我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
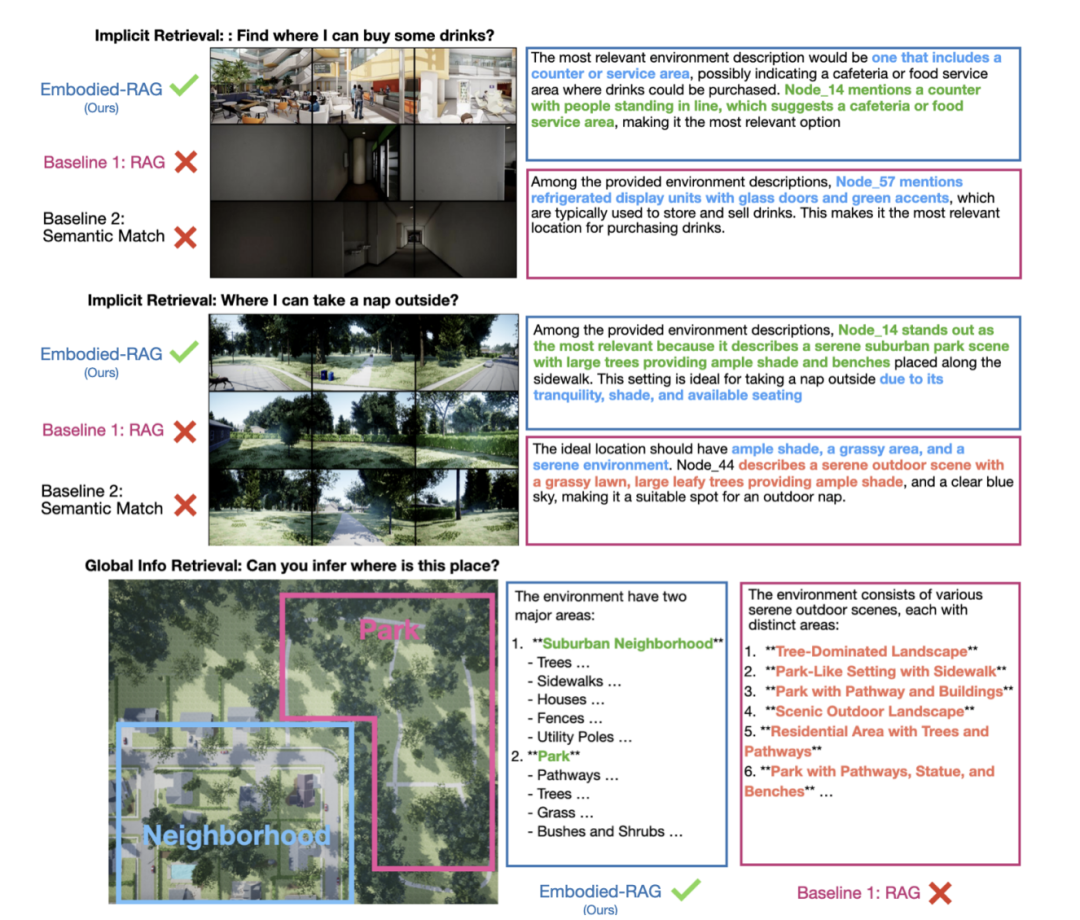
论文 Embodied-RAG: General Non-parametric Embodied Memory for Retrieval and Generation 机器人探索和学习的范围是没有限制的,但所有这些知识都需要可搜索和可操作。在语言研究中,检索增强生成 (RAG) 已成为大规模非参数知识的工作场所,但现有技术无法直接转移到具身领域,因为具身领域是多模态的,数据高度相关,感知需要抽象。 为了应对这些挑战,本研究引入了 Embodied-RAG,这是一个框架,它使用非参数记忆系统增强了具身代理的基础模型,该系统能够自主构建用于导航和语言生成的分层知识。Embodied-RAG 可处理各种环境和查询类型的各种空间和语义分辨率,无论是针对特定对象还是整体氛围描述。从本质上讲,Embodied-RAG 的记忆结构为语义森林,以不同细节级别存储语言描述。这种分层组织使系统能够跨不同的机器人平台高效地生成上下文相关的输出。研究证明 Embodied-RAG 有效地将 RAG 连接到机器人领域,成功处理了 19 个环境中的 200 多个解释和导航查询,凸显了其作为具身代理通用非参数系统的前景。
https://arxiv.org/abs/2409.18313 Law of the Weakest Link: Cross Capabilities of Large Language Models 大型语言模型 (LLM) 的开发和评估主要侧重于个体能力。然而,这忽略了现实世界任务通常需要的跨不同专业技能的多种能力的交集,我们称之为交叉能力。为了系统地探索这一概念,本研究首先定义七种核心个体能力,然后将它们配对形成七种常见的交叉能力,每种能力都由手动构建的分类法支持。基于这些定义,本研究引入了 CrossEval,这是一个基准,包含 1,400 个人工注释的提示,每个个体和交叉能力有 100 个提示。为了确保可靠的评估,本研究让专家注释者评估 4,200 个模型响应,收集 8,400 个带有详细解释的人工评分作为参考示例。我们的研究结果表明,无论是在静态评估还是在增强特定能力的尝试中,当前的 LLM 始终表现出“最弱环节定律”,其中交叉能力的表现受到最薄弱组件的严重制约。具体而言,在 17 个模型的 58 个交叉能力得分中,有 38 个得分低于所有单个能力,而有 20 个得分介于强弱之间,但更接近较弱的能力。这些结果凸显了 LLM 在交叉能力任务中的表现不佳,因此,识别和改进最薄弱的能力是未来研究的关键重点,以优化复杂、多维场景中的表现。
https://arxiv.org/abs/2409.19951 Hyper-Connections 本研究提出了超连接,这是一种简单而有效的方法,可以作为残差连接的替代方案。这种方法专门解决了残差连接变体中观察到的常见缺点,例如梯度消失和表示崩溃之间的跷跷板效应。从理论上讲,超连接允许网络调整不同深度特征之间的连接强度并动态重新排列层。我们进行了实验,重点是大型语言模型(包括密集和稀疏模型)的预训练,其中超连接比残差连接显示出显着的性能改进。在视觉任务上进行的其他实验也证明了类似的改进。本研究预计这种方法将广泛应用于各种人工智能问题并受益匪浅。
