我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
资讯
EMNLP’24最佳论文 EMNLP 2024最佳论文奖揭晓,共有五篇获奖,其中三篇由华人学者参与。奖项突出创新性和跨学科的研究成果,以下是五篇获奖论文的简要概述:
An image speaks a thousand words, but can everyone listen? On image transcreation for cultural relevance这篇来自CMU的论文研究图像的跨文化再创作。针对多模态翻译中的图像处理,提出了三种基于生成模型的管道,并探索如何通过LLM和检索技术改进现有图像编辑模型的文化相关性。
Towards Robust Speech Representation Learning for Thousands of Languages由CMU、上海交大等联合完成,这篇论文介绍了XEUS模型,一种针对多语言和不同声学环境的语音编码器,使用了超过100万小时的语音数据。XEUS在多种语音任务中表现优异,特别是在自动语音识别方面,成为SOTA模型。
Backward Lens: Projecting Language Model Gradients into the Vocabulary Space以色列理工学院和特拉维夫大学的团队提出了一种新的方法,通过将语言模型的梯度投射到词汇空间来揭示信息流动的机制,从而进一步推进了模型的可解释性。
Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method该论文由中科院大学等机构的学者完成,提出了一种基于散度的校准方法,用于检测文本是否属于大语言模型的预训练数据。这一方法在多种基准数据集上表现出色,优于传统的检测方法。
CoGen: Learning from Feedback with Coupled Comprehension and Generation康奈尔大学的研究团队提出了CoGen框架,结合了语言理解和生成,利用人机交互收集反馈以提升模型性能。该方法在提高生成准确性和理解准确性方面表现显著。
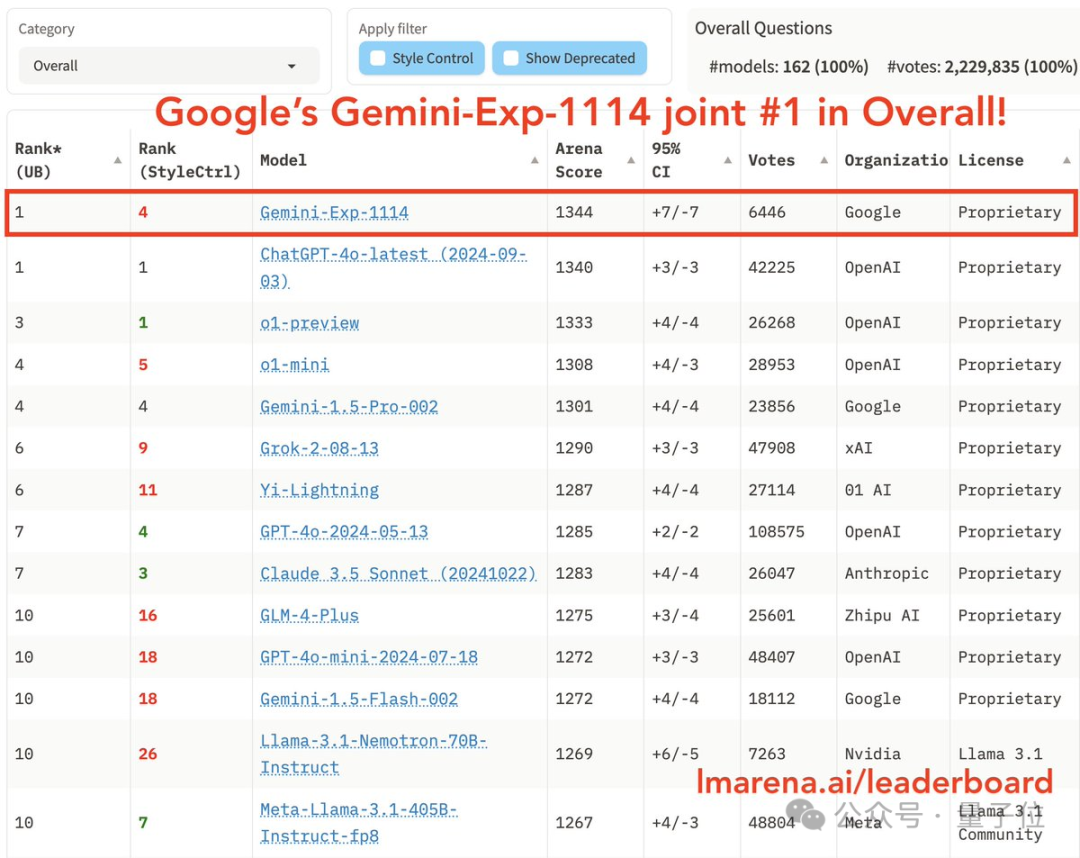
此外,EMNLP 2024还揭晓了20篇杰出论文。华人学者在其中的贡献也非常突出,特别是加州大学洛杉矶分校的Nanyun Peng教授团队,其指导的三篇论文均获奖,研究内容聚焦于大语言模型在创意叙事生成方面的能力。 新版Gemini跑分超o1登顶第一 谷歌的新版Gemini模型(Exp 1114)在最近的竞技场测试中表现出色,成功超越了OpenAI的O1模型,登顶总榜第一。根据6000多名网友的投票,Gemini不仅在数学领域与O1不相上下,还在复杂提示处理、创意写作、指令遵循、长查询处理、多轮对话等五个单项中获得第一。值得注意的是,Gemini的数学能力与O1并无明显差距,尽管O1被OpenAI描述为具备无需专门训练即可轻松应对数学奥赛问题的能力。Gemini在多个领域的胜率也表现强劲,尤其在与O1预览版和Claude-3.5的对决中,分别获得56%和62%的胜率。 Gemini-Exp 1114在风格控制、编码和写代码方面的表现相对较弱,未能跻身前三,且在风格控制功能上未能超越自家的Gemini 1.5 Pro。此外,尽管在视觉能力方面超过了GPT-4o,Gemini仍未完全解决编码和风格控制等问题。 Gemini的最大亮点之一是其32k上下文窗口的能力,比起之前的Gemini 1.5的200万上下文窗口,性能有所下降,引发了一些网友的不满。尽管如此,谷歌表示正在修复这一问题。