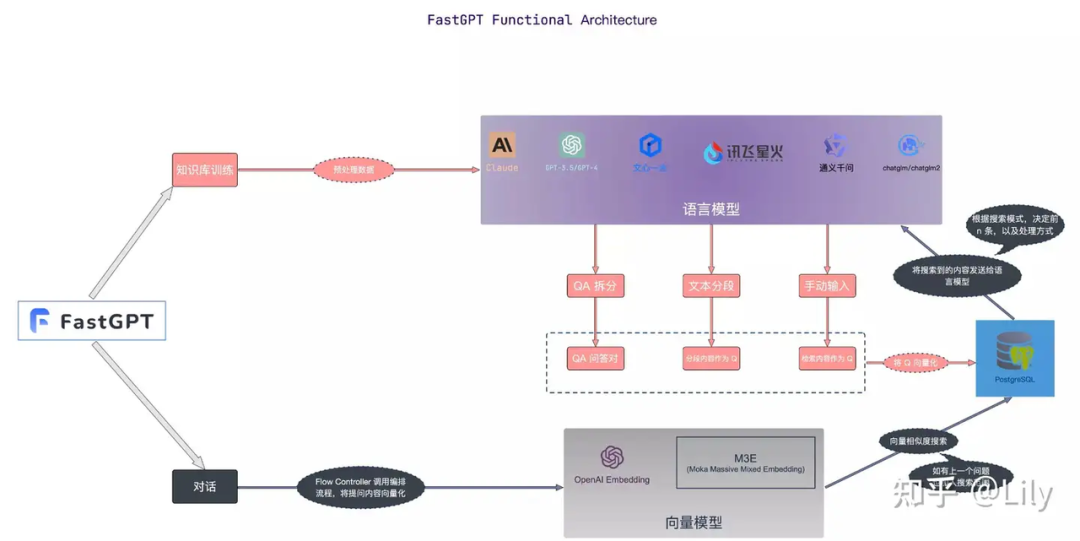
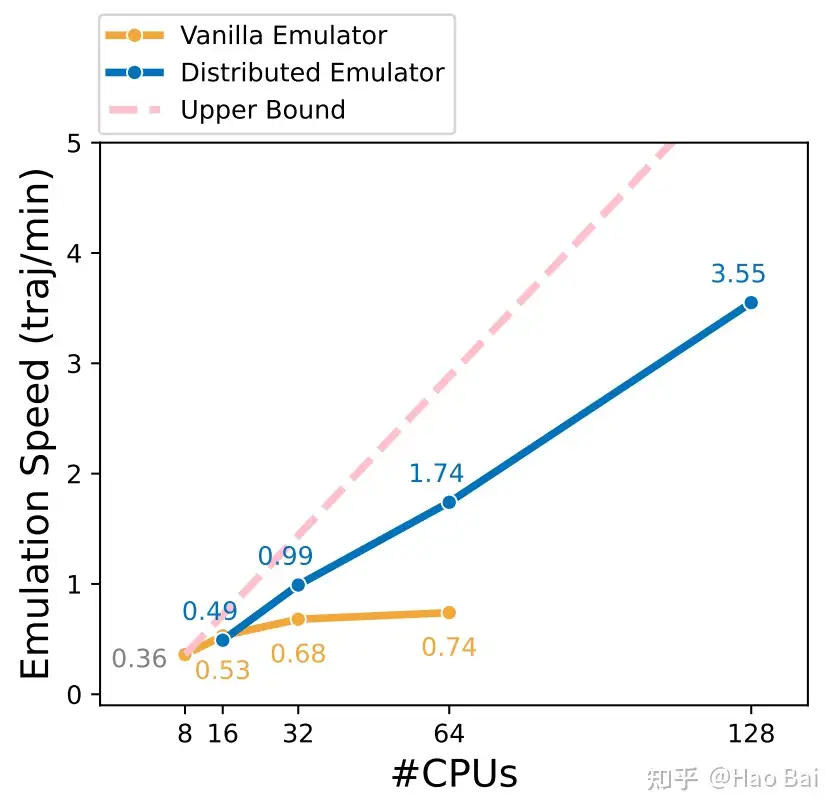
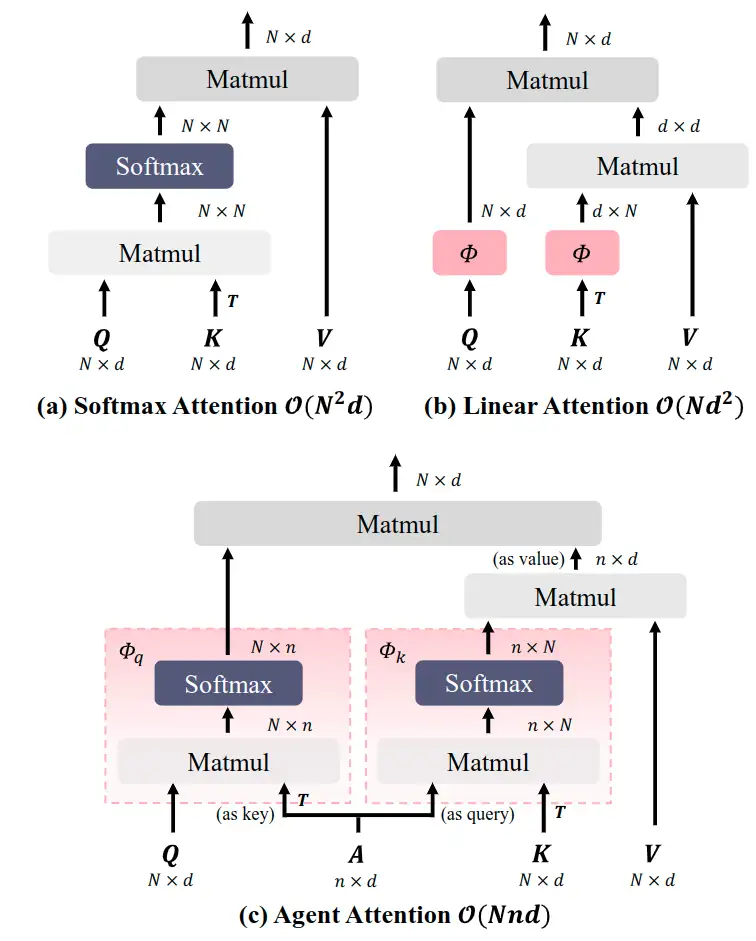
昇腾 AI 原生创新算子挑战赛 S1是一个旨在优化 AI 算子性能的竞赛。竞赛分为初赛和决赛两个阶段,通过对算子进行原生优化,提高其在昇腾处理器上的执行效率。初赛要求参赛者对指定算子进行优化,并通过评测系统评估性能。评测标准包括性能提升比例和最终性能排名。决赛则是邀请初赛中表现最佳的选手进行线下深度优化比赛。竞赛提供了算子优化的学习资源,包括基础知识、实践技巧和高级优化方法。重点强调技术细节,如算子内存访问优化、计算密集型操作简化、并行化处理等,以实现更高效的 AI 计算。此外,竞赛鼓励参赛者探索创新的优化策略,以期在未来的 AI 领域中实现更大的性能突破。https://zhuanlan.zhihu.com/p/701340321?utm_psn=178824155886218854406
华泰 | 电子:AI大模型需要什么样的硬件?
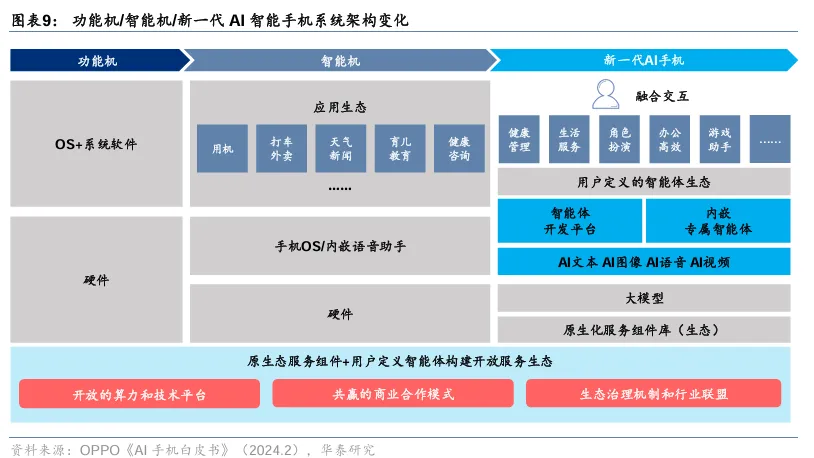
