欢迎观看大模型日报 , 进 入 大 模 型 日 报 群 和 空 间 站(活动录屏复盘聚集地) 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
推特 Shumer评价LlaMA3:我们就会拥有一个比 Opus 更强大的、完全开源的模型! 这个模型的 400 亿参数以上版本**已经和 Claude 3 Opus 不相上下**,而且还在继续训练。 很快,我们就会拥有一个比 Opus 更强大的、完全开源的模型。 https://x.com/mattshumer_/status/1780994395128451358 Llama3上线VSCode Copilot,Daniel San分享演示视频 Llama 3 作为 VSCode 中的 Copilot 🤩 让我来给你演示如何连接 Meta 今天发布的这个惊艳的模型! https://x.com/dani_avila7/status/1781061220495138907
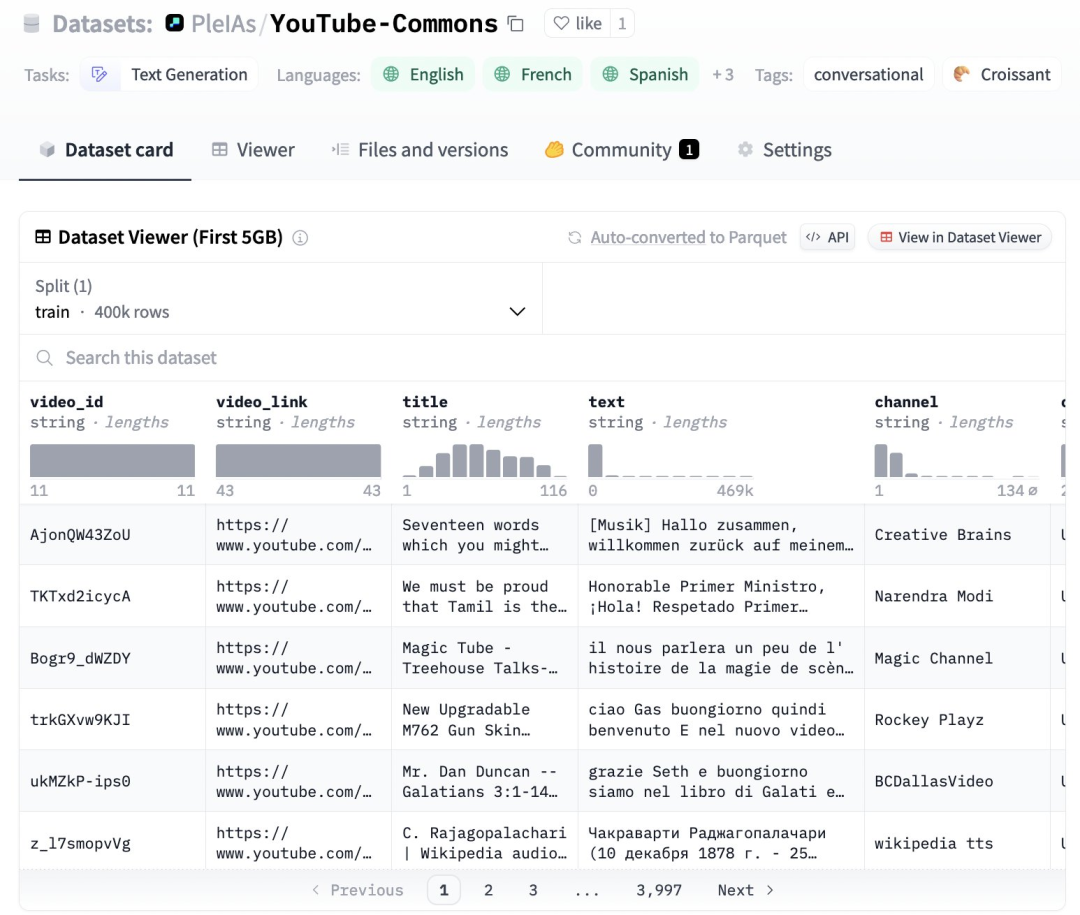
Daniel Han分享:为 Llama-3 8B 模型制作了一个 Colab 笔记本,15万亿 tokens 为 Llama-3 8B 模型制作了一个 Colab 笔记本!使用了 15 万亿 tokens!所以现在 @UnslothAI 已经支持它了!使用免费的 T4 GPU。 正在进行基准测试,但是比 HF+FA2 快大约 2 倍,内存使用减少了 80%!支持的上下文长度是 HF+FA2 的 4 倍。而且原生推理速度提高了 2 倍。 https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp?usp=sharing https://x.com/danielhanchen/status/1781024799227285799 FoundationCap分享两类自动化领域:有 4.6 万亿美元的工作可以实现自动化 我们 @FoundationCap 认为有 4.6 万亿美元的工作可以实现自动化。AI 公司正在引领从软件即服务(SaaS)向服务即软件(Service-as-Software)的转变,颠覆了 SaaS 的本质。 1.)全球就业岗位的薪资(销售和营销、软件工程、安全和人力资源方面的 2.3 万亿美元) 2.)外包服务和工资支出——包括 IT 服务和业务流程服务(根据 Gartner 的数据,为 2.3 万亿美元) 在软件业务中,公司可能出售对其平台或工具的访问权,但客户仍然要负责使用该工具来实现预期的结果。 在服务业务中,实现预期结果的责任在于销售服务的公司。 https://x.com/JayaGup10/status/1781060033645830563 Pleias在Huggingface 上发布开放语料库,包含200 万个知识共享许可Youtube视频 pleias 在 Huggingface 上发布了一个巨大的开放语料库,包含 200 万个知识共享(CC-By)许可的 Youtube 视频。YouTube-Commons 包含多种语言的 300 亿个单词的音频转录,很快还会有其他模态 https://huggingface.co/datasets/PleIAs/YouTube-Commons https://x.com/Dorialexander/status/1780959636306481476 Omkaar分享简单分布式训练模块,可以在三台 M1 MacBook 上训练一个视觉模型 gpu 资源不足?我写了一个简单的分布式训练模块,可以在三台 M1 MacBook 上训练一个视觉模型。它是开源的!我本想为 M 系列 Mac 构建一个分布式训练工具,但我遇到了两个障碍:网络延迟非常高,而且我的朋友们在考试季不愿意借出他们的 MacBook(大笑)。我把它改成了一个联邦学习模块(网络成本可以接受)。它还需要更多的调整,比如移除集中式数据存储和压缩负载,但已经完成了 90%:)所以欢迎贡献者加入。联邦学习是一个很难投入生产的问题……但理解起来并不难。感谢来自 @flwrlabs(正在招聘!)的 @jafermarq 给我提供优化建议。有问题吗?尽管问吧:) https://x.com/omkizzy/status/1780991398696669460