Gemini-Exp 1114还引入了思维链(chain-of-thought)技术,提升了推理过程的透明度,使其在复杂问题上能逐步思考并给出答案。在测试中,Gemini成功回答了2024美国数学奥林匹克预选赛的题目,但也有错误发生,特别是在处理物理问题和一些基础数学题时。 目前,Gemini-Exp 1114已经可以在谷歌AI Studio体验,未来还计划提供API接口。虽然有部分网友猜测这可能是谷歌推迟推出更强大模型(如Gemini 2)的策略,早期发布一个测试版,但整体来看,Gemini-Exp 1114的表现已让不少人对谷歌的AI技术感到惊讶。 陶哲轩:计算机通用方法,往往比深奥的纯数学更能解决问题 著名数学家陶哲轩在最近的社交媒体帖子中提出了关于数学应用和问题解决的重要思考,强调了在系统设计和数学应用中找到“适度”平衡的重要性。他指出,过度简化或过度复杂化都会带来负面影响。对于大多数任务,使用相对简单但通用的数学方法往往比专门设计的复杂算法更有效。 陶哲轩以网络安全为例,阐述了过度优化的风险。密码安全的要求越复杂,可能会导致用户和服务提供商绕过这些要求,从而反而降低系统的安全性。他指出,安全设计应注重综合平衡,而不仅仅是优化单一指标,引用了“古德哈特定律”来说明过度优化单一指标可能带来的问题。比如,增强前门锁的安全性如果忽视了窗户的防护,反而会产生虚假的安全感。 在人工智能领域,陶哲轩提到强化学习的“苦涩教训”——大多数任务使用简单而通用的方法(如梯度下降和反向传播)往往效果更好。与专门设计的算法相比,通用方法依赖大量数据和计算资源,能够在多种任务中取得更大的进展。陶哲轩举例说明,在传感器网络中,使用神经网络设计模数转换器(ADC)比传统基于领域知识的电气工程方法更为高效。 此外,陶哲轩还强调在纯数学中,忽略某些看似重要的信息,进行适度的抽象,有助于问题的简化与求解。以数论为例,许多进展是通过将复杂的数学对象转化为简单、结构较少的形式来实现的。这种抽象可以帮助找到新的解决思路,但过度抽象会丧失关键信息。因此,找到合适的抽象层次至关重要。 陶哲轩总结道,应用数学家往往只需要掌握每本数学教材的前两章,后续的章节更多是为了完善和深化前面的知识。他的这些见解提醒我们,在解决问题时要简化细节,抓住问题的核心结构,避免过度复杂化或过度抽象。 通义灵码 SWE-GPT:从 静态代码建模 迈向 软件开发过程长链推理
背景与挑战
随着Devin发布,AI程序员在全球范围内迅速发展。大多数现有的AI程序员依赖闭源LLM模型(如GPT-4),而这些模型虽然强大,但其技术不具备可访问性,且存在数据隐私问题。此外,现有模型多基于静态代码数据训练,缺乏对软件开发过程中动态交互与迭代过程的理解,这影响了其在复杂任务中的实用性。为此,Lingma SWE-GPT系列通过整合软件开发过程数据进行训练,能够模拟开发者的认知过程,解决这些问题。
Lingma SWE-GPT 方法
Lingma SWE-GPT的训练方法包括三个关键阶段:
问题数据收集:使用GitHub的issue和pull request (PR)数据进行训练,确保数据的高质量与多样性。选择有一定社区活跃度的仓库,并通过API获取与问题相关的PR,确保训练数据反映真实的开发场景。
开发过程数据合成:引入SWESynInfer流程,模拟开发者的认知过程,包括仓库理解、故障定位和补丁生成。通过仿真工具如仓库结构工具、代码压缩工具等,增强模型对软件开发动态特性的理解。
模型训练:采用课程学习方法进行迭代训练,并通过拒绝采样确保合成数据的质量。数据实例根据故障定位准确性和补丁相似性进行筛选,保证训练数据符合真实开发实践。
实验结果与对比
