我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
叶添 揭秘大语言模型推理机制——超越人类的二级推理 奇绩潜空间活动报名 【奇绩潜空间】 是 GenAI 时代冲得最快的一批科研学者/从业者/创业者聚集的 AI 人才社 区,潜空间定期邀请大模型前沿创业者分享产品实践探索,邀请前沿科研学者分享最新技术进展。
第五季第二期潜空间邀请到的嘉宾是 清华大学姚班,卡内基梅隆大学博士生,Physics of LLM 2.1作者,于 Meta 担任 Research Scientist Intern 的 叶添 ,在本次活动中叶添将在北京现场与大家面对面交流,他分享的主题是《 揭秘大语言模型推理机制——超越人类的二级推理 》。
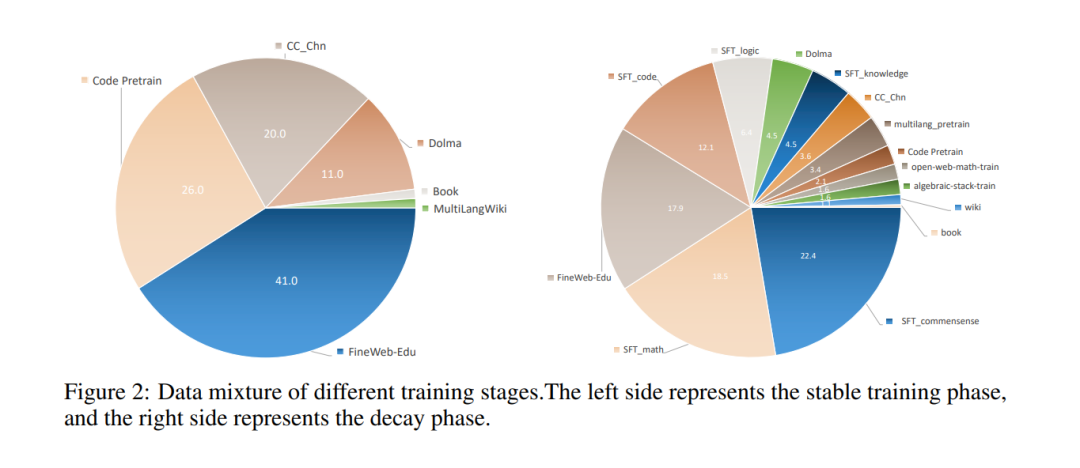
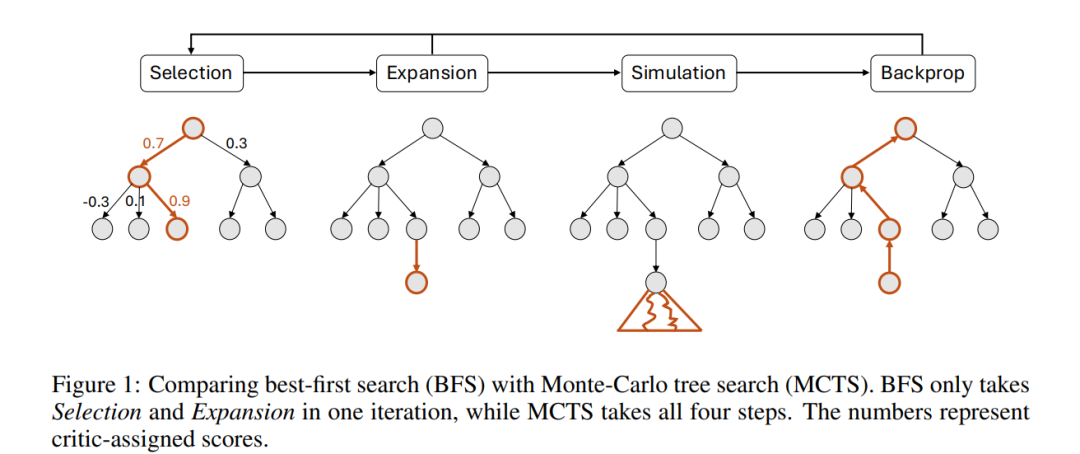
信号 OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis 本文提出了OS-Genesis,一种无需人工监督或预定义任务的高质量和多样化GUI(图形用户界面)代理轨迹合成新管道。该方法旨在解决GUI代理开发中的关键挑战,包括自动理解用户意图、规划任务和执行动作。传统的GUI代理轨迹构建方法,如人工收集或基于模型的合成,面临着高成本、劳动密集、可扩展性差以及中间步骤错误等显著问题。 为了克服这些挑战,作者提出了一种基于交互的方式。OS-Genesis从人类学习与GUI应用程序互动的方式中获得灵感,首先通过执行交互操作(如点击)探索GUI环境的功能,这为反向任务合成提供了基础。反向任务合成通过回溯的方式,将观察到的状态和动作转化为低级指令,进一步合成为高级指令,从而创建有意义和可执行的任务。这一方法有效地弥合了抽象指令与GUI动态特性之间的差距。 该管道还引入了奖励模型,以确保合成数据的质量和有效利用,增强GUI代理的端到端训练。通过在两个具有挑战性的基准上进行实验,AndroidWorld和WebArena,OS-Genesis显著优于传统的任务驱动方法,在AndroidWorld上的性能提升接近8%(从9.82%提升至17.41%)。 https://arxiv.org/abs/2412.19723 ResearchFlow链接:https://rflow.ai/flow/4bc0c997-5009-403f-b1bb-192989c2c002 Xmodel-2 Technical Report 本文提出了Xmodel-2,一个1.2B参数的语言模型,旨在平衡推理能力与训练效率。尽管大规模语言模型(LLMs)在自然语言理解上取得了显著进展,但在复杂推理任务中仍面临挑战。