
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

潜空间第六季活动开始报名!!
【第 2 期嘉宾介绍】杨松琳——MIT计算机科学与人工智能实验室二年级博士生。专注线性注意力机制、机器学习与大语言模型交叉领域,聚焦高效序列建模的硬件感知算法设计。围绕线性变换、循环神经网络优化开展研究,在多任务中取得成果,多篇论文被 ICLR 2025、NeurIPS 2024 等顶会收录;还开源 flash-linear-attention 项目,助力领域发展。本次活动她将带来《下一代LLM架构展望》的主题分享


学习
琢磨一下DeepSeek未来还会发些啥
这周的技术讨论显然聚焦在DeepSeek(DS)近期的进展和可能的后续动作上。首先,DS这次的发布几乎是围绕着H800进行的,符合预期但也给人留下了一些悬念。值得注意的是,DS此前曾表示比黄老板还擅长利用GPU,且今后可能会有更多不同的“惊喜”推出。在行业内部,虽然H800是合法的美国认证硬件,但DS显然并不止于此,未来可能推出更具敏感性和创新性的技术。换句话说,DS或许正准备把FP4/6这类算子在新的硬件架构上进一步优化。
其中,关于RTX 40×0/50×0系列消费卡的优化方向,成为一大猜测点。考虑到50×0系列已经支持FP4,DS有可能通过特别的算法或硬件hack来进一步突破带宽和计算的瓶颈。比如通过修改L2缓存的替换算法,或利用GPUDirect RMDA/Storage优化数据迁移,减轻互联带来的负担。这类优化在深度学习应用中可能带来显著的性能提升,尤其是在推理和训练任务中。
另外,FP4/6算子的普及似乎已成必然。随着浮点数位宽的减少,如何在保证计算精度的同时提高性能,将成为核心难题。对于DS而言,解决这个问题不仅是硬件优化的关键,还涉及到算法层面的微调,尤其是在多模态计算中,如何平衡不同算子精度和执行效率是巨大的挑战。尤其是随着硬件架构的不断变化,精度的控制将成为一项皇冠级的技术任务。DS或许已经在考虑如何通过新型的硬件支持和算法调优来解决这些问题。
上下文处理也是DS关注的重点。考虑到多模态技术和复杂的用户需求,如何有效处理不同的Attention模式、数据压缩算法以及分布式内存管理将直接影响推理性能。如果DS能够获取更高端的机器并启用nvlink-c2c等技术,CPU和GPU的混合计算可能会成为未来部署的关键。这将使得DS在数据存取和计算能力上达到更高的平衡,特别是在大规模部署时,能够有效降低通信时间并提高吞吐量。
最后,关于部署策略,DS似乎已经从V3中推荐的全并行推理方式发生了变化,开始关注更高效的吞吐优化和带宽利用。尤其是在考虑到像H800等硬件的性能瓶颈时,TP4并行的方式不再适用,而是更多地依赖于算法和硬件的协同优化。随着硬件的逐步升级,新型部署方式可能会更加依赖于局部性能和更精细的参数调控。
https://zhuanlan.zhihu.com/p/27412570526
基于GRPO的视觉语言模型强化学习实践:思维链对VLM定位任务的影响分析
GRPO(Group Relative Policy Optimization)方法在视觉语言模型(VLM)中的应用探索了强化学习在多模态任务中的潜力。GRPO通过利用组内相对奖励来优化策略,避免了传统PPO方法中需要的巨大价值模型,从而大幅降低了显存消耗,特别适合在复杂的视觉语言任务中进行应用。VLM-R1在此基础上进行改进,采用GRPO优化了训练流程,进一步提升了模型的推理能力,尤其是在视觉定位(如图像中物体的边界框预测)任务中。通过强化学习,VLM-R1能够自主探索,减少对标注数据的依赖,显著提高了在领域外数据上的泛化能力。
VLM-R1的奖励函数设计深度借鉴了DeepSeek的输出奖励模型(ORM),根据任务类型(如图像目标定位)进行适配。奖励设计要求模型既要通过语法检查,又要通过语义验证,确保生成的文本不仅格式正确且能够准确描述图像中的内容。
实验过程中,模型在图像中的推理能力表现较好,能够准确识别并定位图像中的图形元素,理解物体之间的空间关系,并具备一定的推理能力。然而,模型在生成思维链(CoT)时存在一定错误,尤其是在遇到一些不匹配的输入时,推理输出与图像不符,但边界框(BBox)定位依旧准确。这提出了一个关键问题,即思维链在定位任务中的实际作用边界。
进一步实验表明,去除思维链后的模型在训练和验证集上的表现与原模型相差无几,尤其是在简单任务中,思维链的影响有限。基于此,可以得出结论:在一些基础的视觉任务中,思维链的作用可能不如预期,且去除后对模型性能影响较小。此外,强化学习方法(如GRPO)在视觉语言模型中的应用证明了其在OOD(Out-of-Domain)数据集上的良好泛化能力,并有效避免了过拟合。
后续计划中,考虑到思维链在简单任务中的作用较弱,未来将通过设计更复杂的任务来进一步验证思维链在视觉语言推理中的潜力,并优化GRPO方法的奖励设计,以进一步提升模型的推理性能,探索其在复杂推理任务中的表现。

