我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
资讯
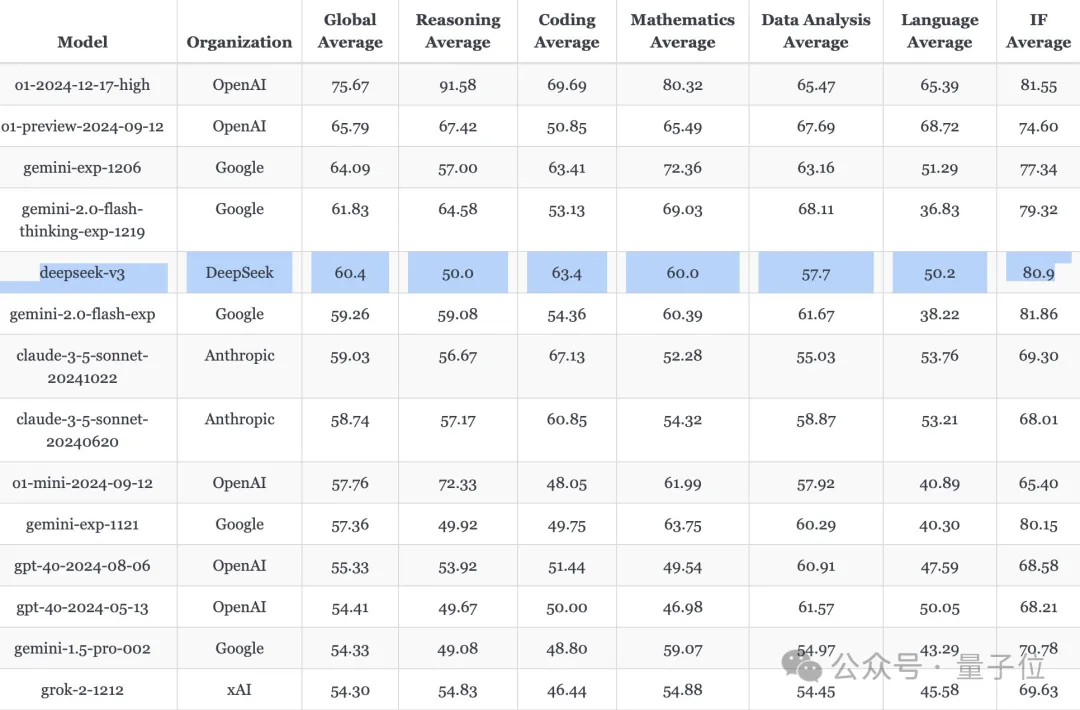
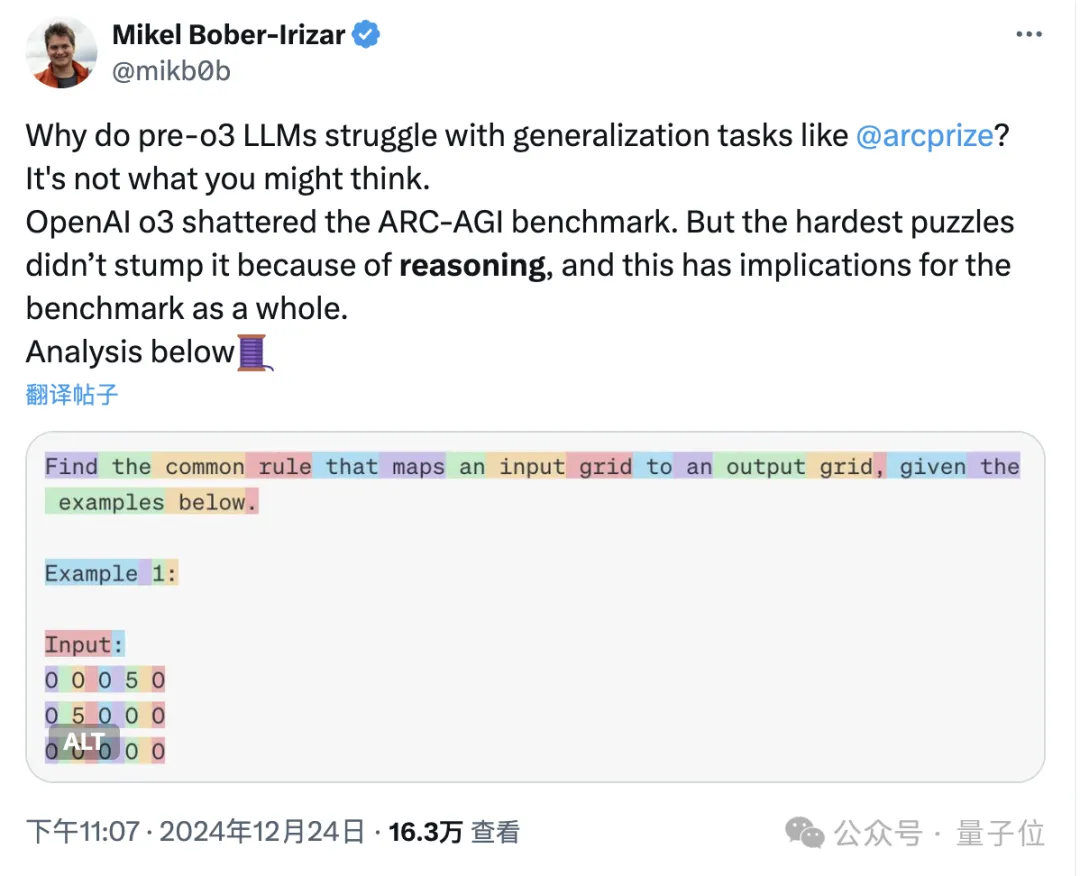
Deepseek-v3 Deepseek-v3意外曝光,引起了广泛关注,尽管尚未正式宣布。根据Reddit用户和其他测试者的爆料,Deepseek-v3已在API和网页上上线,并且其性能在多个评测中脱颖而出。它在Aider的多语言编程测试中超越了Claude 3.5 Sonnet,排在o1之后,完成率从Deepseek-v2.5的17.8%大幅提升至48.4%。在LiveBench测评中,Deepseek-v3被认为是目前最强的开源LLM,仅在非推理模型中稍逊于gemini-exp-1206,位列第二。 Deepseek-v3相比前代v2和v2.5在多个方面有了显著提升。它采用了685B参数的MoE架构,配备256个专家,支持64K上下文,默认支持4K,最长可扩展到8K。每秒处理约60个tokens。此外,Deepseek-v3的Instruct版本在Aider测试中成功超越Claude 3.5 Sonnet,但该版本尚未发布。 与v2相比,Deepseek-v3的进步主要体现在以下三个方面:首先,v3使用了sigmoid函数替代v2中的softmax函数,这使得模型能够从更大的专家集合中进行选择;其次,引入了不依赖辅助损失的新方法——noaux_tc,简化了训练过程并提高了效率;第三,新增了e_score_correction_bias参数,以优化专家评分并提升性能。 与v2.5相比,Deepseek-v3增加了更多的专家数量和更大的中间层尺寸,进一步提升了每个token的处理能力。测试者Simon Willison(Django框架的创始人之一)在实测中发现,Deepseek-v3不仅能生成创意图像,还能回答如同OpenAI模型一样的问题,暗示其训练过程中可能使用了OpenAI的反馈。 尽管Deepseek-v3的正式发布尚未到来,但其在多个排行榜和测评中的表现已经让它成为目前最强的开源LLM之一,甚至在某些人的眼中,它的表现远超OpenAI的产品。 o3挑战ARC-AGI,遇见大网格就懵圈 在ARC-AGI超难推理任务中,o3展现了惊人的成绩,但一项深入的研究揭示了模型在面对大规模网格题目时的表现瓶颈。英国ML工程师Mikel Bober-Irizar(米哥)研究了ARC题目,发现大模型在处理较大规模网格时表现较差,尤其是在网格数量超过1024时,o3的表现开始急剧下降。米哥通过对ARC数据集的规模分布分析,指出大模型在面对规模较大的题目时,性能显著下降,而在规模较小的题目中则表现较好。类似的现象不仅出现在o3,也出现在o1、o1-mini和Claude等模型中。 米哥进一步实验了o1-mini,发现将网格切割成更小的单元后,模型的推理能力显著下降,验证了大模型在面对更大规模问题时的局限性。米哥认为,ARC挑战不完全反映大模型的推理能力,因为它过于依赖较小规模的问题,而忽视了大模型在处理大规模网格时的表现瓶颈。 米哥的分析还指出,大模型与人类的思考方式在解决这类问题时存在根本差异。人类能通过视觉感知和空间推理轻松解决这些问题,而大模型则需要通过更长的上下文进行推理。