有效推理对自动化客户服务和科学发现等应用至关重要,而大规模模型虽然推理能力更强,但也需要更多计算资源、更长的训练时间和更高的能源消耗。 Xmodel-2采用创新的架构,基于Tensor Programs(张量程序)[Yang et al., 2022][Yang et al., 2023],使得不同规模的模型能够共享相同的超参数。这种方法允许在小规模模型上进行广泛的超参数搜索,并将最佳配置无缝转移到更大规模的模型,从而提升了效率和性能。此外,Xmodel-2采用了MiniCPM的Warmup-Stable-Decay (WSD)学习率调度器,用于加速训练并确保稳定收敛。Xmodel-2在15万亿个token上进行预训练,能够处理文本和代码等多样化输入,显著提升了其在复杂推理任务中的表现。 https://arxiv.org/abs/2412.19638 ResearchFlow链接:https://rflow.ai/flow/351cbc2a-cb80-4fc2-9a84-cc72d67dd090 HUNYUANPROVER: A Scalable Data Synthesis Framework and Guided Tree Search for Automated Theorem Proving 本文提出了HUNYUANPROVER,一个旨在解决自动定理证明中的挑战的框架,特别是在处理复杂的形式化定理证明(如使用LEAN或Isabelle等系统)时的困难。尽管大规模语言模型(LLMs)在自然语言处理领域取得了显著进展,但它们在形式定理证明方面仍面临巨大的挑战,尤其是在奥林匹克级定理证明的广阔搜索空间和有限的数据支持下。即使是最先进的模型如GPT-4,也在处理复杂的形式化定理证明时表现不佳。一个有效的定理证明模型必须理解形式系统的语法和语义,并能够在系统内生成有效的下一步推理,更重要的是,它需要将这种能力与抽象数学推理技能结合,以进行高效和有效的推理。 HUNYUANPROVER框架由两个核心模块组成:可扩展的证明器数据生成器和引导树搜索算法。数据生成器利用开源数据训练初始的自动格式化器和证明器。自动格式化器将大量现有的数学问题转换为目标证明系统(如LEAN4)的格式。然后,证明器通过迭代方式不断改进,每次迭代生成新的证明数据以训练证明器。在测试阶段,树搜索算法和多个评论模型协同工作,进行“慢思考”,这一过程对于解决复杂的定理证明任务至关重要。 评估结果显示,HUNYUANPROVER在miniF2F基准测试中取得了68.4%的准确率。此外,还发现了几个关键点:1)显式训练的评论模型在树搜索引导中非常有帮助;2)定理证明的微调数据规模至关重要,因此设计高效的数据扩展框架非常重要;3)数据策划和选择也很关键,尤其是在有足够训练数据的情况下。 