衡量 AI 代理在机器学习工程方面表现的基准。为此,OpenAI 从 Kaggle 中挑选了 75 项与 ML 工程相关的竞赛,创建了一组多样化的具有挑战性的任务,以测试现实世界中的 ML 工程技能,例如训练模型、准备数据集和运行实验。OpenAI 使用 Kaggle 的公开排行榜为每项竞赛建立人类基线。OpenAI 使用开源代理支架在我们的基准上评估了几种前沿语言模型,发现表现最佳的设置——OpenAI 的带有 AIDE 支架的 o1-preview——在 16.9% 的竞赛中至少达到了 Kaggle 铜牌的水平。除了主要结果之外,OpenAI 还研究了 AI 代理的各种形式的资源扩展以及预训练污染的影响。OpenAI 开源了基准代码(https://github.com/openai/mle-bench/)以促进未来对人工智能代理的机器学习工程能力的理解。
https://openai.com/index/mle-bench/
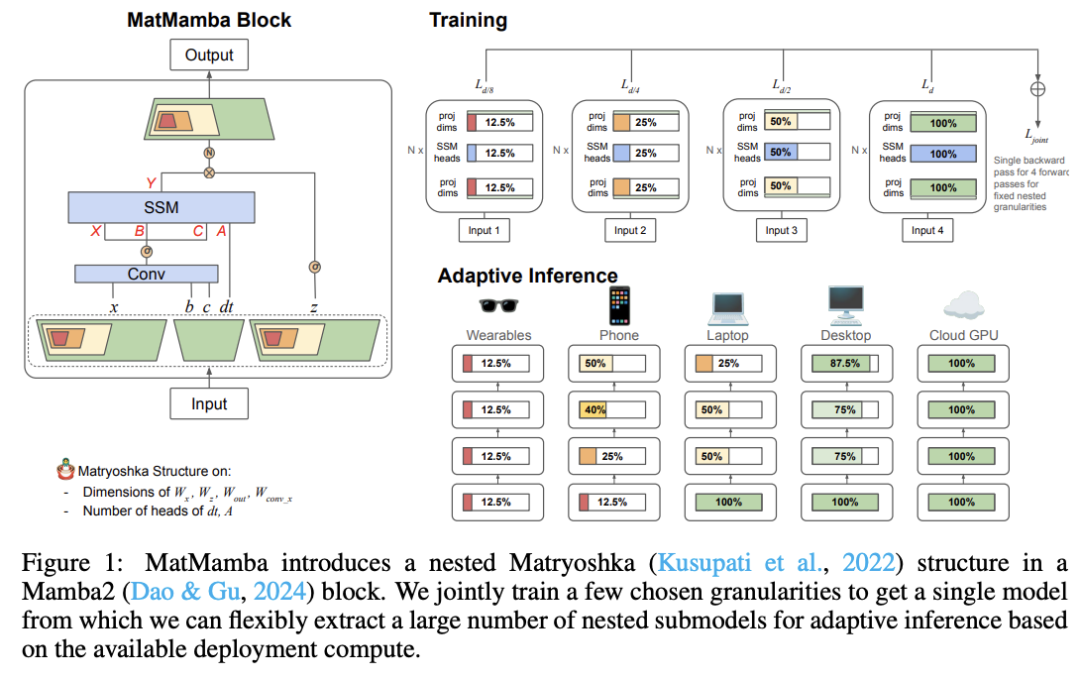
MatMamba: A Matryoshka State Space Model
状态空间模型 (SSM)(如 Mamba2)是 Transformers 的一个有前途的替代品,具有更快的理论训练和推理时间——尤其是对于长上下文长度。最近关于 Matryoshka 表示学习的研究——以及它在 MatFormer 等作品中对 Transformer 主干的应用——展示了如何在一个通用弹性模型中引入较小子模型的嵌套粒度。在这项工作中,我们提出了 MatMamba:一种将 Matryoshka 式学习与 Mamba2 相结合的状态空间模型,通过修改块以包含嵌套维度来实现联合训练和自适应推理。MatMamba 允许在各种模型大小中进行高效和自适应部署。我们训练一个大型 MatMamba 模型,并能够免费获得许多较小的嵌套模型——同时保持或提高从头开始训练的基线较小模型的性能。我们训练语言和图像模型,参数大小从 35M 到 1.4B。我们在 ImageNet 和 FineWeb 上的结果表明,MatMamba 模型的扩展性与 Transformers 相当,同时具有更高效的推理特性。这使得 MatMamba 成为基于可用推理计算以弹性方式部署大规模模型的实用选择。代码和模型在(https://github.com/ScaledFoundations/MatMamba)上开源。