吴恩达分享多智能体协作:构建复杂 AI 应用的新范式 多智能体协作已成为一种关键的 AI 代理设计模式。面对像编写软件这样复杂的任务,多智能体方法会将任务分解为由不同角色执行的子任务——比如软件工程师、产品经理、设计师、QA(质量保证)工程师等等——让不同的智能体完成不同的子任务。 不同的智能体可以通过提示同一个 LLM(或者如果你愿意,不同的 LLM)来执行不同的任务。例如,为了构建一个软件工程师智能体,我们可以提示 LLM:”你是编写清晰、高效代码的专家。编写代码来执行任务……”。 尽管我们对同一个 LLM 进行了多次调用,但使用多个智能体的编程抽象似乎有点违反直觉。我想提供几个原因:
它很有效!许多团队使用这种方法获得了良好的结果,没有什么比结果更重要了!此外,消融研究(例如,在下面引用的 AutoGen 论文中)表明,多个智能体比单个智能体具有更优越的性能。
尽管如今一些 LLM 可以接受非常长的输入上下文(例如,Gemini 1.5 Pro 接受 100 万个 tokens),但它们真正理解冗长、复杂输入的能力参差不齐。一种代理工作流程,即提示 LLM 一次专注于一件事,可以提供更好的性能。通过告诉它应该在什么时候扮演软件工程师,我们还可以指定该子任务中什么是重要的:例如,上面的提示强调了清晰、高效的代码,而不是可扩展和高度安全的代码。通过将整体任务分解为子任务,我们可以更好地优化子任务。
也许最重要的是,多智能体设计模式为我们开发人员提供了一个框架,用于将复杂任务分解为子任务。在编写在单个 CPU 上运行的代码时,我们经常将程序分解为不同的进程或线程。这是一种有用的抽象,让我们可以将任务(如实现 Web 浏览器)分解为更容易编码的子任务。我发现思考多智能体角色是一个有用的抽象。
在许多公司,管理者通常决定雇用什么角色,然后如何将复杂的项目(如编写大型软件或准备研究报告)分解为更小的任务,分配给具有不同专业知识的员工。使用多个智能体是类似的。每个智能体实现自己的工作流,有自己的记忆(这本身就是一个在代理技术中快速发展的领域——智能体如何记住足够多的过去交互以便在即将到来的交互中表现更好?),并可能请求其他智能体寻求帮助。智能体本身也可以参与规划和工具使用。这导致智能体之间 LLM 调用和消息传递的喧嚣,可能导致非常复杂的工作流程。 虽然管理人很难,但这是一个足够熟悉的概念,它为我们提供了一个思考框架,关于如何”雇用”AI 智能体并为其分配任务。幸运的是,管理不善一个 AI 智能体造成的损害远低于管理不善人类! 新兴的框架如 AutoGen、Crew AI 和 LangGraph,提供了丰富的方法来构建多智能体解决问题的方案。如果你有兴趣尝试一个有趣的多智能体系统,也可以查看 ChatDev,这是一组运行虚拟软件公司的智能体的开源实现。我鼓励你查看他们的 github 仓库,甚至可以克隆仓库并自己运行该系统。虽然它可能并不总是产生你想要的结果,但你可能会惊讶于它的表现有多好! 就像规划的设计模式一样,我发现多智能体协作的输出质量难以预测。更成熟的反思和工具使用模式更可靠。我希望你喜欢使用这些代理设计模式,希望它们能为你带来惊人的结果!
用于软件开发的交流智能体,Qian 等人(2023)(ChatDev 论文)
AutoGen:通过多智能体对话实现下一代 LLM 应用,Wu 等人(2023)
MetaGPT:多智能体协作框架的元编程,Hong 等人(2023)
