


图像生成


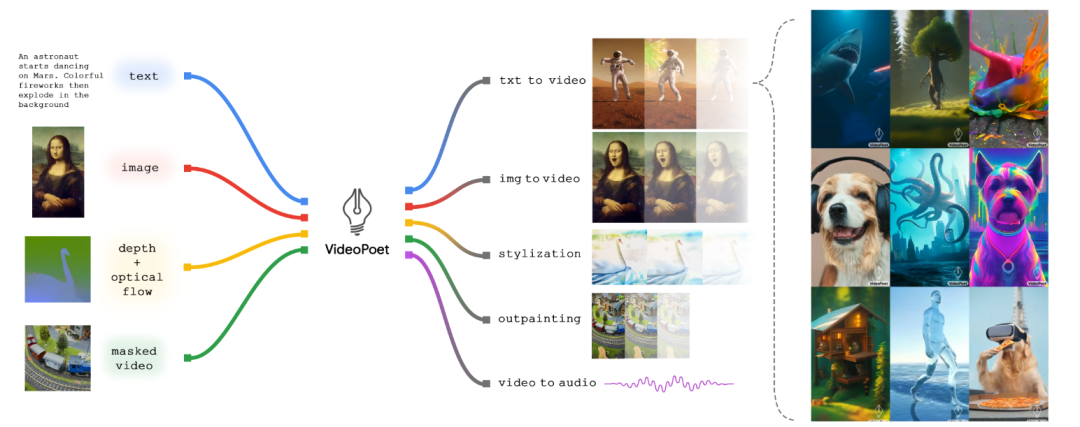
视频生成

3D生成
1.单场景3D重建


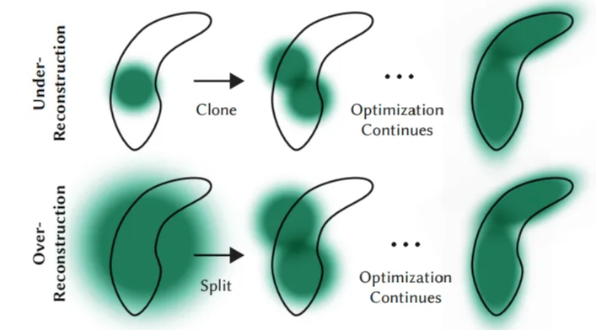
2.多模态3D重建
跨模态理解
-
判别式(Judgement)的评测方法:要求多模态大模型判断一段文本和图片中的内容是否一致 -
生成式(Description)的评测方法:要求多模态大模型对给定的图片生成一段详细描述,并测试描述中和图片不符的内容的比例。

