
潜空间活动报名
除嘉宾分享外,每期设置了【匹配合伙人 Cofounder Matching】环节。你可以和 GenAI 时代最有活力的创业者和研究者线下面对面交流,将有机会找到志同道合、有共同创业梦想的小伙伴。
报名通道已开启,欢迎扫描下方二维码报名。


信号
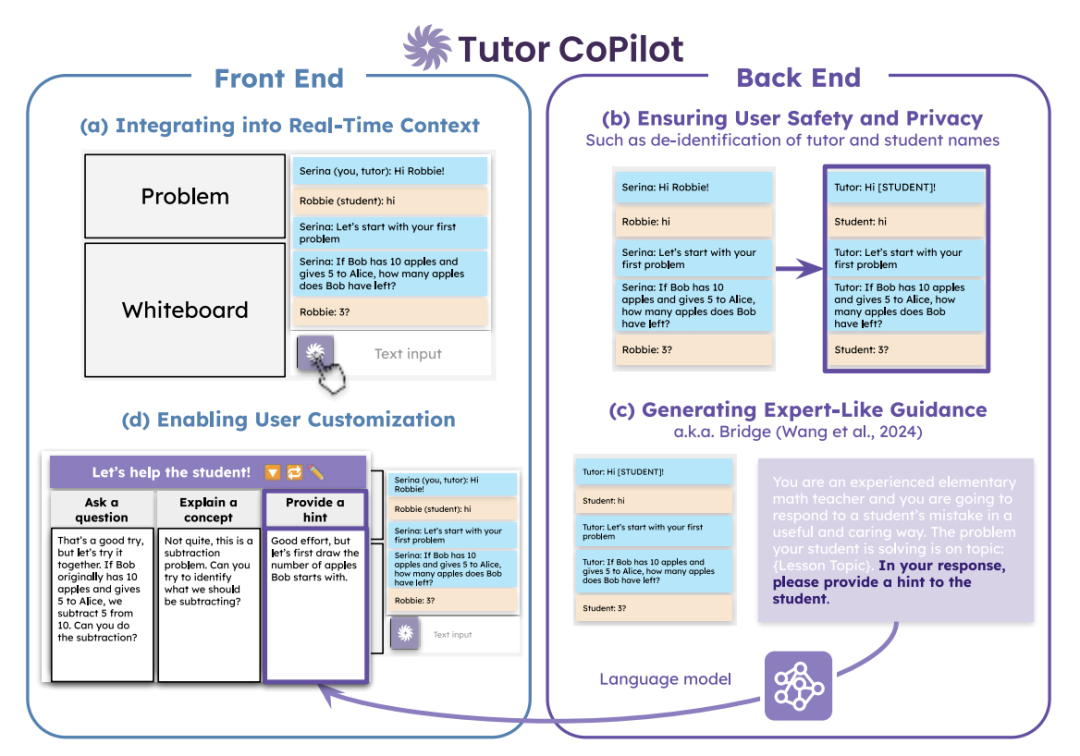
Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise
DynamicCity: Large-Scale LiDAR Generation from Dynamic Scenes
-
HexPlane学习模型:利用变分自编码器(VAE)进行4D表示的压缩,采用新颖的投影模块,将4D LiDAR特征有效地压缩为六个2D特征图,从而显著提高拟合质量(增益高达12.56 mIoU)。同时,采用扩展和压缩策略并行重建3D特征体,提高了网络训练效率和重建精度(分别增益7.05 mIoU、2.06倍训练加速、70.84%内存减少)。 -
基于DiT的HexPlane生成扩散模型:提出Padded Rollout操作,将HexPlane特征重新组织为平方2D特征图,支持多种4D生成应用,如轨迹和命令驱动的生成、修复和布局条件生成。

Bio2Token: All-atom tokenization of any biomolecular structure with Mamba

VibeCheck: Discover and Quantify Qualitative Differences in Large Language Models

Amphion
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21646.html