我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
这篇文章介绍了Sana,一个高效的文本到图像生成框架,能够生成高达4096×4096分辨率的高质量图像。Sana的关键设计包括:(1) 深度压缩自编码器,可以将图像压缩32倍;(2) 线性DiT(Diffusion Transformer),使用线性注意力替代传统注意力机制,提高高分辨率下的效率而不牺牲质量;(3) 仅解码器的文本编码器,用现代小型解码器模型替换T5,并通过上下文学习增强图像-文本对齐;(4) 高效训练和采样技术,采用Flow-DPM-Solver减少采样步骤,并加速收敛。结果表明,Sana-0.6B在性能上与大型扩散模型(如Flux-12B)相当,但体积小20倍,速度快100多倍。此外,Sana-0.6B可以在16GB笔记本GPU上运行,生成1024×1024分辨率图像的时间不到1秒。代码和模型将公开发布。
https://x.com/JulienBlanchon/status/1846318852637949964
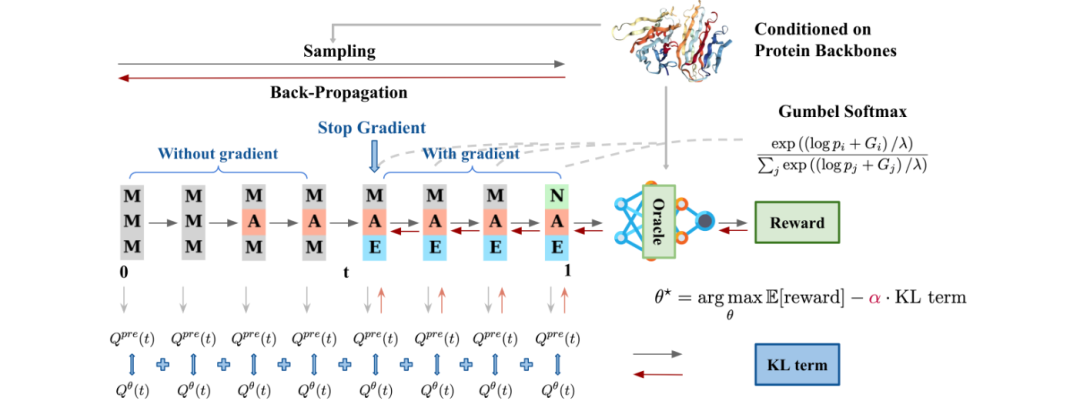
Fine-Tuning Discrete Diffusion Models via Reward Optimization with Applications to DNA and Protein Design
这篇文章介绍了一种新的算法DRAKES,它通过在离散扩散模型中结合强化学习(RL)来优化特定任务目标。该算法允许直接通过扩散模型生成的整个轨迹反向传播奖励,并使用Gumbel-Softmax技巧使原本不可微的轨迹可微。文章的理论分析表明,这种方法可以生成既类似于自然序列(即在预训练模型下有很高概率)又能得到高奖励的序列。文章还展示了该算法在生成优化增强子活性的DNA序列和优化蛋白质稳定性的蛋白质序列方面的有效性,这些是基因疗法和基于蛋白质的治疗中的重要任务。
https://x.com/svlevine/status/1847837069324013977
Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens
这篇文章探讨了在文本到图像生成任务中,自回归模型的扩展问题,特别是在视觉领域。研究关注了两个关键因素:模型是使用离散令牌还是连续令牌,以及令牌是按随机顺序还是固定光栅顺序生成。实验结果表明,使用连续令牌的模型在视觉质量上显著优于使用离散令牌的模型。此外,随机顺序模型在GenEval评分上明显优于光栅顺序模型。基于这些发现,研究者训练了一个名为Fluid的随机顺序自回归模型,该模型在MS-COCO 30K上的零样本FID达到了6.16的新最佳状态,并在GenEval基准测试中获得了0.69的总体得分。
https://arxiv.org/abs/2410.13863
Movie Gen: A Cast of Media Foundation Models
这篇文章介绍了一个名为Movie Gen的新型基础模型系列,该模型能够生成高质量的1080p高清视频,具有不同的宽高比和同步音频。此外,还展示了基于精确指令的视频编辑和根据用户图像生成个性化视频的附加功能。这些模型在文本到视频合成、视频个性化、视频编辑、视频到音频生成和文本到音频生成等多个任务上都取得了新的突破。文章还介绍了在架构、潜在空间、训练目标、数据管理、评估协议、并行化技术和推理优化等方面的多项技术创新和简化,这些创新使得在预训练数据、模型规模和训练计算方面取得了规模化的优势。
https://arxiv.org/abs/2410.13720
MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures
这篇文章介绍了MixEval-X,这是一个全新的多模态基准测试,旨在优化和标准化跨不同输入和输出模态的评估。文章指出了当前评估中存在的两个主要问题:不一致的标准和显著的查询、评分及泛化偏差。MixEval-X通过多模态基准混合和适应-校正流程来重建现实任务分布,确保评估能够有效泛化到现实用例。广泛的元评估表明,该方法能有效地将基准样本与现实任务分布对齐,并且其模型排名与众包现实评估高度相关,同时效率更高。
https://huggingface.co/papers/2410.13754
LazyLLM
LazyLLM是一款低代码构建多Agent大模型应用的开发工具,协助开发者用极低的成本构建复杂的AI应用,并可以持续的迭代优化效果。LazyLLM提供了便捷的搭建应用的workflow,并且为应用开发过程中的各个环节提供了大量的标准流程和工具。
基于LazyLLM的AI应用构建流程是原型搭建 -> 数据回流 -> 迭代优化,可以先基于LazyLLM快速跑通应用的原型,再结合场景任务数据进行bad-case分析,然后对应用中的关键环节进行算法迭代和模型微调,进而逐步提升整个应用的效果
https://github.com/LazyAGI/LazyLLM?tab=readme-ov-file
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21632.html