我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
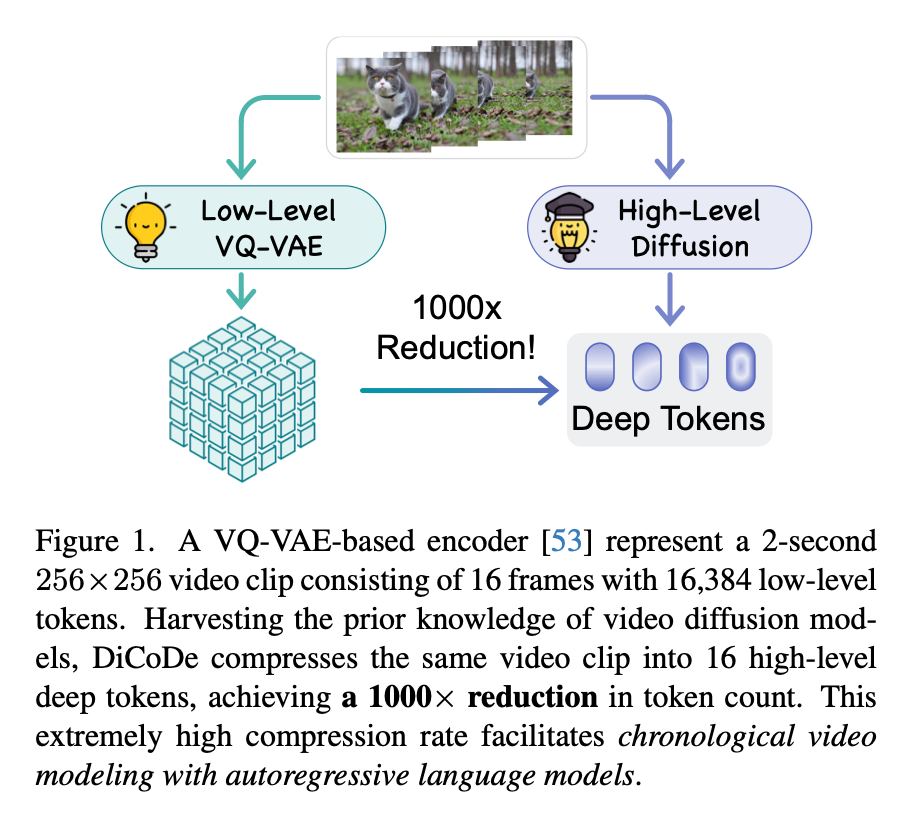
信号 两秒视频表示为 32 个 Diffusion-Compressed Deep Token 这篇论文提出了一种新的视频生成方法,旨在解决传统自回归模型在处理视频时面临的“token数量过多”的问题。自回归模型在生成视频时,需要大量的token表示每帧图像,例如,对于256×256分辨率的视频,单秒钟的视频就需要约6,000个token,这对于长时间的视频生成显然不适用。为了解决这个问题,论文提出使用16个token来表示两秒的视频,并利用扩散模型进行有效的token压缩。 首先,论文明确了其目标:通过在自回归模型和扩散模型之间架设中介,来压缩视频的token表示,同时保持视频的时序信息,并且确保其能与图像数据兼容。具体而言,时间因果性要求模型保留视频的时间顺序,而高效的token压缩则通过引入扩散模型的先验知识,显著降低了需要处理的token数量。此外,设计的tokenizer能够有效地处理图像数据,从而缓解了高质量视频-文本数据稀缺的问题。 技术上,论文采用了一种基于ViT的连续token而非离散token的表示方式,这使得视频的每一帧都可以通过一个1024维的特征向量来表示。相比于传统的图像token,这种方式不仅大幅减少了所需token的数量,同时也提高了图像和视频生成的质量。通过这种方法,16个token就足以有效压缩两秒钟的视频,显著提高了自回归生成的效率。 在方法实现上,DiCoDe模型首先通过视频的首尾两帧来进行token压缩,而中间帧则交由扩散模型生成。自回归模型DiCoDe在预测过程中,通过变分模型来估计下一个token的分布。训练时,损失函数为目标token在预测分布下的负对数似然;推理时,从该分布中采样生成下一个token。所采用的变分模型包括高斯模型和高斯混合模型,后者能够有效地捕捉视频生成中的不确定性。 此外,DiCoDe还利用了预训练的语言模型(如GPT2和Llama3.2)来进一步提高生成效果。使用这些强大的预训练模型,DiCoDe能够有效地进行自回归建模。具体来说,模型的自回归部分只需要修改最后一个投影层,以适应16个1024维的token输出,这样便能够大幅降低生成过程中的计算复杂度。 在实现细节上,作者使用了现成的视频扩散模型DynamiCrafter。这个模型基于256×256分辨率的图像,能够一次生成2秒的视频片段,并且采用了8fps的帧率。在训练过程中,模型通过WebVid-10M数据集进行训练,并且结合了来自不同数据集的图像和视频数据,以获得更丰富的生成知识。训练时,采用了固定学习率和AdamW优化器,且在多轮训练中逐步调整数据来源和模型参数。 最后,论文通过一系列的消融实验,展示了DiCoDe在不同token数量和损失函数设置下的性能变化,进一步验证了该方法在视频生成任务中的优势,尤其是在长时间视频生成中的扩展性和效率。 https://zhuanlan.zhihu.com/p/11586141743 ROSCon中国站——探索具身智能新高度——机器人在数据收集与学习策略中的优势和机会 在2024年ROS Conference中国站上,集智联机器人创始人包文涛介绍了机器人在数据收集和学习策略中的优势,尤其是在具身智能和机器人操作的深度融合方面。演讲探讨了Diffusion Policy、UMI数据收集框架及遥操作技术的潜力,并展示了Franka机器人在多模态融合、力控技术和学习策略中的卓越表现。 首先,包文涛强调了协作机器人对人形机器人硬件发展的贡献。协作机器人在力控技术、多模态感知和精准运动控制上的突破为人形机器人的设计提供了支持。同时,协作机器人积累的大量人机交互数据和应用经验,也优化了控制算法和运动规划能力。 ROS强化学习机器人数字孪生通用平台通过集成机器人控制、仿真和强化学习算法,为研发提供了高效的实验环境。该平台以Franka机器人(FR3)为核心,结合深度视觉设备Azure Kinect DK,支持实时计算和强化学习模型运行,且基于ROS框架进行运动规划和消息传递。 