https://zhuanlan.zhihu.com/p/27168077143
DeepSeek时代:关于AI服务器的技术思考(PCIe篇)
在当前AI服务器架构中,GPU的连接方式是影响性能的重要因素之一。对于GPU服务器,常见的连接方式有PCIe和UBB(Ultra Bandwidth Bridge)。PCIe连接虽然常见,但在大规模模型推理中,显存容量和带宽限制可能影响性能。而像NVIDIA的H200系列GPU则通过4-way NVLink桥接,能够打通显存,提供更高带宽,但对于大型模型的推理,单机显存仍然不足。UBB模组通过高速互联使得GPU之间的通信更加流畅,适用于大规模训练和推理。尽管如此,PCIe接口依然有广泛的应用,特别是在一些不需要极端带宽的场景下。
以Dell的PowerEdge XE7745为例,这款4U服务器支持最多8块双宽600W的PCIe AI加速卡。它采用了4颗144 lane的PCIe Switch,每个Switch通过x16通道连接到GPU,能够提供高达24个满血PCIe 5.0 x16插槽,支持大规模扩展,同时也能保持每个卡的最大带宽。此外,电源模块设计方面,XE7745配置了8个3200W电源模块和12个风扇,以确保GPU和CPU的高功率需求,特别是在高负载情况下,提供足够的电力保障。
在散热方面,XE7745采用了先进的散热设计,特别是在1U CPU模块和3U GPU模块的分区设计上,通过物理隔离来优化散热。其支持500W的双CPU配置,并为GPU提供高达9600W的功率。由于GPU的散热问题较为复杂,特别是当GPU功耗达到600W时,必须使用被动散热系统,限制了某些高功耗卡的使用。
此外,PCIe Switch到CPU的上行链路设计中存在一定的不对称性。尽管每颗Switch都有相应的连接到CPU,但其中一颗Switch仅通过x16通道连接到CPU,而其他三颗则是双x16连接。这种设计可能是为了在保证带宽的同时优化硬件成本,但也带来了一定的性能瓶颈。
对于GPU服务器的CPU选择,要求较高的内存带宽和多通道支持。以AMD EPYC平台为例,最新的9005系列支持最高6400 MT/s的内存频率,每颗CPU支持12个内存通道,能够提供更高的内存带宽,以满足AI推理和训练的需求。