 https://arxiv.org/abs/2410.06718
https://arxiv.org/abs/2410.06718
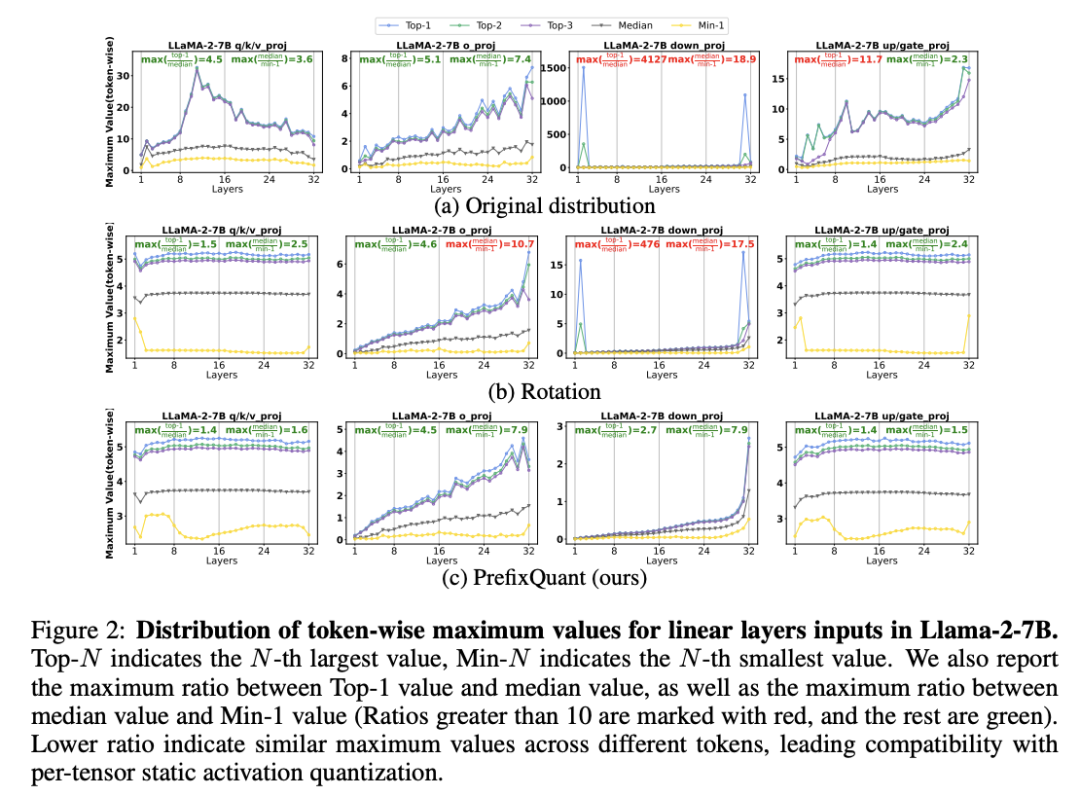
PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs
量化对于部署大型语言模型 (LLM) 至关重要,因为它可以提高内存效率和推理速度。现有的激活量化方法主要解决通道异常值问题,通常忽略标记异常值问题,导致依赖于昂贵的每个标记动态量化。为了解决这个问题,我们引入了 PrefixQuant,这是一种无需重新训练即可离线隔离异常标记的新技术。具体来说,PrefixQuant 识别高频异常标记并在 KV 缓存中为其添加前缀,从而防止在推理过程中生成异常标记并简化量化。据我们所知,PrefixQuant 是第一个实现高效的每个张量静态量化的方法,其性能优于昂贵的每个标记动态量化。例如,在 W4A4KV4(4 位权重、4 位激活和 4 位 KV 缓存)Llama-3-8B 中,具有每个张量静态量化的 PrefixQuant 在 5 个常识推理任务中实现了 7.43 WikiText2 困惑度和 71.08% 的平均准确率,优于之前的每标记动态量化方法,例如 QuaRot,困惑度提高了 0.98,准确率提高了 5.98 分。此外,使用 PrefixQuant 的 W4A4 量化模型的推理速度比 FP16 模型快 1.60 倍至 2.81 倍,比 QuaRot 模型快 1.2 倍至 1.3 倍。我们的代码可在(https://github.com/ChenMnZ/PrefixQuant)上可查看。
https://arxiv.org/abs/2410.06718
