我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
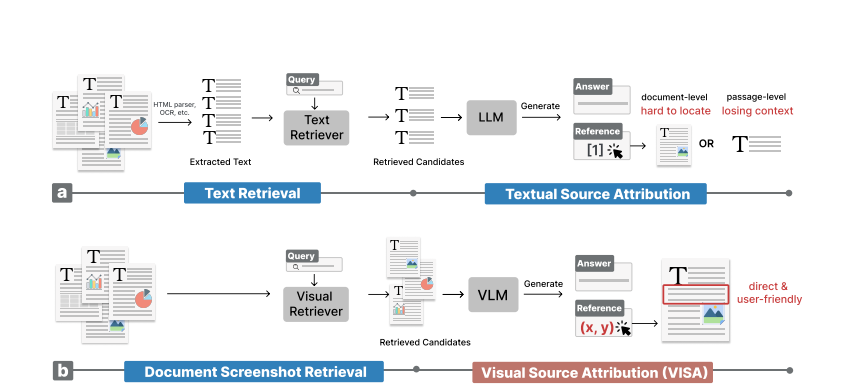
VISA: Retrieval Augmented Generation with Visual Source Attribution
带来源归因的生成对于增强检索增强生成 (RAG) 系统的可验证性非常重要。然而,RAG 中现有的方法主要将生成的内容链接到文档级引用,这使得用户很难在多个内容丰富的检索文档中找到证据。为了应对这一挑战,我们提出了带视觉来源归因的检索增强生成 (VISA),这是一种将答案生成与视觉来源归因相结合的新方法。利用大型视觉语言模型 (VLM),VISA 可以识别证据并在检索到的文档屏幕截图中使用边界框突出显示支持生成答案的确切区域。为了评估其有效性,我们整理了两个数据集:基于抓取的维基百科网页屏幕截图的 Wiki-VISA 和源自 PubLayNet 并针对医学领域量身定制的 Paper-VISA。实验结果证明了 VISA 对文档原始外观的视觉来源归因的有效性,同时也突出了改进的挑战。代码、数据和模型检查点即将发布。
https://arxiv.org/abs/2412.14457
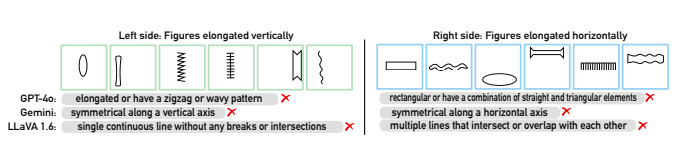
Bongard in Wonderland: Visual Puzzles that Still Make AI Go Mad?
最近,新开发的视觉语言模型 (VLM)(例如 OpenAI 的 GPT-4o)应运而生,似乎展示了跨文本和图像模态的高级推理能力。然而,这些语言引导感知和抽象推理方面的进步的深度仍未得到充分探索,而且尚不清楚这些模型是否真的能实现其雄心勃勃的承诺。为了评估进展并发现不足之处,我们进入了 Bongard 问题的仙境,这是一组经典的视觉推理难题,需要类似人类的模式识别和抽象推理能力。虽然 VLM 偶尔能够成功识别判别概念并解决一些问题,但它们经常会失败,无法理解和推理视觉概念。令人惊讶的是,即使是对人类来说似乎微不足道的基本概念,例如简单的螺旋,也带来了重大挑战。此外,即使被要求明确关注和分析这些概念,它们仍然会失败,这不仅表明它们缺乏对这些基本视觉概念的理解,而且无法推广到看不见的概念。这些观察强调了 VLM 目前的局限性,强调了类似人类的视觉推理和机器认知之间仍然存在很大差距,并强调了该领域持续创新的需求。
https://arxiv.org/abs/2410.19546
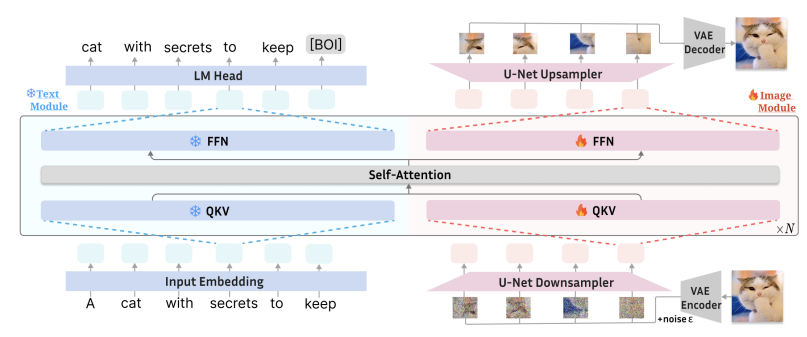
LlamaFusion: Adapting Pretrained Language Models for Multimodal Generation
