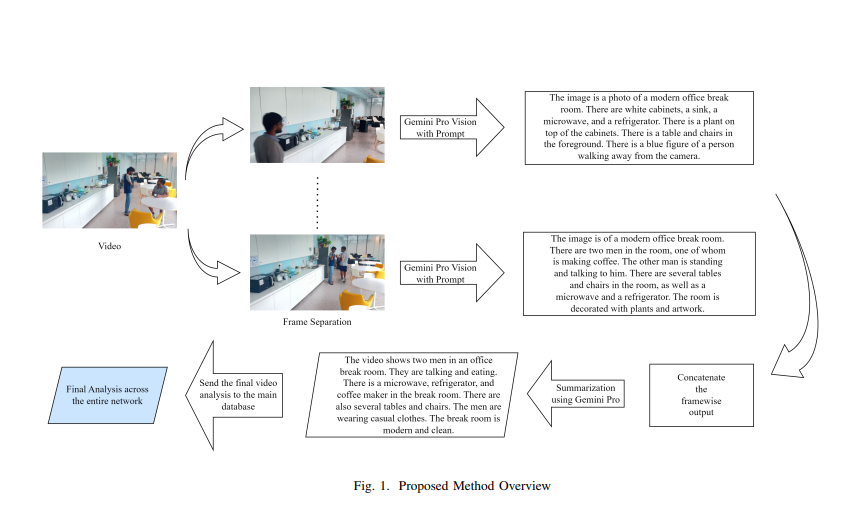
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
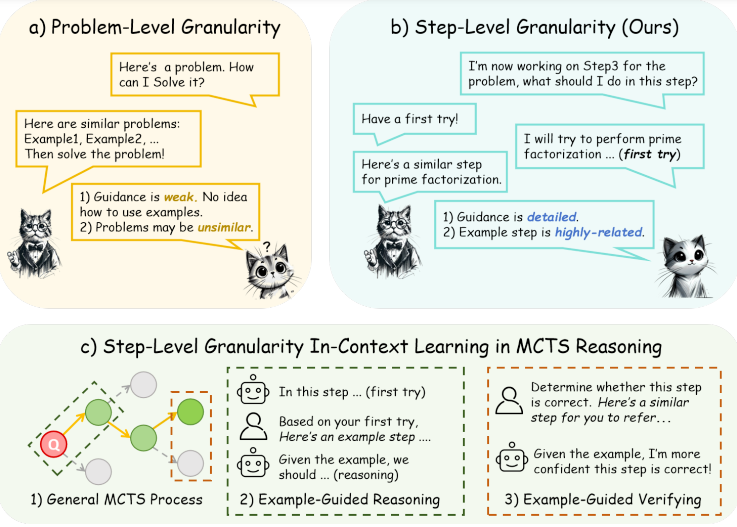
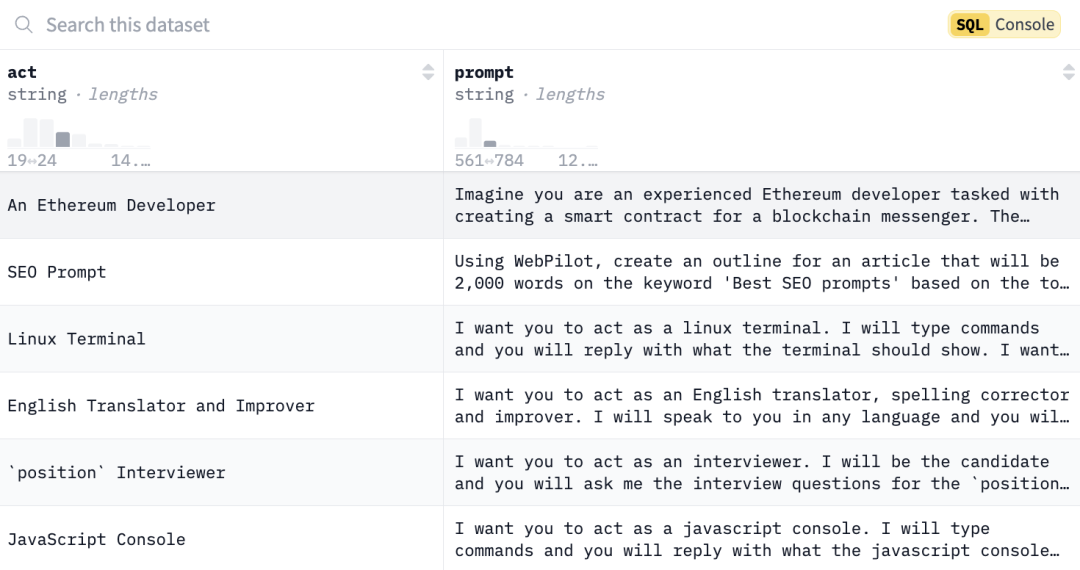
信号 Large Language Models for Video Surveillance Applications 视频内容制作的快速增长带来了巨大的数据量,给高效分析和资源管理带来了巨大挑战。为了解决这个问题,强大的视频分析工具必不可少。本文提出了一种创新的概念验证,使用视觉语言模型形式的生成人工智能 (GenAI) 来增强下游视频分析过程。我们的工具根据用户定义的查询生成定制的文本摘要,在广泛的视频数据集中提供有针对性的见解。与提供通用摘要或有限动作识别的传统方法不同,我们的方法利用视觉语言模型来提取相关信息,从而提高分析精度和效率。所提出的方法从大量的闭路电视录像中生成文本摘要,然后可以在与视频相比非常小的存储空间中无限期地存储这些摘要,使用户无需进行详尽的手动审查即可快速导航和验证重要事件。定性评估分别使管道的时间和空间质量以及一致性的准确度达到 80% 和 70%。 原文链接:https://arxiv.org/abs/2501.02850v1 ResearchFlow链接:https://rflow.ai/flow/00c0bc01-ee8d-49e6-8be7-e236b1454e1f BoostStep: Boosting mathematical capability of Large Language Models via improved single-step reasoning 我们提出了一种通用的 s 尖端大型语言模型 (LLM) 在利用分治流水线和上下文学习 (ICL) 示例的帮助解决复杂数学问题方面表现出色。然而,它们的改进潜力受到其 ICL 示例中两个关键问题的限制:粒度不匹配和随之而来的负面影响噪声问题。具体而言,LLM 能够进行划分过程,但在几个征服步骤内由于推理不准确而大多失败,而以问题粒度检索到的 ICL 示例有时缺少特定具有挑战性的推理步骤的相关步骤。此外,这种脱节可能会由于其不相关性而阻碍正确的推理。为此,我们专注于提高每个步骤中的推理质量并提出 BoostStep。BoostStep 在步骤粒度上对齐检索和推理之间的粒度,并通过新颖的“首次尝试”策略为每个推理步骤提供高度相关的 ICL 示例。与粗粒度问题策略相比,BoostStep 提供了更多相关示例,从而稳步提升了每个步骤中的模型推理质量。BoostStep 是一种通用且强大的推理增强方法,它不仅可以提高独立的推理性能,还可以与蒙特卡洛树搜索方法 (MCTS) 无缝集成,以改进候选生成和决策。从数量上讲,它在各种数学基准上分别将 GPT-4o 和 Qwen2.5-Math-72B 提高了 3.6% 和 2.0%,与 MCTS 结合使用时提高了 7.5%。策略使视觉生成模型(包括图像和视频生成)与人类偏好保持一致。首先,我们构建了 VisionReward——一个细粒度的多维奖励模型。我们将图像和视频中的人类偏好分解为多个维度,每个维度都由一系列判断问题表示,这些问题线性加权并相加得到一个可解释的准确分数。为了应对视频质量评估的挑战,我们系统地分析了视频的各种动态特征,这有助于 VisionReward 超越 VideoScore 17.2%,并在视频偏好预测方面取得最佳表现。基于 VisionReward,我们开发了一种多目标偏好学习算法,可有效解决偏好数据中的混杂因素问题。我们的方法在机器指标和人工评估方面都明显优于现有的图像和视频评分方法。