


https://arxiv.org/abs/2407.15892
贡献者:
Cheng Luo, Jiawei Zhao, Zhuoming Chen, Beidi Chen, Anima Anandkumar
-
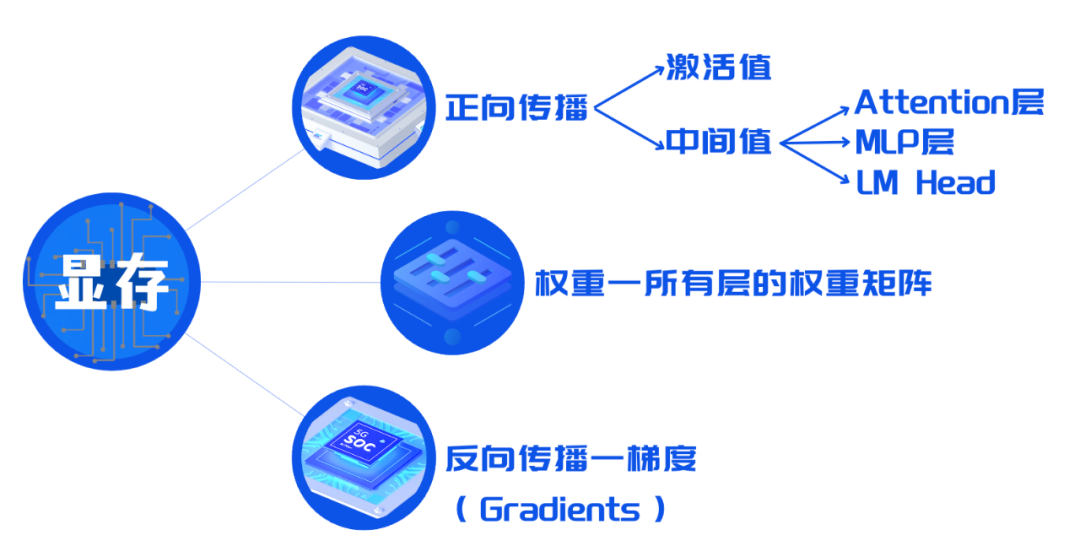
权重:模型的参数,包括所有层的权重矩阵,需要在训练前加载到显存中。 -
正向传播时需要储存: -
激活值(Activations):计算并存储每层的激活,这些值需要保存以便于在反向传播时计算梯度。
-
中间值(Intermediate Values)——计算时每一层时都需要储存:在模型的不同层,特别是多头自注意力(Multi-Head Attention)层和多层感知器(MLP)层中,计算过程中会产生中间值,如Q(Query)、K(Key)、V(Value)张量,以及MLP层的中间线性变换结果。 拆解开来主要是: -
Transformer 中的 Attention 层,计算 QKV 和注意力矩阵; -
Transformer 中的 MLP 层,将序列嵌入维度放大再缩小; -
LM Head (Language Modeling Head)将嵌入映射为 logits,之后计算 loss / 下一个 token。 -
反向传播时需要计算并存储:梯度(Gradients)——在反向传播过程中计算得到的模型权重的梯度,用于更新模型参数,保持优化器的状态等等。
Innovation
-
直接计算 Attention 会产生 NxN 大小的注意力矩阵
-
MLP 层也需要将嵌入维度放大四倍左右
-
LM Head 的映射会产生几万到几十万维度的矩阵,因为要计算整个词表中每个单词的概率
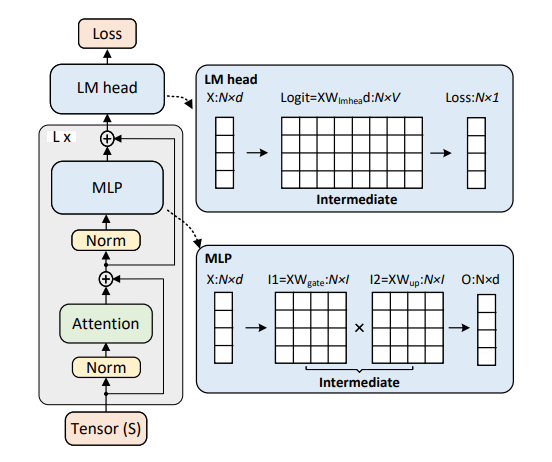
FlashAttention 其实就在使用这个技巧,因为 Attention 的中间状态太大了,随着序列长度二次方增长谁也受不了。随着 Attention 的中间状态被 FlashAttention 和 Ulysses 打下来,我们自然就盯上其他中间状态了。