Lingma SWE-GPT在多个基准测试中表现优异,尤其在SWE-bench Verified上,Lingma SWE-GPT 72B成功解决了30.20%的问题,接近闭源模型GPT-4的31.80%。相较于Llama 3.1 405B,Lingma SWE-GPT 72B的性能提高了22.76%。即便是较小的Lingma SWE-GPT 7B也表现出了相对于Llama 3.1 70B的优势,解决了18.20%的问题。
故障定位能力
Lingma SWE-GPT在故障定位(识别代码中的问题位置)方面表现出色。通过与其他模型(如Claude 3.5 Sonnet)的对比,Lingma SWE-GPT在代码块、函数和文件级别的定位准确率显著更高,进一步证明了其在真实开发场景中的有效性。
后续工作与扩展
未来,Lingma SWE-GPT将扩展对更多编程语言的支持,如Java、JavaScript和TypeScript,以适应更广泛的软件开发场景。同时,团队还计划增加对更多端到端软件工程任务的支持,以提升模型的通用性和实用性。
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
对话 OpenCV 之父 Gary Bradski:灾难性遗忘和持续学习是尚未解决的两大挑战
睡眠可能在生物的学习过程中扮演着“清理”外部噪音的作用,从而帮助组织和结构化知识。
你在睡梦中身处一个世界,醒来后,梦并未结束,而你连接了外部的数据源,世界模型正是通过输入并匹配外部感知而形成的。
人类还会建模世界的因果关系,换句话说,即“世界的物理法则”。所以不仅仅是“是什么”(WHAT)和“在哪里”(WHERE),还会有“为什么”(WHY)的系统。我将 AI 模型与 3D 系统结合,让摄像头拍摄的图像不仅能识别“是什么”,还能判断“在哪里”。
现阶段大多数模型的成功模式是基于大型语言模型的微调,重构一个全新的更接近生物学习机制的AI系统可以尝试SLAM(同步定位与地图构建):实现同步定位与地图构建,让机器人在探索环境的同时适应环境中的变化,遇到移动的物体时作出相应变化,实现不断的学习。
从安全角度来看,建立一个统一的数据库,记录每辆自动驾驶汽车在运行中遇到的异常情况,每次更新软件时,车企必须在模拟环境中经过所有已知和新记录的情境测试,确保在一百万英里内无事故才能在真实环境中部署新软件。
推特
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
Anthropic Console新增提示优化器功能:只需输入一个现有的提示,Claude将自动运用提示工程技术对其进行优化和改进 我们在Anthropic Console中新增了一个提示优化器功能。 只需输入一个现有的提示,Clau de将自动运用提示工程技术(如链式思维推理)对其进行优化和改进。
https://x.com/nutlope/status/1856759538809987553 ChatGPT桌面版应用程序现已向所有Windows用户开放
ChatGPT桌面版应用程序现已向所有Windows用户开放 🖥️ 通过快捷键 Alt + Space 更快访问 ChatGPT,并使用高级语音模式与电脑对话,在工作时轻松实现免提回答。 https://openai.com/chatgpt/desktop https://x.com/OpenAI/status/1857121721175998692 吴恩达分享趋势:LLMs向代理化优化转型推动性能跃升 大型语言模型(LLMs)通常被优化用于回答人们的问题,但如今有一个趋势是将模型优化为适配代理化工作流程。这将大大提升代理性能! 在ChatGPT因回答问题的巨大成功而走红后,大量LLM的开发重点放在提供良好的用户体验上。因此,LLMs被调优以回答问题(如“莎士比亚为什么写《麦克白》?”)