Franka机器人在多模态智能控制中发挥了重要作用。凭借其精准的力控能力(0.05N的力敏感度)和开放的开发生态(兼容C++、ROS、MATLAB),Franka能高效完成复杂任务。其多模态数据融合技术通过视觉、触觉和力感知的结合,实现了对复杂操作的精确执行。 包文涛还重点讨论了Diffusion Policy算法对机器人操作学习的影响。这种算法通过条件去噪扩散建模,将复杂任务的动作空间映射为多模态概率分布,从而生成稳定而鲁棒的行为。该策略不依赖于大量超参数调整,适用于多样化制造场景,展现了强大的适应性。 UMI数据收集框架在多模态数据采集中的应用也成为关注焦点。UMI整合RGB图像、末端执行器姿态和夹持器宽度,为策略学习提供高质量数据。尽管UMI在计算成本和数据同步性上存在挑战,但其在精密制造中的实时反馈能力和低成本高精度感知具有明显优势。FAST UMI框架优化了硬件配置和数据处理流程,显著提升了机器人学习效率,尤其是在未知场景中的应用。 丰田研究院展示了遥操作与力控技术结合的最新进展,通过力反馈遥操作设备,允许操作员直接控制机器人,并通过示例数据优化策略。这种结合加速了机器人学习,增强了人机协作能力,推动了具身智能技术的发展。
https://zhuanlan.zhihu.com/p/11669752908 浅析移动端 CPU 调度策略 在性能测试中,尤其是在移动设备上,测试环境与应用环境之间常常存在显著的性能差距。例如,虽然在测试工具中,某个模型的执行时间可能为1ms,但在实际应用中,这一时间可能会增加至4ms或10ms以上,原因主要是CPU调度策略和节能机制的影响。 CPU调度策略在调节计算负载、频率以及任务调度中起着核心作用。在移动设备中,CPU的计算频率是动态调整的,目的是在性能和功耗之间找到平衡。例如,当设备执行一个1x3x32x32大小的Mobilenet V1模型时,连续运行与间歇性运行(例如每次执行后休息1秒)会导致耗时的显著差异。连续运行时,平均耗时为0.9ms,而间歇性运行时,平均耗时则上升至11ms,这主要是因为任务在休息期间被降频,导致频率无法及时恢复到较高水平。 CPU负载计算通过PELT(Per Entity Load Tracking)和WALT(Window Assisted Load Tracking)两种方案来实现。PELT基于任务的历史执行时间来估计负载,但存在较高的延迟,尤其是在高负载任务的识别上。相比之下,WALT使用滑动窗口来实时计算任务负载,具有更快的响应速度,能够更有效地调整频率,虽然这可能会引发频率的快速波动。 动态频率调节(DVFS)通过选择合适的电压和频率对,旨在降低动态功耗。CPU频率和状态的切换会影响到功耗的优化。移动设备的CPU通常根据负载选择适当的频率状态,这样可以避免过度功耗。例如,当CPU负载较低时,系统会自动降低频率,以节省电能;而当负载增加时,频率会相应提高,以确保性能。 为了优化功耗,Linux内核中也采用了几种调度策略。CFS(Completely Fair Scheduler)适用于高负载情况下的公平调度,而EAS(Energy Aware Scheduling)则更加注重功耗优化,特别是在使用大小核架构时,它会根据任务的负载动态地将任务分配到合适的CPU核上,从而最大限度地减少能耗。EAS利用能量模型(EM)来计算每个CPU核心的功耗,并基于这些计算结果进行任务迁移,以降低整体能耗。 测试中的频率变化和任务调度导致的性能波动,尤其是在间歇性执行时,通常与设备的调度策略和节能机制密切相关。因此,在设计性能测试时,应考虑设备的功耗特性并模拟实际的应用环境,以更准确地评估系统性能。通过合理的任务调度和频率调整,可以在保证性能的同时,最大限度地降低功耗。 https://zhuanlan.zhihu.com/p/11634613935 浅析移动端 CPU 调度策略 在性能测试中,尤其是在移动设备上,测试环境与应用环境之间常常存在显著的性能差距。