AI 大模型技术的快速发展对硬件产品提出了新的要求。在技术细节上,AI 大模型需要更高的算力支持,这导致了 SoC 中 NPU 算力的提升和存储容量的扩展。例如,AI PC 的推出需要具备 NPU 提供的边缘算力能力,以及内置大模型的能力。在软件层面,AI 大模型的应用推动了系统架构和应用方面的匹配,如 AI 智能手机的智能体开发平台和专属智能体的提供。此外,AI 大模型在具身智能、自动驾驶和人形机器人等领域的应用,涉及到感知、决策和控制等多个环节的技术细节,这些细节包括但不限于大模型的多模态能力、运动控制算法的优化以及硬件级的安全芯片的使用。在云计算方面,AI 大模型的部署和服务化,如 MaaS 模式,也依赖于高效的算力和数据处理技术。https://mp.weixin.qq.com/s/3sbi_YueMM0z03OXOKcVgQHuggingFace&Github 01
DiffSynth-Studio是一个基于扩散模型的视频合成框架,提供了多种创新性功能,包括视频合成、去闪烁、卡通风格渲染等。它重构了文本编码器、UNet、VAE等核心架构,在保持与开源社区模型兼容的同时,也大幅提高了计算性能。DiffSynth-Studio支持多种先进的扩散模型,如Stable Diffusion、ControlNet、Stable Video Diffusion等,并且还提出了ExVideo等新技术来增强视频生成的能力。