https://deeplearning.ai/the-batch/issue-245/
https://x.com/AndrewYNg/status/1780991671855161506
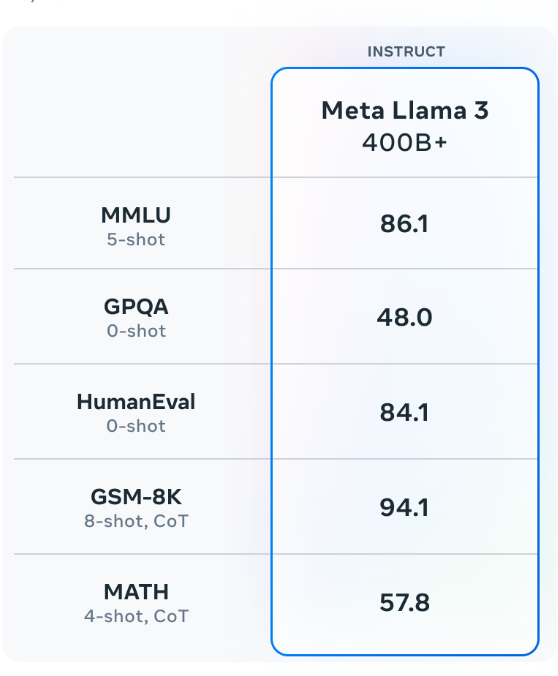
资讯 Llama3-Meta开源推出的新一代大语言模型 Llama 3是Meta公司最新开源推出的新一代大型语言模型(LLM),包含8B和70B两种参数规模的模型标志着开源人工智能领域的又一重大进步。作为Llama系列的第三代产品,Llama 3不仅继承了前代模型的强大功能,还通过一系列创新和改进,提供了更高效、更可靠的AI解决方案,旨在通过先进的自然语言处理技术,支持广泛的应用场景,包括但不限于编程、问题解决、翻译和对话生成。 参数规模:Llama 3提供了8B和70B两种参数规模的模型,相比Llama2,参数数量的增加使得模型能够捕捉和学习更复杂的语言模式。 训练数据集:Llama 3的训练数据集比Llama 2大了7倍,包含了超过15万亿个token,其中包括4倍的代码数据,这使得Llama 3在理解和生成代码方面更加出色。 模型架构:Llama 3采用了更高效的分词器和分组查询注意力(Grouped Query Attention,GQA)技术,提高了模型的推理效率和处理长文本的能力。 性能提升:通过改进的预训练和后训练过程,Llama 3在减少错误拒绝率、提升响应对齐和增加模型响应多样性方面取得了进步。 安全性:引入了Llama Guard 2等新的信任和安全工具,以及Code Shield和CyberSec Eval 2,增强了模型的安全性和可靠性。 多语言支持:Llama 3在预训练数据中加入了超过30种语言的高质量非英语数据,为未来的多语言能南力打下了基础。 推理和代码生成:Llama 3在推理、代码生成和指令跟随等方面展现了大幅提升的能力,使其在复杂任务处理上更加精准和高效。 李未可科技正式推出WAKE-AI多模态AI大模型 2024中国生成式AI大会上李未可科技正式发布为眼镜等未来终端定向优化等自研WAKE-AI多模态大模型,具备文本生成、语言理解、图像识别及视频生成等多模态交互能力。该大模型围绕 GPS 轨迹+视觉+语音打造新一代 LLM-Based的自然交互,同时多模态问答技术的加持,能实现所见即所问、所问即所得的精准服务。此外,融合了人类意图理解、长期记忆机制、情感大模型及TTS 克隆,可以为用户提供超拟人的情感陪伴服务。 https://www.jiemian.com/article/11066207.html 5亿个token之后,我们得出关于GPT的七条宝贵经验 自 ChatGPT 问世以来,OpenAI 一直被认为是全球生成式大模型的领导者。2023 年 3 月,OpenAI 官方宣布,开发者可以通过 API 将 ChatGPT 和 Whisper 模型集成到他们的应用程序和产品中。在 GPT-4 发布的同时 OpenAI 也开放了其 API。一年过去了,OpenAI 的大模型使用体验究竟如何,行业内的开发者怎么评价?最近,初创公司 Truss 的 CTO Ken Kantzer 发布了一篇题为《Lessons after a half-billion GPT tokens》的博客,阐述了在使用 OpenAI 的模型(85% GPT-4、15% GPT-3.5)处理完 5 亿个 token 之后,总结出的七条宝贵经验。 4000万蛋白结构训练,西湖大学开发基于结构词表的蛋白质通用大模型,已开源 蛋白质结构相比于序列往往被认为更加具有信息量,因为其直接决定了蛋白质的功能。而随着AlphaFold2带来的巨大突破,大量的预测结构被发布出来供人研究使用。如何利用这些蛋白质结构来训练强大且通用的表征模型是一个值得研究的方向。