例如,虽然在测试工具中,某个模型的执行时间可能为1ms,但在实际应用中,这一时间可能会增加至4ms或10ms以上,原因主要是CPU调度策略和节能机制的影响。 CPU调度策略在调节计算负载、频率以及任务调度中起着核心作用。在移动设备中,CPU的计算频率是动态调整的,目的是在性能和功耗之间找到平衡。例如,当设备执行一个1x3x32x32大小的Mobilenet V1模型时,连续运行与间歇性运行(例如每次执行后休息1秒)会导致耗时的显著差异。连续运行时,平均耗时为0.9ms,而间歇性运行时,平均耗时则上升至11ms,这主要是因为任务在休息期间被降频,导致频率无法及时恢复到较高水平。 CPU负载计算通过PELT(Per Entity Load Tracking)和WALT(Window Assisted Load Tracking)两种方案来实现。PELT基于任务的历史执行时间来估计负载,但存在较高的延迟,尤其是在高负载任务的识别上。相比之下,WALT使用滑动窗口来实时计算任务负载,具有更快的响应速度,能够更有效地调整频率,虽然这可能会引发频率的快速波动。 动态频率调节(DVFS)通过选择合适的电压和频率对,旨在降低动态功耗。CPU频率和状态的切换会影响到功耗的优化。移动设备的CPU通常根据负载选择适当的频率状态,这样可以避免过度功耗。例如,当CPU负载较低时,系统会自动降低频率,以节省电能;而当负载增加时,频率会相应提高,以确保性能。 为了优化功耗,Linux内核中也采用了几种调度策略。CFS(Completely Fair Scheduler)适用于高负载情况下的公平调度,而EAS(Energy Aware Scheduling)则更加注重功耗优化,特别是在使用大小核架构时,它会根据任务的负载动态地将任务分配到合适的CPU核上,从而最大限度地减少能耗。EAS利用能量模型(EM)来计算每个CPU核心的功耗,并基于这些计算结果进行任务迁移,以降低整体能耗。 测试中的频率变化和任务调度导致的性能波动,尤其是在间歇性执行时,通常与设备的调度策略和节能机制密切相关。因此,在设计性能测试时,应考虑设备的功耗特性并模拟实际的应用环境,以更准确地评估系统性能。通过合理的任务调度和频率调整,可以在保证性能的同时,最大限度地降低功耗。 https://zhuanlan.zhihu.com/p/11634613935 HuggingFace&Github AgentStack 低代码解决方案
代理应该很简单:市面上有很多框架,但从头开始却很麻烦。与 类似 create-react-app ,AgentStack 旨在通过为您提供一个简单的代理样板来简化“从头开始”的过程。它使用流行的代理框架和 LLM 提供程序,但在此基础上提供有凝聚力的策划体验。
无需配置:您无需配置任何东西。开发和生产版本的合理配置已为您处理,因此您可以专注于编写代码。
无锁定:您可以随时自定义设置。AgentStack 旨在让您轻松立即运行所需的组件;接下来要做什么由您决定。
AgentStack 并非旨在成为构建代理的低代码解决方案。相反,它是从头开始启动代理项目的良好开端。
https://github.com/AgentOps-AI/AgentStack World ID 零知识验证代币 该存储库使用Semaphore 库允许集合中的成员声明 ERC-20 代币,通过零知识证明保护他们的隐私并消除组与声明者地址之间的链接。 World ID 是一种协议,它可让您证明人类只执行了一次操作,而无需透露任何个人数据。阻止机器人,阻止滥用。 World ID 使用一种名为Orb的设备,该设备会拍摄一个人的虹膜 align=”center” 的照片,以验证他们是否是独一无二的活着的人。该协议使用零知识证明,因此任何可追踪的信息都不会公开。 World ID 适用于链上 web3 应用程序、传统云应用程序甚至 IRL 验证。 https://github.com/worldcoin/world-id-example-airdrop
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/25316.html