我们提出了 LlamaFusion,这是一个为预训练的纯文本大型语言模型 (LLM) 提供多模态生成能力的框架,使它们能够理解和生成任意序列的文本和图像。LlamaFusion 利用现有的 Llama-3 权重来自回归处理文本,同时引入额外的并行转换器模块来处理具有扩散的图像。在训练期间,来自每种模态的数据都会被路由到其专用模块:特定于模态的前馈层、查询键值投影和规范化层独立处理每种模态,而共享的自注意力层允许跨文本和图像特征进行交互。通过冻结特定于文本的模块并仅训练特定于图像的模块,LlamaFusion 保留了纯文本 LLM 的语言能力,同时开发了强大的视觉理解和生成能力。与从头开始预训练多模态生成模型的方法相比,我们的实验表明,LlamaFusion 仅使用 50% 的 FLOP 将图像理解能力提高了 20%,将图像生成能力提高了 3.6%,同时保持了 Llama-3 的语言能力。我们还证明,该框架可以调整具有多模态生成能力的现有视觉语言模型。总体而言,该框架不仅利用了纯文本 LLM 中现有的计算投资,而且还实现了语言和视觉能力的并行开发,为高效的多模态模型开发提供了一个有希望的方向。
https://arxiv.org/abs/2412.15188
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
与较大的仅使用解码器的模型相比,仅使用编码器的 Transformer 模型(例如 BERT)在检索和分类任务中提供了出色的性能和尺寸权衡。尽管 BERT 是众多生产流程的主力,但自发布以来,其帕累托改进有限。在本文中,我们介绍了 ModernBERT,它将现代模型优化引入仅使用编码器的模型,并且与旧编码器相比实现了重大的帕累托改进。ModernBERT 模型在 2 万亿个具有原生 8192 序列长度的 token 上进行训练,在大量评估中表现出最佳结果,这些评估涵盖了各种分类任务以及不同域(包括代码)上的单向量和多向量检索。除了强大的下游性能外,ModernBERT 还是速度和内存效率最高的编码器,专为在常见 GPU 上进行推理而设计。
https://arxiv.org/abs/2412.13663
HuggingFace&Github
ModernBERT-base
ModernBERT 是一种现代化的双向编码器专用 Transformer 模型(BERT 风格),已在 2 万亿个英语和代码数据上进行预训练,原生上下文长度最多为 8,192 个标记。ModernBERT 利用了最近的架构改进,例如:旋转位置嵌入 (RoPE)用于长上下文支持。;局部-全局交替注意力机制,提高长输入的效率;取消填充和 Flash Attention可实现高效推理。ModernBERT 的原生长上下文长度使其成为需要处理长文档的任务的理想选择,例如检索、分类和大型语料库中的语义搜索。该模型是在大量文本和代码语料库上训练的,因此适用于各种下游任务,包括代码检索和混合(文本 + 代码)语义搜索。
https://huggingface.co/answerdotai/ModernBERT-base
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29051.html