西湖大学的研究人员利用Foldseek来处理蛋白质结构,将其编码成一维的离散token,并与传统的氨基酸进行结合,形成了结构感知词表(Structure-aware Vocabulary),以此将结构信息嵌入到模型输入中,增强模型的表征能力。在预训练上,论文使用了目前最多的蛋白质结构(identity过滤后4000万),在64张A100上训练了3个月,最终开源了具备650M参数量的模型SaProt(同时包括了35M的版本)。实验结果表明SaProt各种蛋白质任务上都要好于之前的序列和结构模型。 “AI大战”全力以赴?谷歌再出招:重组团队加快产品创建! 谷歌正在对其人工智能团队进行结构性改革。据称,构建模型、研究和负责任的人工智能团队将被整合谷歌DeepMind之下,CEO皮查伊说,“我很高兴能在下周四的财报电话会议上展示更多进展。” https://www.cls.cn/detail/1651457 CVPR 2024高分论文:全新生成式编辑框架GenN2N,统一NeRF转换任务 来自香港科技大学,清华大学的研究者提出了「GenN2N」,一个统一的生成式 NeRF-to-NeRF 转换框架,适用于各种 NeRF 转换任务,例如文字驱动的 NeRF 编辑、着色、超分辨率、修复等,性能均表现极其出色! https://mp.weixin.qq.com/s/9CYkP_-oV6g4H5Pcs9PAgw
MLLM真能看懂数学吗?MathVerse来了次摸底测评,放出当天登热 在大算力的数字化时代下,大语言模型(LLM)以其令人瞩目的发展速度,正引领着技术的潮流。基于它们强大的文本理解和生成能力,各大研究机构正在探索如何将这些能力扩展至视觉领域,构建一个能够理解和生成多模态内容的超级智能体 —— 多模态大语言模型(MLLMs)。在追求通用视觉性能的道路上,社区内已经涌现出众多精心设计的测评 benchmark。它们通常使用贴近日常生活的自然图片作为样例,为 MLLMs 的视觉能力提供全面的评估,如 MME、MMBench 等。然而,要深入了解 MLLMs 的 “思维” 和 “推理” 能力,仅凭通用视觉性能的测评远远不够。多模态数学题求解能力,才是衡量它们深度认知和逻辑推理能力的真正试金石。尽管如此,目前领域内依然缺少针对 MLLM 数学解题能力的测评 benchmark。现有的少数尝试,如 GeoQA、MathVista和 MMMU,通过深入分析,仍然存在一定的问题和偏差。鉴于此,我们推出一个全新的测评 benchmark——MathVerse,旨在深入探究 MLLMs 是否真正具备解读和解答多模态数学题的能力,为未来的技术发展提供独特的见解。 产品 Seomaker Seomaker.ai 是一个帮助用户精通搜索引擎优化的下一代工具。它是一个基于人工智能的平台,提供超过25种工具套件,旨在简化用户的SEO策略,并提升在线表现。该平台包括直观的文案AI、竞争对手分析、排名跟踪和SEO网站审核等功能。 https://seomaker.ai/ Cascadeur Cascadeur 是一款专业的角色动画和运动捕捉编辑软件,旨在帮助用户编辑角色动画并进行物理交互。该软件具有 Animation Unbaking、AutoPhysics 和 Copy/Paste Retargeting 等功能,可以帮助用户处理和编辑动画,以及对角色进行物理交互。 https://cascadeur.com/ Tabula Tabula 提供了一个面向业务所有者、营销和产品经理、销售主管和分析师的解决方案,旨在通过无代码界面和人工智能帮助用户理解他们的数据。该平台擅长于销售和营销分析、临时和深入的数据分析、自动化例行分析任务以及报告和仪表板生成。 https://www.tabula.io/ Clazar获得1000万美元A轮融资,以现代化云市场中的SaaS销售 Clazar,一家自动化云市场软件销售的初创公司,宣布完成由Ridge Ventures和Ensemble VC领投的1000万美元A轮融资。