或遵循人类提供的指令(如“解释莎士比亚为什么写《麦克白》”)。大部分用于指令调优的数据集都引导模型为人类提出的问题和指令提供更有帮助的回答,这些问题和指令往往是面向消费者的LLM所会遇到的,比如ChatGPT、Claude或Gemini等通过网页界面提供的服务。 然而,代理化工作负载需要不同的行为模式。与直接为消费者生成回应不同,AI软件在代理化工作流中可能会使用模型参与迭代流程,以反思其自身输出、使用工具、制定计划,并在多代理环境中协作。如今,各大模型开发者正越来越多地优化模型,使其能够更好地用于AI代理。 以工具使用(或函数调用)为例。如果一个LLM被问到当前的天气情况,它无法从其训练数据中推导出所需信息。这时,它可能会生成一个API调用请求以获取相关信息。在GPT-4原生支持函数调用之前,应用程序开发者已经通过编写更复杂的提示(如ReAct提示的变体)来让LLMs生成函数调用字符串,然后由一个独立的软件程序(可能通过正则表达式)解析这些字符串,决定是否需要调用某个函数。 在GPT-4以及其他许多模型原生支持函数调用后,生成这些调用变得更加可靠。如今,LLMs可以调用函数来搜索信息以增强生成(RAG)、执行代码、发送电子邮件、在线下单等。 最近,Anthropic发布了一款能够使用电脑的模型,它可以通过鼠标点击和键盘输入操作电脑(通常是虚拟机)。我很享受测试这一功能的过程。尽管其他团队已经通过提示LLMs使用电脑来开发新一代的RPA(机器人流程自动化)应用,但由主要LLM提供商推出的原生电脑使用支持是一个重大进步,这将帮助许多开发者! 1. 首先,许多开发者通过提示LLMs来实现所需的代理化行为。这种方式允许快速而丰富的探索! 2. 在少数情况下,那些从事高价值应用的开发者会微调LLMs,使其更可靠地执行特定的代理化功能。例如,即使许多LLMs原生支持函数调用,它们仍需要输入可用函数的描述,然后(希望能)生成正确的输出令牌以请求适当的函数调用。对于生成正确函数调用至关重要的任务关键型应用,通过微调模型以适配应用特定的函数调用,可以显著提高可靠性。(但请避免过早优化!目前我仍然看到很多团队在还没有花足够时间完善提示时就过早地转向微调。) 3. 最后,当某种功能(如工具使用或电脑使用)对许多开发者显得有价值时,主要的LLM提供商会将这些功能直接内置到他们的模型中。尽管OpenAI的o1-preview模型的高级推理能力对消费者有帮助,但我预计它在代理化推理和规划中会更加有用。 大多数LLMs主要被优化用于回答问题,以提供良好的消费者体验,而我们已经能够通过“嫁接”的方式将它们引入复杂的代理化工作流中以构建有价值的应用。未来,原生支持代理操作的LLMs趋势将显著提升代理性能。我相信,未来几年代理性能将在这一方向上取得巨大进展。
https://x.com/AndrewYNg/status/1857117382378164267
Runwayml分享:Jeremy Higgins导演的《迁徙》 推出杰里米·希金斯(Jeremy Higgins)导演的《迁徙》(Migration)。 这是一部动画短片,将第三代 Alpha 技术融入杰里米的传统动画制作流程。 这是“The Hundred Film Fund”发布的首个项目。
https://x.com/runwayml/status/1857072173631885586 Packer分享:AI代理托管/服务整理 AI/LLM代理的技术栈与标准LLM技术栈有显著区别。两者的关键差异在于状态管理:LLM服务平台通常是无状态的,而代理服务平台需要具备有状态性(在服务器端保留代理状态)。 https://x.com/charlespacker/status/1857105467031630220 Unitree发布升级:L2 4D激光雷达性能提升200%,售价$419 新升级发布:L2 4D激光雷达性能提升200%,售价$419 🥳 开源地址: https://github.com/unitreerobotics/point_lio_unilidar #Unitree #4DLiDAR #360LiDAR #超广角 #激光雷达 #AI #移动机器人 #四足机器人 #机器狗 #新生产力