MLP层:Llama3 的 MLP 层有三个线性层 Wgate,Wup,Wdown。前向计算过程为:
• 首先将 N*d 大小的序列矩阵通过 Wgate, Wup 放大为两个 N*l 的矩阵
• 然后两个矩阵逐元素点乘,最后通过 Wdown 缩小为原来的 N*d 大小。
汇总的过程就很简单,直接在序列维度拼接就可以。
MST 没有改变 FLOP,但会增加 HBM 访问次数,标准 MLP 的访问次数为 Θ (Nd+NI+dI),而 MST 的访问次数为 Θ (Nd+NI+dIM)。标准 LM Head 的次数是 Θ (Nd+NI+dV),而 MST 下这个数字是 Θ (Nd+NI+dVM)。如果序列长度很短,中间状态占主导, dI,dV 占主导,MST会降低 GPU 显存的访问量。
-
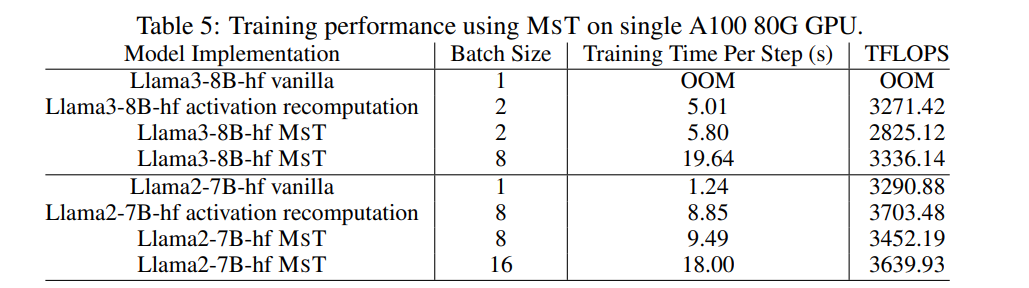
Loss 基本没有损失,Llama 3 8B 上最大序列长度是基本实现的12-20倍,激活重计算的1.8-4倍; 
-
计算速度有些许损失;
-
峰值内存下降了很多。
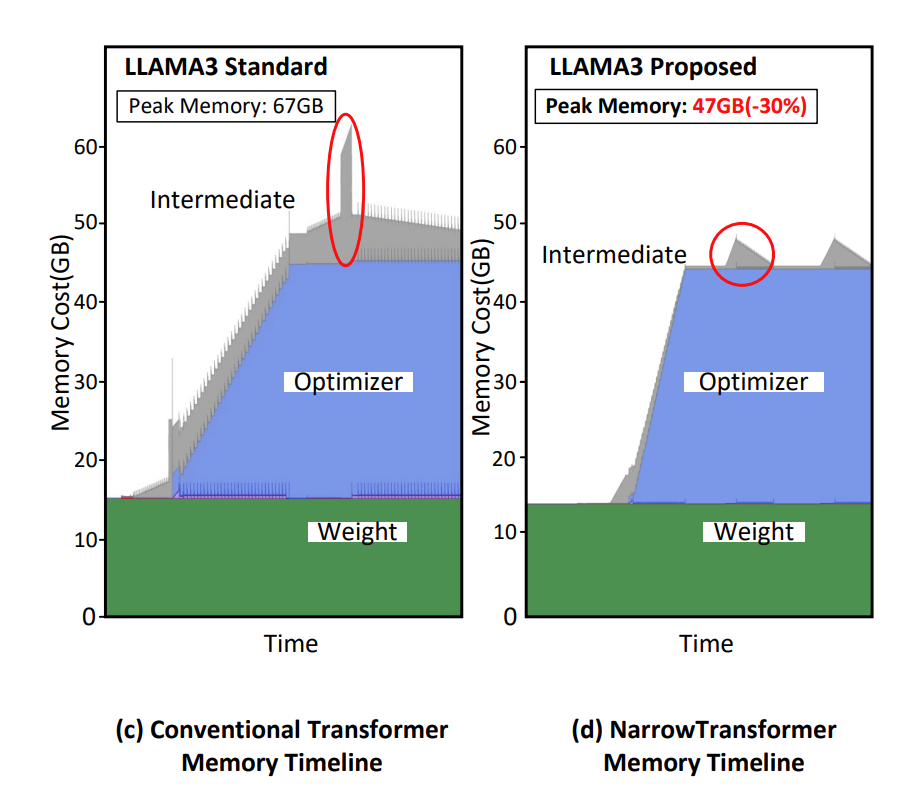
结果分析:
-
MST通用性和易用性:MST是完全通用的,并且可以轻松集成到现有的LLM训练框架中,只需最小的代码更改。 -
分布式训练支持:MST可以与DeepSpeed-Ulysses等技术一起工作,支持按GPU数量线性扩展序列长度。 -
MST的局限性和未来的发展方向:例如将方法编译到CUDA以提高性能和内存效率,以及在小序列训练中可能出现的性能下降问题。
后续思考
-
模型规模的增大和词表的扩展(大词表):传统的串行计算方法可能无法满足效率需求,长序列下模型训练和推理会出现新的瓶颈,需要从硬件出发设计算法进行并行优化,如利用现代硬件(如GPU、TPU)的并行处理能力,可以显著加速模型的训练和推理过程。
-
分块计算:减少中间状态的思想非常简单但也非常好用,可以优化优化器的中间状态,值得继续推广
本周日,我们有幸邀请到了本文的作者之一Beidi Chen与我们共同探索更多长文本生成的困境与机遇。欢迎大家来参加我们的活动。

嘉宾信息

主要研究方向:
Efficient AI,特别关注基于目前硬件设计及优化算法,以现实问题为目标加速大规模机器学习系统。代表作包括H2O, Streaming LLM, Monarch, Pixelated Butterfly等。
学术成就:
陈教授在机器学习领域的成就非常显著,她在2022年和2023年的ICML会议上分别发表了多篇有影响力的论文,包括FlexGen、StreamingLLM和DejaVu等,这些研究成果在大型语言模型的高效推理和训练方面取得了显著进展。
她还曾获得ICML 2022的杰出论文奖,是对Monarch矩阵设计的贡献的认可。

小编寄语

大模型空间站再次感谢各位朋友的支持!
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13833.html