该公司成立于2023年,目前总共筹集资金1400万美元。这些资金将用于简化在Amazon Web Services、Microsoft Azure和Google Cloud等市场上销售的技术和操作挑战。Clazar的软件平台与顶尖云市场集成,简化软件供应商与云提供商之间的共同销售过程,加快收入实现时间,扩大市场份额。 https://venturebeat.com/ai/clazar-raises-10m-series-a-to-modernize-saas-sales-across-cloud-marketplaces/ 阿姆斯特丹初创公司Verify获得100万欧元投资,扩展其隐形指纹解决方案 位于阿姆斯特丹的人工智能初创公司Verify宣布获得由连续创业者Niels Bouwman和Chris Hall的天使投资,共100万欧元。Google也对Verify进行了投资,并将其纳入Google for Startups Cloud Program。这笔资金将用于招聘熟练的AI开发者和数据科学家,进一步扩展其在欧洲和美国的业务。Verify的初步客户包括Vinci Energies、鹿特丹大学和荷兰国家工会FNV。 公司官网:https://www.joinverify.com/ https://www.eu-startups.com/2024/04/amsterdam-based-verify-snaps-e1-million-to-expand-its-invisible-fingerprint-solution/ dataplor宣布由Spark Capital领投的A轮融资,以扩展全球位置数据智能 dataplor,全球位置智能领先提供商,宣布获得由Spark Capital领投的1060万美元A轮融资。本轮融资还包括Quest Venture Partners、Acronym Venture Capital、Circadian Ventures、Two Lanterns Venture Partners和APA Venture Partners的参与。这些资金将用于加速dataplor的全球扩展,建立市场上最准确、最全面、不断更新的全球兴趣点(POI)数据数据库。该公司自2020年以来的年均收入增长率为2.5倍,已获得众多财富500强客户的青睐。 公司官网:https://www.dataplor.com/ https://www.businesswire.com/news/home/20240418167357/en/dataplor-Announces-Series-A-Funding-Led-by-Spark-Capital-to-Expand-Global-Location-Data-Intelligence FYLD获得1200万英镑资金,用于AI驱动的现场管理平台 英国的AI驱动现场管理平台FYLD成功筹集了1200万英镑的资金。此轮融资由安大略教师养老金计划领投。FYLD利用自然语言处理、计算机视觉和AI实时分析现场情况,帮助管理团队和操作团队做出更好的决策。至今,FYLD总共筹集了2600万英镑资金,使其AI平台快速推广,并在2023年实现了3倍的收入增长。此次融资将用于扩大商业团队,加速产品开发,增强AI驱动的预测分析平台,并拓展到全球新市场。 公司官网:https://www.fyld.ai/ https://tech.eu/2024/04/18/fyld-secures-ps12m-funding-for-ai-powered-field-management-platform/
大模型日报 16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/15934.html