https://x.com/UnitreeRobotics/status/1856986819038253396 产品 ZEPIC ZEPIC 是一款全新的客户数据和互动平台,可以帮助企业整合数据,创建个性化的客户体验。它允许营销人员独立设置和管理各种数据,利用内置的 AI 引擎 ZENIE 快速生成个性化的 WhatsApp 和电子邮件活动。ZEPIC 强调隐私和安全,确保符合 ISO、SOC 2 和 GDPR 标准,并提供实时分析工具,帮助团队优化营销策略。 BuildShip V2 BuildShip V2 是一款全新的可视化开发工具,可以简化 API 和 AI 工作流的创建。新版本引入了无限画布、实时触发器、增强的测试与错误报告等企业级功能,支持灵活的信用计费模式。用户可以在更大的范围内探索创意,并享受透明的使用报告。 投融资 Tessl完成1.25亿美元融资,估值达到5亿美元,致力于打造AI编写维护代码平台 Tessl是一家位于伦敦的初创公司,旨在通过人工智能帮助开发者创建和维护软件。公司于2024年11月完成了1.25亿美元的融资,分为种子轮和A轮融资,估值已突破5亿美元,具体为7.5亿美元。此次融资由Index Ventures主导,Accel、GV(谷歌风险投资)和Boldstart参与。GV和Boldstart共同主导了种子轮。 Tessl的创始人兼首席执行官Guy Podjarny,曾创办并领导了网络安全公司Snyk,并在Akamai担任CTO。他的经验和背景吸引了顶级投资者的关注。Tessl的目标是开发一个“AI原生”平台,允许开发团队通过自然语言或代码提供需求,AI将自动生成和维护代码。该平台还支持在沙箱环境中进行测试,以便开发者能够发现问题并进行修复。 尽管Tessl尚未正式推出其产品,计划在明年初发布,但它的融资和高估值已经显示出市场对其理念的强烈兴趣。Podjarny提到,Tessl的起步并不会涉及复杂的应用,初期将聚焦于相对简单的软件开发,并计划逐步扩展至更多的应用场景。 Tessl的核心价值在于其自动化代码维护能力,投资者认为,随着AI生成代码的普及,代码的维护和更新将变得更加重要。Podjarny表示,Tessl将支持多种编程语言,并计划与其他AI编程助手平台合作,进一步拓展其生态系统。 公司官网:https://www.tessl.io/ https://techcrunch.com/2024/11/14/tessl-raises-125m-at-at-500m-valuation-to-build-ai-that-writes-and-maintains-code/ Tiger Global支持的InVideo推出基于生成AI的视频创作功能 印度视频编辑平台InVideo宣布推出其生成AI驱动的视频创作功能,该功能使用户能够通过文本提示生成视频剪辑。此功能被称为InVideo v3.0,支持多种风格的视频制作,包括真人、动画或动漫,并且生成的视频可以导出为适用于YouTube、Shorts/Reels和LinkedIn等平台的格式。用户还可以通过修改提示来编辑这些视频,调整视频的某些部分。 InVideo并未开发自己的生成模型,而是采用了多个不同的模型组合来处理提示并生成视频。