尤其在跨行列的推理中,随着网格规模的增大,模型必须处理更长的上下文信息,这对其推理能力构成挑战。米哥提到,通过旋转矩阵让模型分别基于行列进行推理,能显著提高性能,表明大模型在处理这类任务时,维度感知和视觉理解的差异至关重要。 网友也指出,尽管模型拥有类似“视觉”的能力,但将视觉信息转换为Token的方式与人类的视觉体验截然不同。人类的视觉能力可以并行处理信息,而大模型则是串行处理Token,这种处理方式的差异影响了模型的推理效果。 与此同时,ARC挑战官方宣布将推出下一代版本ARC-AGI-2,预计对o3构成更大挑战。初步测试显示,o3在高计算量模式下的得分可能会降至30%以下,而人类的得分仍可能超过95%。这表明,尽管大模型在某些任务上表现突出,但它们在应对更复杂的推理问题时仍存在显著的局限性。 全新B300为o1推理大模型打造,RTX5090同时曝光 英伟达的最新发布可谓是“圣诞老黄”的大礼包,推出了两款突破性AI芯片:B300和GB300,均在算力和显存方面进行了显著提升。B300的FLOPS相比B200提升了50%,显存容量也从192GB提升至288GB,显著提升了AI推理大模型的能力。GB300更是配备了72块B300 GPU,被誉为解决OpenAI o1/o3推理大模型的唯一方案,能够在高batch size下处理更长的思维链,显著提升处理效率。 尽管B300仍基于Blackwell架构,但其算力提升主要得益于工艺微创新、功率增加以及动态分配技术。其显存也从原来的8层HBM3E升级为12层(12-Hi HBM3E),显存带宽保持在8TB/s,进一步提高了数据处理效率和模型推理速度。此外,GB300系列的产品交付方式也发生变化,改为提供参考板,允许客户自行采购其他组件,为供应链中的OEM和ODM制造商提供了更多灵活性。 显存的增加对AI推理模型至关重要,尤其是对于OpenAI o1/o3这样的复杂模型,显存的提升意味着更低的延迟、更长的思维链、降低推理成本和更高效的样本搜索。这些提升直接影响了AI模型的能力和成本效益。与传统的摩尔定律相比,英伟达的进步速度令人瞩目,显存增加带来的效益超越了表面提升,显著提升了模型的毛利率和竞争力。 此外,英伟达还曝光了消费级显卡RTX 5090的PCB板,预计将配备32GB显存,并支持8K超高清游戏,提供60fps流畅体验。RTX 5090的发布可能会在1月6日的CES上揭晓,引发业界广泛关注。 端侧 AI 落地挑战有多大?手机、PC、汽车、具身机器人有话说
消费电子与大模型结合:智能手机和PC期待AI大模型赋能,以提高效率和创造新功能。钱电生认为大模型是基础设施,将促进新应用的出现。孙峪强调AI将改变人机交互,使PC更易用,提高办公效率。
端侧模型挑战:端侧部署面临算力和存储挑战,需要异构硬件支持和框架层面的算力调度。钱电生提到3D RAM可能成为端侧部署的有效解决方案。
大模型上车:黄小严和笪琦讨论了大模型在智能座舱中的应用,强调了理解用户意图、提供共情关怀和完成任务的能力。北汽已在多款车型中部署大模型,通过百模汇创平台灵活接入垂域模型。
具身大脑:秦玉森和刘威彤讨论了大模型对具身智能的影响,包括常识压缩、多模态识别和自动化数据标注,认为大模型将推动机器人技术的发展。
人形机器人市场:刘威彤认为人形机器人市场广阔,但目前处于早期阶段。市场将从To B向To C发展,初期可能在文娱展演、医疗等领域应用,家庭应用将是最后到来但市场最大的。