https://arxiv.org/abs/2412.20735 ResearchFlow链接:https://rflow.ai/flow/715bebb9-ce2e-4277-9eb7-e2bddae40810 VMix: Improving Text-to-Image Diffusion Model with Cross-Attention Mixing Control 近年来,文本生成图像(text-to-image)领域取得了显著进展,尤其是大规模预训练文本到图像扩散模型的出现,使得人们可以通过文本提示轻松生成视觉吸引的图像。然而,尽管这些大规模模型在视觉真实感和文本一致性方面表现出色,生成的图像仍然与人类预期存在显著差距,尤其在光照不自然、人物扭曲或色彩过饱和等方面。由于人类对这些细节异常敏感,这使得AI生成内容在电影制作等实际应用中面临挑战。因此,如何准确地将生成图像与人类偏好对齐,成为当前的关键问题。 现有研究已在提高图像质量方面做出了大量努力,主要分为两个方向。一方面,一些方法通过基于高质量子数据集微调预训练的文本到图像模型,或通过强化学习和直接偏好优化(DPO)等技术优化模型。另一方面,另一些研究则专注于探索预训练扩散模型的生成行为,改善其生成稳定性,例如,FreeU提出了通过重加权跳跃连接和骨干网络的贡献来增强去噪能力,同时提升细节表现。 然而,本文认为现有方法未能有效地对齐人类对视觉内容的细粒度审美偏好。理想的图像应在多个审美维度上达到卓越表现,如自然光照、协调的色彩和合理的构图等。现有方法通过增强详细的文本描述来改善生成效果,但这并不能解决细粒度审美的需求,因为现有文本编码器(如CLIP或T5)主要用于捕捉高层语义,缺乏对难以言喻的视觉审美的准确感知。此外,优化整体图像生成质量的方向与这些细粒度审美维度的优化方向并不一致,尽管生成结果的文本一致性可能提高,但视觉构图可能变差。 为了解决这一挑战,本文提出了VMix,一种新型的即插即用适配器,旨在系统性地弥合生成图像与现实图像在多个审美维度上的差距。VMix通过在大规模数据集中精选高质量图像子集进行微调,并根据摄影标准(如色彩、光照、构图和焦点等)对图像进行标签化,进而改善生成模型的审美表现。在训练过程中,VMix冻结基础模型,采用LoRA方法以确保实际应用的可行性,并设计了两个专门模块将审美标签作为额外条件融入到U-Net架构中。第一个模块是审美嵌入初始化模块,将审美文本数据转换为与对应图像对齐的嵌入;第二个模块是跨注意力混合控制模块,旨在最小化对图像-文本对齐的负面影响,同时避免直接改变注意力图。 经过大量实验,结果表明,VMix能够与各种基础模型无缝集成,显著提升其审美表现。同时,VMix与社区模块(如ControlNet、I Adapter和LoRA)具有极好的兼容性,进一步扩展了创作的可能性。
分析并探索生成图像在细粒度审美维度上的差异,提出通过分离文本提示中的内容描述和审美描述,为模型优化提供明确方向。