https://arxiv.org/abs/2409.19606 Introducing the Realtime API 今天,OpenAI 推出了 Realtime API 的公开测试版,让所有付费开发者都能在其应用中打造低延迟、多模式体验。与 ChatGPT的高级语音模式类似,Realtime API 支持使用六种预设声音进行自然的语音对语音对话API 中已经支持。 OpenAI 还在Chat Completions API中引入了音频输入和输出以支持不需要 Realtime API 的低延迟优势的用例。通过此更新,开发人员可以将任何文本或音频输入传递到GPT-40,并让模型以他们选择的文本、音频或两者做出响应。 从语言应用和教育软件到客户支持体验,开发人员一直在利用语音体验与用户建立联系。现在有了 Realtime API,并且很快会在 Chat Completions API 中增加音频功能,开发人员不再需要拼凑多个模型来支持这些体验。相反,只需调用一个 API 即可构建自然的对话体验。
https://openai.com/index/introducing-the-realtime-api/ MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning 本研究推出了 MM1.5,这是一系列新的多模态大型语言模型 (MLLM),旨在增强文本丰富的图像理解、视觉引用和基础以及多图像推理的能力。在 MM1 架构的基础上,MM1.5 采用以数据为中心的方法进行模型训练,系统地探索整个模型训练生命周期中各种数据混合的影响。这包括用于持续预训练的高质量 OCR 数据和合成字幕,以及用于监督微调的优化视觉指令调整数据混合。本研究的模型参数范围从 1B 到 30B,涵盖密集和混合专家 (MoE) 变体,并证明即使在小规模(1B 和 3B)下,精心的数据管理和训练策略也可以产生强大的性能。此外,本研究还推出了两个专门的变体:专为视频理解而设计的 MM1.5-Video 和专为移动 UI 理解量身定制的 MM1.5-UI。通过广泛的实证研究和消融,本研究对训练过程和决策提供了详细的见解,为最终设计提供了参考,为未来 MLLM 开发的研究提供了宝贵的指导。
https://arxiv.org/abs/2409.20566 Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems (Allen Zhu) Allen Zhu 在 YouTube 上更新了一条关于 Physics of Language Models: Part 2.2 的视频,涵盖了许多技术细节。 视频链接为:https://www.youtube.com/watch?v=yBgxxvQ76_E
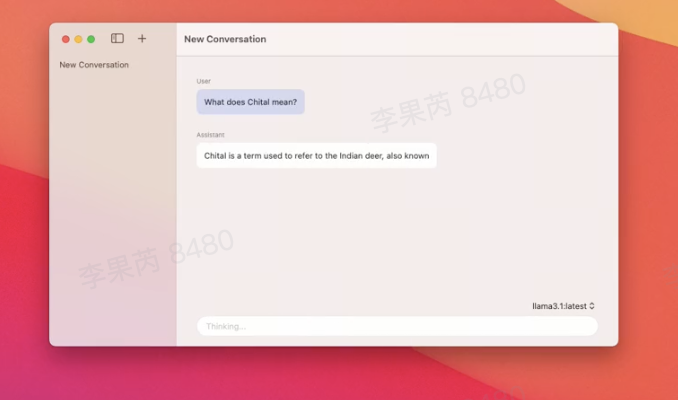
https://x.com/ZeyuanAllenZhu/status/1840386985976098834 Chital Chital 是一款原生 macOS 应用,允许用户与 Ollama 模型聊天,具备低内存使用、快速启动、多个聊天线程支持、模型切换、Markdown 支持及自动总结聊天标题等功能。它基于 SwiftUI 和 Ollama-client。
https://github.com/sheshbabu/Chital BaseAI BaseAI 是一个 AI 框架,可以帮助开发者构建可组合的 AI 驱动 LLM 产品。它支持在本地机器上开发集成智能工具和具有记忆的 AI 代理,使用的技术栈包括 TypeScript、MDX、JavaScript 和 CSS。
https://github.com/LangbaseInc/BaseAI
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21451.html