使用判别式和生成式方法验证跨模态模型理解能力
-
提升训练数据标注质量,通过提供详细的图像描述和问题回答示例的注释,帮助训练和评估模型的幻觉检测能力。代表工作如M-HalDetect。 -
改进训练方式,通过收集人们关于模型幻觉的反馈提示,增强跨模态模型的可信度。代表工作如RLHF-V。 -
改进解码方式,通过在数学上引入惩罚项等方法,减少解码过程中的统计偏差。代表工作如OPERA、Visual Contrastive Decoding。 -
对生成结果进行后处理,通过识别和纠正生成文本中的幻觉部分,改善跨模态模型的输出。代表工作如Woodpecker。
-
定位(grounding/localization):输入一段文本描述要求模型输出它在图片/视频中的位置。 -
字幕生成(dense captioning):针对给定的图片、视频,关注其中的多个不同的片段,生成多个不同的字幕。
Process
多模态与视频生成
-
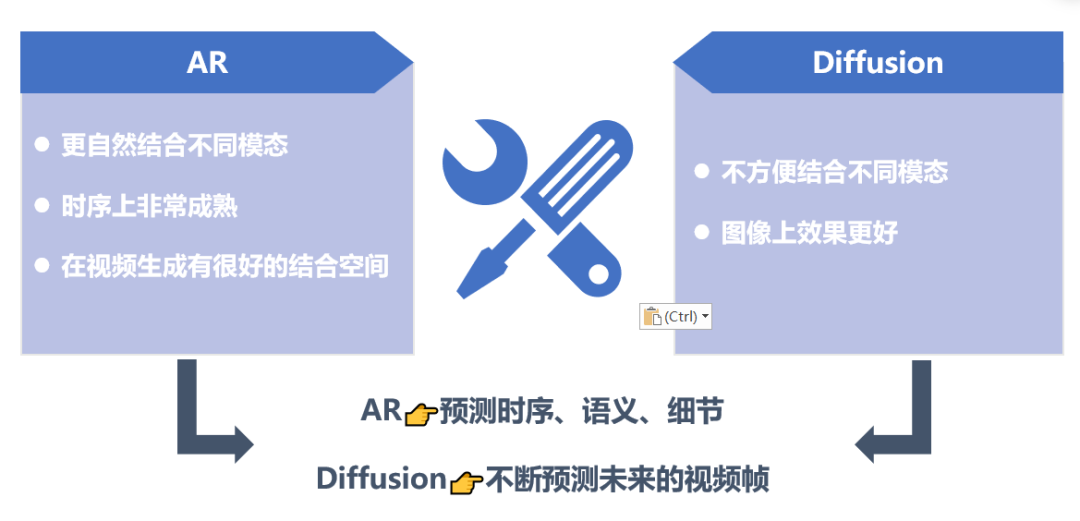
图像视频生成的技术路线:Diffusion or AR?
-
结合视频理解和视频生成的端到端模型
-
世界模型和内容生成的异同
-
3D技术路线:NeRF vs 3DGS
-
计算量与存储空间 -
可控性与可解释性 -
几何精度
-
数据集构建与Scaling
-
可扩展性 -
数据规模与质量 -
模态融合
游戏和动画对于模型的精细度、布线的合理度要求最高,需要符合行业原生作业流程的需求。现有AI模型通常从整体结构出发,这在某些情况下可能不够灵活,且技术上很难用模块化 + 搭积木的方式解决。
也可以考虑放弃依赖点云和相机位姿信息,转而通过图像本身进行空间计算,生成更精确的3D模型。
ToC
-
在材质和光照上,针对不同材质和光照条件进行优化,提高模型真实感和视觉效果; -
提供丰富多样的创意模版供企业用户使用,满足各式各样的营销需求; -
优化三维扫描服务,还原产品细节并且生成高质量的产品模型。
-
3D建模与可视化:在传统建模方式需要高学习成本的现实情况下,大模型赋予98%的普通用户也能够实现三维建模,才能将现阶段通用的2D屏幕显示真正升格到3D空间显示,例如朋友圈变成可交互的3D朋友圈;进一步通过用户共建,配合硬件设备发展,支持AR/VR/XR的真正普及。 -
内容创作与分享:提供平台和工具,鼓励用户在社交媒体和视频分享平台上,生成和分享自己的3D内容,如室内设计、虚拟展览、世界创作等。 -
教育与娱乐:提供在线教育和娱乐内容,如3D建模教程、虚拟游戏等,利用3D技术增强学习体验和娱乐效果。
ToB
产品落地问题
-
技术限制:3D生成技术存在局限性,如模型精度和畸变问题,需要从底层技术进行突破。 -
市场需求:不同行业对3D建模的需求不同,需要细粒度模块化,以便更好地融入现有工作流。 -
隐私和数据安全:在智慧城市和智慧园区项目中,需要考虑隐私和数据安全问题,避免涉及敏感信息。 -
技术路线选择:最终决定专注于偏设计类的建模和合成数据,避免直接竞争。
-
数字经济(智慧物业、智慧园区、数字城市、数字地球等):解决了实时三维生成(建模)之后,又重塑行业现状的潜力,但需要解决隐私和数据采集的问题。 -
影视和游戏:这些行业对3D模型的精度和细节要求较高,是技术应用的难点。 -
建筑:不需要高面数的mesh,需要独立的楼板、玻璃、管线等。
市场需求-多模态高质量数据
-
通用机器人走向端到端、Video-in Action-out的新范式——一切问题就变成了高质量数据的问题,需要高质量端到端的数据去迭代,去训练这样生成式智能或具身智能。 -
自动驾驶(如特斯拉V12)是标准的端到端的Video-in Action-out(视频输入-动作输出)系统。
商业模式:平台型产品
-
DriveDreamer自动驾驶世界模型:已经实现了大规模的商业落地应用。 -
WorldDreamer通用世界模型:使用Transformer架构,目标是通用视频生成和世界模型;
-
世界模型和物理世界模拟器在端到端解决方案(Video-in Action-out系统)中扮演着关键角色。 -
端到端解决方案成为趋势,需要从视频输入到动作输出的全过程优化。
圆桌对谈
-
作为年轻团队,选择创业方向时的考虑?做产品的逻辑和出发点是什么?
-
对于未来合成数据在未来,特别是在多模态应用上的思考?
-
目前思考的关键性问题以及看到的机会?


大模型空间站再次感谢各位朋友的支持!
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/13977.html