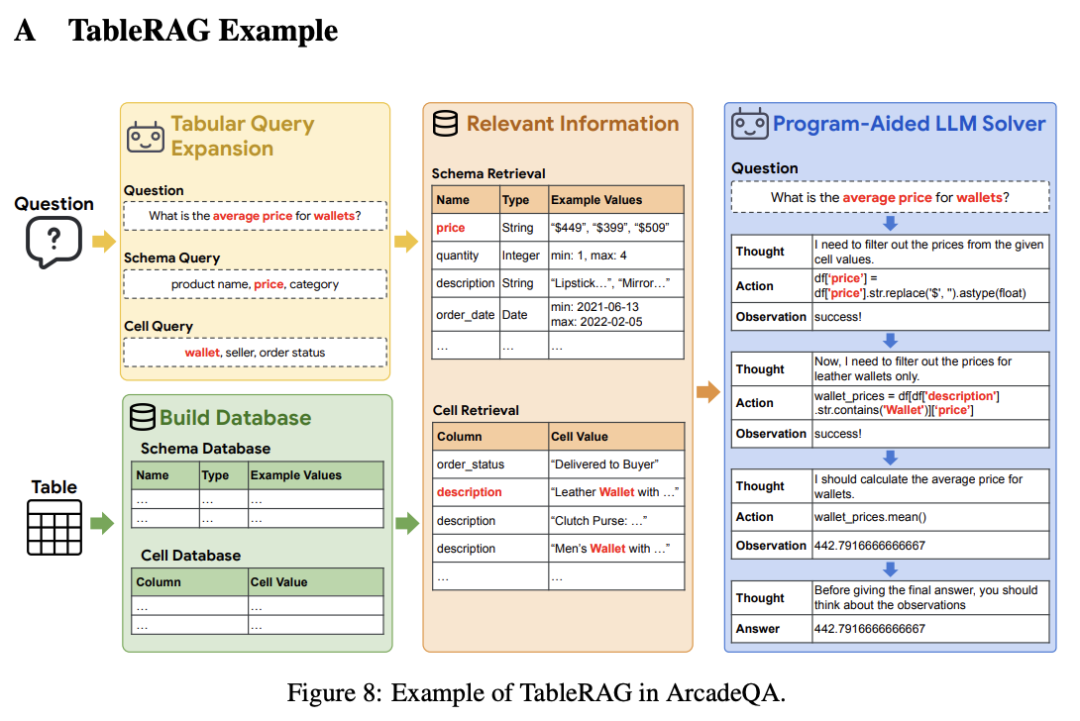
TableRAG: Million-Token Table Understanding with Language Models
语言模型 (LM) 的最新进展显著增强了它们推理表格数据的能力,主要是通过操纵和分析表格的程序辅助机制。然而,这些方法通常需要整个表作为输入,由于位置偏差或上下文长度限制,导致可扩展性挑战。为了应对这些挑战,我们推出了 TableRAG,这是一个专为基于 LM 的表格理解而设计的检索增强生成 (RAG) 框架。TableRAG 利用查询扩展与模式和单元格检索相结合来精确定位关键信息,然后再将其提供给 LM。这可以实现更高效的数据编码和精确的检索,从而显着减少提示长度并减少信息丢失。我们从 Arcade 和 BIRD-SQL 数据集开发了两个新的百万标记基准,以全面评估 TableRAG 在规模上的有效性。我们的结果表明,TableRAG 的检索设计实现了最高的检索质量,从而在大规模表格理解方面取得了新的最先进的性能。
https://arxiv.org/abs/2410.05265
falcon-mamba-7b
Falcon-Mamba-7B 主要用于英语自然语言处理。它基于 Mamba 架构,经过约 5,500 GT 的数据训练,具有 64 层和 4096 的隐藏维度,支持最大 8192 的序列长度。该模型在多个基准测试中表现优异,适合长范围依赖的任务。
https://huggingface.co/tiiuae/falcon-mamba-7b
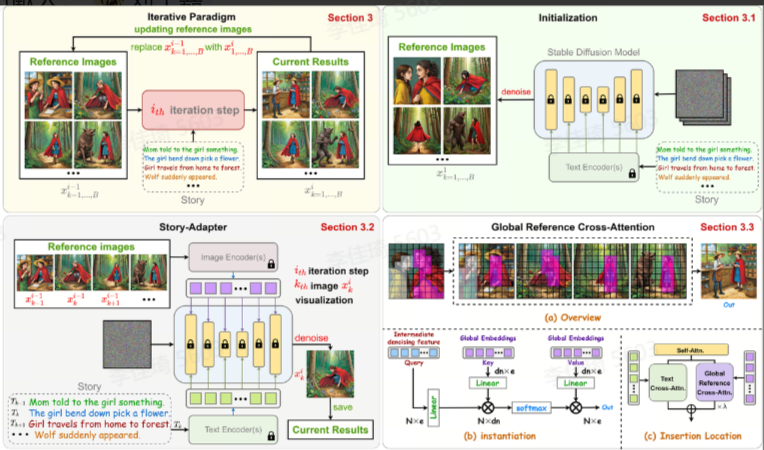
Story-Adapter
Story-Adapter 是一种用于长篇故事可视化的框架,通过迭代优化生成图像,结合文本提示和先前图像,利用全局参考交叉注意力模块保持语义一致性,提升细粒度交互的生成能力。
https://jwmao1.github.io/storyadapter/
-
-
-
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21570.html