https://zhuanlan.zhihu.com/p/27518634990
FP8 低精度训练:Transformer Engine 简析
FP16和BF16混合精度(AMP)已经成为当前大规模模型训练的主流技术,广泛应用于大模型预训练、微调等任务,能够提升训练效率并减少显存和资源占用。PyTorch 1.6版本后,原生支持FP16和BF16精度的AMP训练,而之前这一功能是通过NVIDIA APEX库实现的。自Hopper架构起,NVIDIA GPU也支持FP8精度计算。与FP16和BF16相比,FP8具备更强的计算性能,能够在训练中提供2-3倍的速度提升,同时显著降低内存占用和数据通信量。
FP8的优势体现在计算吞吐量的提升,尤其是在与A100比较时,其吞吐量提升超过2倍。FP8还支持更高效的模型优化,通过训练过程中量化数据,能够进一步压缩模型,降低部署成本。FP8具有两种主要的表示方式,分别是E4M3和E5M2,其中E4M3适用于权重和激活数据,E5M2适用于梯度数据。与INT8相比,FP8拥有更宽的动态范围,能够更精确地捕捉LLM(大语言模型)中的参数分布,因此更适用于该类任务。
虽然FP16和BF16已成为主流训练精度,但在大规模模型训练中,FP8的精度损失影响较小,可以通过降低精度来提升效率。FP8训练在大多数任务中与FP16精度相当,仅在某些数学运算或特定下游任务中存在细微差距。在实际应用中,如Inflection AI和零一万物等公司已经在大规模训练中成功采用FP8,取得了显著的性能提升。例如,Inflection-2模型在5000个NVIDIA Hopper架构GPU上使用FP8混合精度训练,超越了Google的PaLM 2模型,表现出卓越的性能。
FP8的应用不仅限于训练,推理过程也得到了显著加速。Google与NVIDIA合作,在Gemma模型的推理中应用FP8技术,显著提升了吞吐量。此外,NVIDIA的Transformer Engine(TE)为FP8训练提供了支持,并已集成到PyTorch、JAX、Paddle等主流深度学习框架中,同时也适用于专为LLM设计的框架如Megatron、NeMo、DeepSpeed、HuggingFace等。
TE框架的FP8训练流程采用了精细的量化策略,针对每个tensor计算一个Per-tensor Scaling Factor,以提高量化精度。FP8训练需要通过“延迟缩放”(Delayed Scaling)策略来处理规模调整,通过计算amax历史记录来近似确定scale值,从而减少因精度限制带来的误差。Tensor Core是FP8训练的核心计算单元,FP8计算仅能在Tensor Core上运行,并且要求输入矩阵的维度为16的倍数。
FP8训练的限制主要体现在小规模训练(参数少于1B时)的性能提升较小,且当batch size过小(如4时),可能会导致性能下降。FP8在某些微调任务中(如数学运算或MMLU困难任务)表现较差,并且在训练过程中可能出现异常(如loss spike或NaN)。然而,FP8及更低精度训练的前景依然广阔,特别是在大规模模型训练中,FP8有望成为标准配置之一。随着硬件的进步,未来FP6和FP4等更低精度的计算也有可能成为常规方案,进一步推动低精度训练的应用。

大视觉模型的自回归预训练
本文提出了大视觉模型 AIM。AIM 是属于受到大语言模型 LLM 的启发,使用自回归训练策略来训练大视觉模型的方法。AIM 和 LLM 一样展示出了缩放能力,AIM 的预训练也类似于 LLM 的预训练。本文的关键发现是两点:
-
视觉模型提取的特征的质量随模型容量和数据量的增加而增加。
-
训练的目标函数的值与模型在下游任务的性能有关。
本文作者在 2B 张图片上训练了 7B 参数的 AIM 模型,在 ImageNet-1K 上面得到了 84.0% 的性能。而且有趣的是,即使在这个尺度上,仍然没有观察到性能饱和的迹象。

HuggingFace&Github
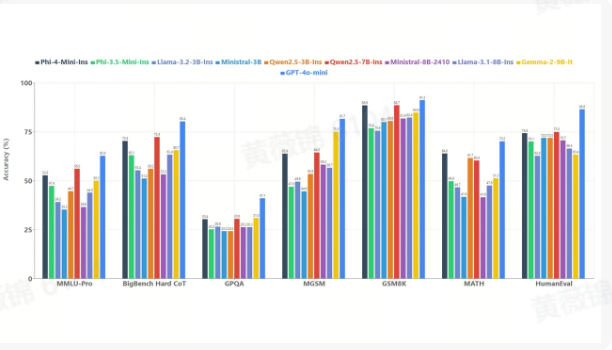
Phi-4-mini-instruct:轻量级开源模型
Phi-4-mini 是一个轻量级开源模型,该模型属于 Phi-4 系列,支持 128K 令牌上下文长度。该模型经过增强过程,通过监督微调和直接偏好优化。Phi-4-mini-instruct 基于 Phi-3 系列的用户反馈。Phi-4-mini 模型采用了新的架构以提高效率,扩大了词汇量以支持多语言,并且使用了更好的后训练技术来跟踪指令、调用函数以及获取更多数据。
应用场景:
-
内存/计算受限的环境
-
延迟受限场景
-
数学和逻辑推理
https://huggingface.co/microsoft/Phi-4-mini-instruct
NVIDIA DeepSeek R1 FP4:量化版R1
NVIDIA DeepSeek R1 FP4 模型是 DeepSeek AI 的 DeepSeek R1 模型的量化版本,使用优化的 Transformer 架构的自回归语言模型,使用TensorRT 模型优化器进行量化。模型可以用于商业/非商业用途。
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43209.html