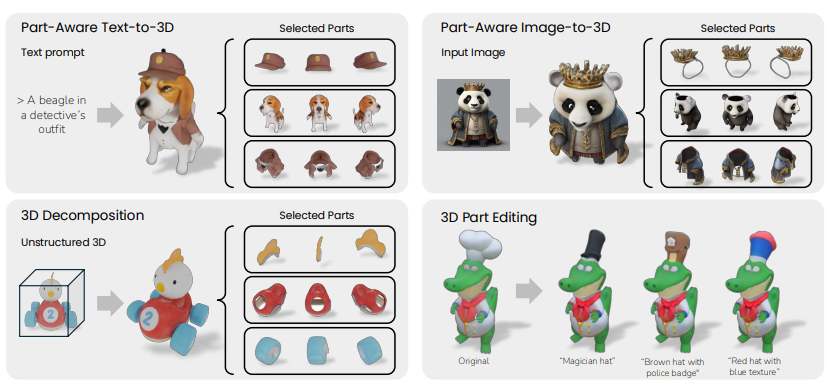
PartGen: Part-level 3D Generation and Reconstruction with Multi-View Diffusion Models
文本或图像到 3D 生成器和 3D 扫描仪现在可以生成具有高质量形状和纹理的 3D 资产。这些资产通常由单一的融合表示组成,如隐式神经场、高斯混合或网格,没有任何有用的结构。然而,大多数应用程序和创意工作流程都要求资产由几个可以独立操作的有意义的部分组成。为了解决这一差距,我们引入了 PartGen,这是一种新颖的方法,它从文本、图像或非结构化 3D 对象开始生成由有意义的部分组成的 3D 对象。首先,给定 3D 对象的多个视图(生成或渲染),多视图扩散模型提取一组合理且视图一致的部分分割,将对象分成多个部分。然后,第二个多视图扩散模型分别获取每个部分,填充遮挡,并通过将这些完成的视图馈送到 3D 重建网络来使用这些完成的视图进行 3D 重建。这个完成过程考虑了整个对象的上下文,以确保各部分紧密结合。生成式补全模型可以弥补由于遮挡而缺失的信息;在极端情况下,它可以根据输入的 3D 资产产生完全不可见的幻觉。我们在生成的和真实的 3D 资产上评估了我们的方法,并表明它的表现远远优于分割和零件提取基线。我们还展示了 3D 零件编辑等下游应用。原文链接:https://arxiv.org/abs/2412.18608ResearchFlow链接:https://rflow.ai/flow/7b575d63-cf6e-4d13-9b91-8a92f14d0b7602
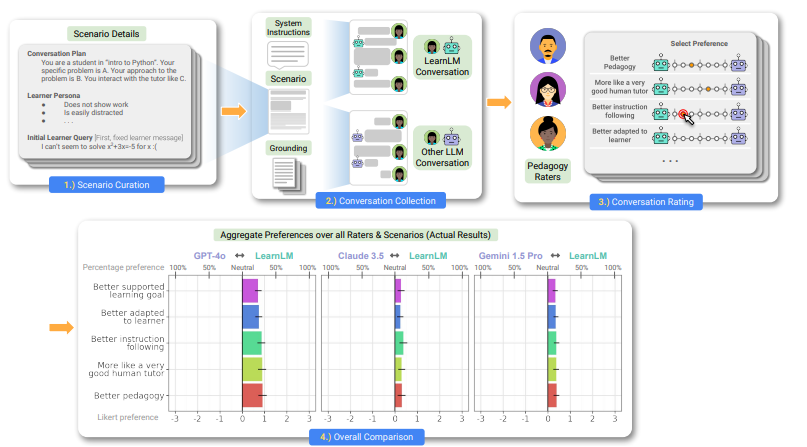
LearnLM: Improving Gemini for Learning
当今的生成式 AI 系统默认呈现信息,而不是像人类导师那样让用户参与学习。为了解决这些系统广泛的潜在教育用例,其中训练和评估示例包括系统级指令,描述后续模型转变中存在或期望的特定教学属性。这种框架避免将我们的模型承诺于任何特定的教学定义,而是允许教师或开发人员指定所需的模型行为。它还为改进 Gemini 学习模型扫清了道路——通过将我们的教学数据添加到训练后混合中——以及它们迅速扩展的功能集。两者都代表了我们最初的技术报告的重要变化。我们展示了如何通过遵循教学指导进行训练来产生一个 LearnLM 模型(可在 Google AI Studio 上使用),该模型在多种学习场景中受到专家评分者的广泛青睐,其平均偏好强度比 GPT-4o 高 31%、比 Claude 3.5 高 11%、比 LearnLM 所基于的 Gemini 1.5 Pro 模型高 13%。原文链接:https://arxiv.org/abs/2412.16429ResearchFlow链接:https://rflow.ai/flow/c3c6ab8c-55e0-40ef-8fef-e8997827588703