InVideo的共同创始人兼首席执行官Sanket Shah表示,理论上生成的视频长度没有上限,但用户的生成次数会受到账户余额的限制。目前,平台没有提供免费的使用层级。 为支持这一新功能,公司推出了一个新的付费计划——“生成计划”,用户每月支付120美元即可生成15分钟的视频。此外,用户还可以按每分钟8到10美元的价格购买额外的生成时间。 InVideo的目标用户群体为个人、创作者和小型企业,而不像一些竞争对手(如Captions、D-ID和Lightricks)那样专注于电影制作人、广告公司和销售团队。Shah表示,与其他视频编辑工具相比,InVideo在创建AI生成视频时具有更简单的界面。 InVideo的前景看似光明,目前公司拥有400万月活跃用户,在过去30天内生成了700万个视频。该公司在2021年完成了一轮3500万美元的融资,投资方包括Greenoaks、Tiger Global和Peak XV,目前公司仍有2500万美元的现金储备,并表示“烧钱”情况较轻。 Shah还透露,InVideo预计今年的营收将达到5000万美元,并计划在未来几个月内寻找合适的合作伙伴。 https://techcrunch.com/2024/11/14/tiger-global-backed-invideo-introduces-gen-ai-based-video-creation/ Mach9获得1200万美元种子轮融资,推出AI驱动的基础设施数据分析工具 Mach9是一家致力于利用AI改善基础设施维护和管理的初创公司,近日宣布完成1200万美元的种子轮融资。此次融资由Quiet Capital主导,Overmatch Ventures以及一系列知名投资者,包括Cruise创始人Kyle Vogt、前Autodesk CEO Amar Hanspal、Adobe首席产品官Scott Belsky及前DoorDash高管Gokul Rajaram等参与。 Mach9的核心产品——Digital Surveyor,能够通过移动激光雷达(LiDAR)扫描技术,自动转换和分析2D与3D工程模型。该工具显著降低了基础设施公司在进行设施勘测和管理时的成本和时间。通过AI技术,Digital Surveyor能够自动识别20多种基础设施特征,如电力杆、交通信号灯和道路标识,且比传统人工勘测方法更高效。 目前,Mach9的客户包括美国和加拿大的多家知名基础设施公司与工程服务公司,如Michael Baker International、POWER Engineers、Langan和Fibersmith等。公司创始人兼CEO Alexander Baikovitz表示,借助更精确的地理空间数据和地图,基础设施运营商能够及时发现问题并进行改进,尤其是在极端天气事件后,能够快速获取关键信息。 Mach9最初计划通过硬件解决方案来收集地理空间数据,但在与客户交流后,决定将重点转向如何将庞大的数据转化为有价值的见解,进而推动其软件Digital Surveyor的发展。该工具大大提高了勘测效率,用户能够在不到10分钟的时间内,审核和确认每英里道路上的基础设施数据,极大缩短了传统人工识别所需的几天时间。 公司计划利用这笔资金扩大其14人的团队,进一步完善产品,并逐步增加可识别的基础设施特征,从目前的20多种扩展到未来的数百种。 公司官网:https://www.mach9.io/ https://techcrunch.com/2024/11/14/mach9-is-equipping-infrastructure-operators-with-better-information/ — END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/11/21697.html