提出了VMix,通过一种新型的条件控制方法(值混合跨注意力),将输入文本提示分解为内容描述和审美描述,从而为模型提供更好的引导。
提出的VMix方法在现有扩散模型中具有普适性,作为一种即插即用的审美适配器,具有很好的与社区模块的兼容性。
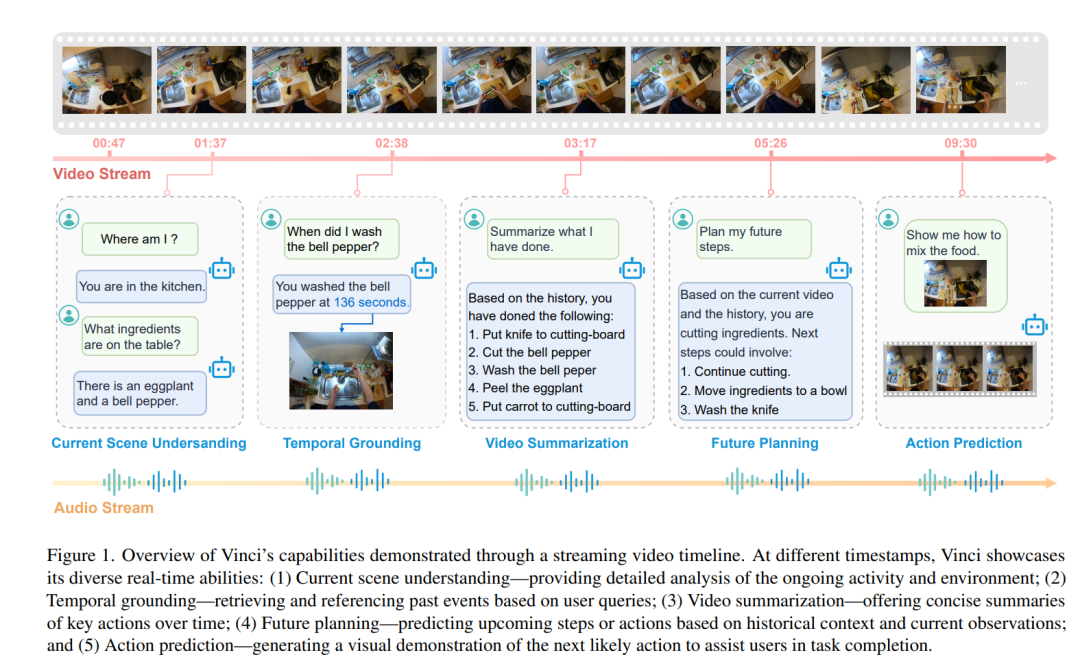
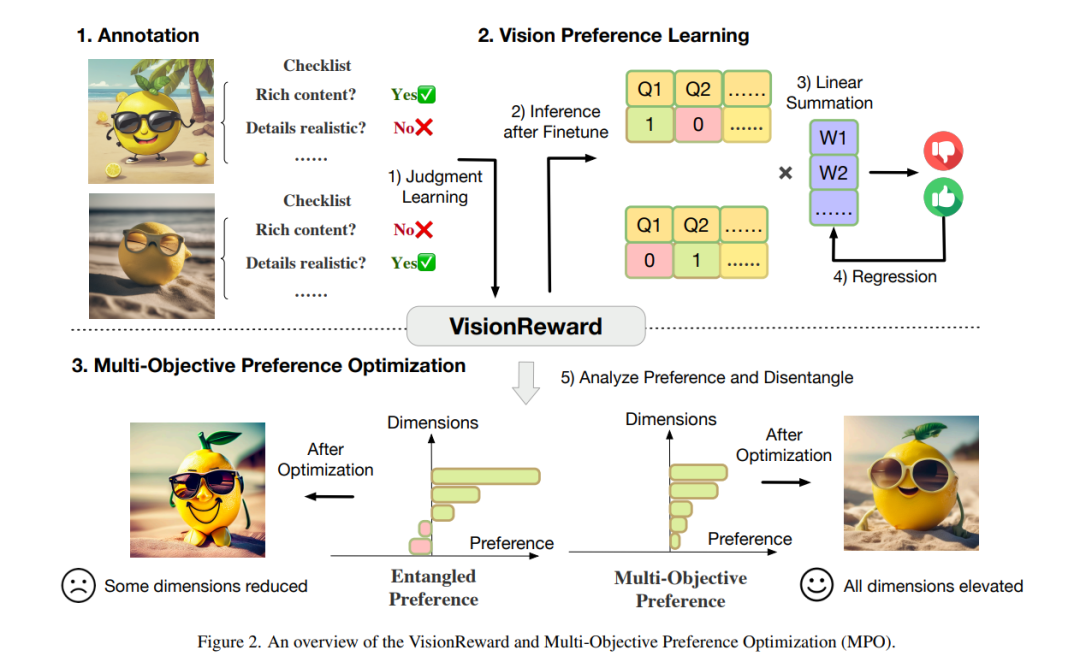
https://arxiv.org/abs/2412.20800 ResearchFlow链接:https://rflow.ai/flow/7a5312a6-ba9c-4a04-817f-4d2434040d5a Vinci: A Real-time Embodied Smart Assistant based on Egocentric Vision-Language Model 本文介绍了一个名为 Vinci 的实时智能助手系统,基于 EgoVideo-VL 这一新训练的自我中心视觉语言模型,旨在为便携设备(如可穿戴摄像机和智能手机)提供无缝交互体验。Vinci 解决了当前自我中心视觉语言系统中的几个关键问题,包括实时处理的限制、历史上下文的保持以及任务描述与可操作指导之间的差距。 Vinci 的主要创新在于其能够实时处理长视频流,使用户通过语音命令与系统互动,系统不仅可以回答当前的问题,还能参考历史上下文提供回答。这一功能通过将记忆模块集成到 EgoVideo-VL 模型中实现,该模块会记录视频时间戳和文本描述,确保用户活动和环境事件的持续记录。此外,Vinci 还可以生成可视化的 如何做 演示,提供详细的任务指导,尤其适用于需要视觉支持的复杂任务。 Vinci 的架构包括多个集成模块:一个输入模块,用于从便携设备实时流式传输视频和音频;一个后端服务器,用于处理和生成响应;以及一个视频生成模块,用于创建视觉演示。记忆模块增强了系统回顾过去互动的能力,并提供上下文感知的响应。前端设备与后端服务器之间的通信通过 HTTP 服务进行,确保数据交换的高效性。 本研究的主要贡献包括 Vinci 在实时视频处理、历史上下文集成、语音交互的无缝性以及视频生成方面的创新。这些特性使 Vinci 能够在动态的真实场景中提供强大且上下文感知的帮助。本文还通过发布模型参数和完整的部署源代码,为自我中心 AI 系统的研究和开发提供了重要的资源,旨在激发该领域的进一步创新与应用。 https://arxiv.org/abs/2412.21080 ResearchFlow链接:https://rflow.ai/flow/a0052b17-2a1d-42d2-9a47-30e3158f4b27 VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation 本文提出了一种针对文本到视觉生成(包括图像和视频生成)的新方法,旨在解决当前基于人类反馈的强化学习(RLHF)方法面临的几个关键挑战。随着文本到图像和文本到视频生成模型的快速发展,如何根据文本描述生成高质量的图像或视频已成为一个热门研究方向。然而,现有的RLHF方法在以下方面仍然存在显著问题:
奖励模型偏差和不可解释性:当前的奖励模型基于人类偏好进行学习,但由于存在多种因素之间的权衡,容易导致偏差和不可解释性。
视频评估困难:视频的动态质量(如运动真实感和流畅度)评估难度较大,缺乏有效的标准。
过度优化或缺乏优化:现有的RLHF方法往往导致某些因素的过度优化或忽视,最终产生次优结果。
为了解决这些问题,本文提出了一个精细化、多维度的奖励模型——VisionReward,它通过一系列判断性问题和答案,并使用线性加权来预测人类偏好。基于VisionReward,本文还提出了多目标偏好优化(MPO)算法,用于稳定优化视觉生成模型。本文的主要贡献包括:
统一的标注系统:为图像和视频生成设计了一个统一的标注系统,拆解了影响人类偏好的各种因素。针对视频评估的挑战,我们在标注任务中加入了对视频动态内容的广泛观察,如运动稳定性和质量等。该数据集包含了300万条问题,涵盖了48,000张图像和200万条问题,涵盖了33,000个视频。这为VisionReward提供了统一的训练管道。
高准确性和可解释性:我们展示了VisionReward在预测人类偏好方面的高准确性,尤其是在视频评估任务中,其性能超越了现有的VideoScore模型,提升了17.2%。
多目标偏好优化(MPO):为避免现有方法中的过度优化或某些因素的忽视,本文提出了MPO算法,用于稳定地调整视觉生成模型。实验结果表明,基于VisionReward的MPO优化比直接使用人类标注或其他奖励模型进行调优的效果更好。
https://arxiv.org/abs/2412.21059 ResearchFlow链接:https://rflow.ai/flow/15ad99c9-5bf4-43a7-b8d8-10a95671160c HuggingFace&Github PraisonAI 自我反思Agent PraisonAI 是一个具有自我反思功能的人工智能代理框架。 PraisonAI 应用程序将 PraisonAI Agents、AutoGen 和 CrewAI 结合到一个低代码解决方案中,用于构建和管理多代理 LLM 系统,重点关注简单性、定制和高效的人机协作
🔍 互联网搜索能力(使用 Crawl4AI 和 Tavily)
https://github.com/MervinPraison/PraisonAI
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/32570.html