我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
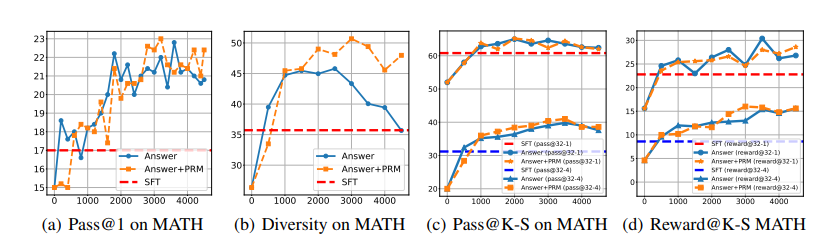
B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners
这篇文章探讨了在缺乏大量人工标注数据的情况下,如何通过自我改进方法来提升模型性能。文章识别了两个关键因素:模型生成多样化响应的能力(探索)和外部奖励区分高质量与低质量候选的能力(利用)。通过数学推理的案例研究,发现模型的探索能力会迅速下降,外部奖励的有效性也会减弱。基于这些发现,文章提出了B-STaR框架,它能够自动调整迭代中的配置,以平衡探索和利用,优化自我改进的效果。实验表明,B-STaR不仅提高了模型的探索能力,还实现了探索和利用之间更有效的平衡,从而提升了性能。
原文链接:https://arxiv.org/abs/2412.17256
ResearchFlow链接:https://rflow.ai/flow/8793c2b9-8f41-409d-bcef-a507ab7e0986
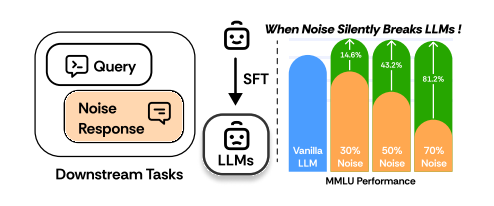
RobustFT: Robust Supervised Fine-tuning for Large Language Models under Noisy Response
这篇文章介绍了一个名为RobustFT的鲁棒监督微调框架,它专门设计来提高大型语言模型(LLMs)在存在噪声数据的情况下的下游任务性能。RobustFT通过一个两阶段的噪声检测和去噪框架来增强模型性能,首先利用多专家协作系统进行噪声检测,然后通过上下文增强推理进行数据去噪,最终实现在噪声场景下的稳健微调。
原文链接:https://arxiv.org/abs/2412.14922
ResearchFlow链接:https://rflow.ai/flow/8917825c-507c-45d7-b5d2-2e6e6fabfbeb
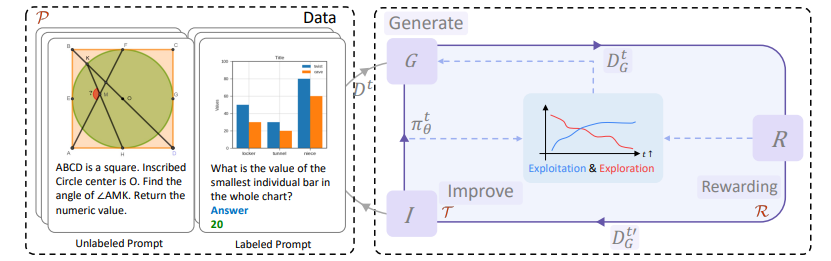
Diving into Self-Evolving Training for Multimodal Reasoning
这篇文章深入研究了大型多模态模型(LMMs)的自我演化训练,特别是在缺乏多模态链式思考标注数据的情况下如何提升模型的推理能力。文章识别了三个关键因素:训练方法、奖励模型和提示变化,并系统地分析了这些因素对训练效果的影响。研究结果揭示了在自我演化训练过程中,模型的探索能力会迅速下降,而外部奖励的有效性也会随之降低。基于这些发现,文章提出了MSTaR框架,这是一个多模态自我演化训练推理框架,能够自动调整迭代中的配置,以平衡探索和利用,优化自我改进的效果。实验结果表明,MSTaR框架不仅增强了模型的探索能力,还实现了探索和利用之间的更有效平衡,从而在多个基准测试中取得了卓越的性能,显著超越了预演化模型,且无需额外的人类标注数据。这项研究不仅填补了多模态推理自我演化训练理解上的重要空白,还为未来的研究提供了一个强大的框架,并公开了策略、奖励模型和收集的数据,以促进多模态推理领域的进一步研究。
原文链接:https://arxiv.org/abs/2412.17451
ResearchFlow链接:https://rflow.ai/flow/665b673c-a20c-4718-8938-a6650daab6ce
HuggingFace&Github
Ruyi-Mini-7B 开源图像转视频生成模型
Ruyi-Mini-7B 是一种开源图像转视频生成模型。从输入图像开始,Ruyi 生成分辨率从 360p 到 720p 的后续视频帧,支持各种宽高比,最长持续时间为 5 秒。通过运动和摄像头控制增强,Ruyi 在视频生成方面提供了更大的灵活性和创造力。我们根据宽松的 Apache 2.0 许可证发布该模型。
https://huggingface.co/IamCreateAI/Ruyi-Mini-7B
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29094.html