技术范式和路线:秦玉森指出,行业尚未追求真正的端到端模型,而是通过“段到段”的方法,将功能封装成模块,逐步实现端到端。
推特
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
Hyperspace Wallet:与区块链交互的智能代理 宣布 Hyperspace Wallet:与区块链交互的智能代理
https://x.com/varun_mathur/status/1872013645233954973 Agarwal分享:环视 Lofi Girl 房间,Veo2 生成 我成功将自己的图片上传到 Veo 2!这是让我它环视 Lofi Girl 房间时的效果——非常令人惊艳!
https://x.com/pallavmac/status/1871997677405397311
Google Cloud发布Trillium:谷歌目前第六代性能最强的TPU 我们的节日灯版本:Trillium——迄今为止我们第六代性能最强的TPU! 我们使用 Trillium TPU 训练了全新的 Gemini 2.0,现在它已全面向 Google Cloud 客户开放。 了解更多关于 Trillium 的信息,请点击 → https://goo.gle/3ZMKBqR
https://x.com/googlecloud/status/1871662382386225603 EXO Labs分享 12 天挑战第一天:透明基准测试,真实的消费设备上运行了1000多个大型语言模型基准测试 我们在真实的消费设备上运行了1000多个大型语言模型(LLM)基准测试。 数据包括单设备和多设备集群的每秒令牌数(TPS)和首令牌生成时间(TTFT)。 测试设备配置包括:3台 M4 Mac Mini 集群、iPhone 15 + S24、RTX4090 等。 https://blog.exolabs.net/day-1/
https://x.com/exolabs/status/1871993287273533707 产品 Tutor LMS 3.0 一体化 WordPress LMS Tutor LMS 3.0 为在线教育领域带来了全新的突破,其现代化设计、内置的电子商务功能和强大的人工智能工具,为用户提供了从课程创建到管理和盈利的全流程解决方案。通过 Tutor LMS 3.0,用户可以轻松设计吸引人的在线课程,集成支付和订阅管理系统,并利用 AI 优化学习内容,提高学生的参与度和满意度。一切都集中在一个平台内,无需额外工具或复杂操作,让教育工作者和企业家专注于实现知识共享和业务增长的目标。 https://www.hume.ai/blog/introducing-octave?ref=producthunt 使用简短的 AI 课程,以您的母语和真实语境快速学习任何语言。我们的 AI 会创建引人入胜的视觉效果,您会记住它们并将其作为备忘单保存。最好的部分是什么?您可以从您最喜欢的视频和内容中创建自定义课程。 https://mylens.ai/apps/easylang?ref=producthunt — END — 快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29119.html