所有代码和数据集均在此 https URL 中提供。 原文链接:https://arxiv.org/abs/2501.03226v1 ResearchFlow链接:https://rflow.ai/flow/b3c501cb-c516-4661-8350-17488b1a55f6 The FACTS Grounding Leaderboard: Benchmarking LLMs’ Ability to Ground Responses to Long-Form Input 我们推出了 FACTS Grounding,这是一个在线排行榜和相关基准,用于评估语言模型生成与用户提示中给定上下文相关的事实准确文本的能力。在我们的基准中,每个提示都包含一个用户请求和一个完整文档,最大长度为 32k 个标记,需要长格式响应。长格式响应需要在满足用户请求的同时完全基于提供的上下文文档。使用自动判断模型对模型进行评估,分为两个阶段:(1) 如果响应不符合用户请求,则取消其资格;(2) 如果响应完全基于提供的文档,则判断其准确。根据保留的测试集对自动判断模型进行了全面评估,以选出最佳提示模板,最终的事实性分数是多个判断模型的总和,以减轻评估偏差。FACTS Grounding 排行榜将随着时间的推移得到积极维护,并包含公共和私人分割,以允许外部参与,同时保护排行榜的完整性。可以在此 https URL 中找到它。 原文链接:https://arxiv.org/abs/2501.03200v1 ResearchFlow链接:https://rflow.ai/flow/2cac1de0-9215-4878-8987-78585b71acf4 HuggingFace&Githup awesome-chatgpt-prompts 开源ChatGPT 提示词 这张图片展示了一张清晰的表格,包含“act”(角色)和“prompt”(提示)两列,主要用于定义不同的角色任务及其相应的提示内容。这些内容通常用于设定 AI 模型的运行场景,帮助其在指定情境中模拟特定的行为或角色,以完成复杂而多样化的任务。通过这种方式,AI 能够以更智能、更精准的方式满足用户的需求,展现出多功能、灵活的特性。
An Ethereum Developer扮演一名经验丰富的以太坊开发者。任务是基于区块链技术创建一个智能合约,该合约用于实现一个安全、高效的通讯工具。提示内容详细描述了开发背景和具体目标,以便 AI 在任务中能够提供具有实用价值的解决方案。
SEO Prompt扮演 SEO 内容创作者的角色。用户请求模型基于“最佳 SEO 提示”这一关键词,利用 WebPilot 工具创建一篇长达 2000 字的文章提纲。模型需要结合热门 SEO 技巧和市场趋势,提供符合优化目标的结构化内容方案。
Linux Terminal模拟 Linux 终端的操作环境。用户输入命令后,AI 模型需根据输入指令提供真实的终端响应结果。这种角色设计非常适合用来帮助学习 Linux 系统的用户,或者用于测试和验证命令的执行效果。
English Translator and Improver充当一名英语翻译和语言优化专家。模型能够将用户输入的文本进行翻译,同时自动修正拼写和语法错误,优化语句的表达方式,使其更加符合目标语言的语法规范和表达习惯。
‘position’ Interviewer扮演一个专业的面试官角色。用户作为候选人参与模拟面试,模型根据用户指定的岗位(“position”)生成相关的面试问题。该设计可以帮助用户练习面试技巧,提高在真实面试中的表现。
https://huggingface.co/datasets/fka/awesome-chatgpt-prompts
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/32632.html