
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

论文
Chameleon:混合模态早融合基础模型
 http://arxiv.org/abs/2405.09818v1
http://arxiv.org/abs/2405.09818v1多模态基座模型多示例上下文学习
 http://arxiv.org/abs/2405.09798v1
http://arxiv.org/abs/2405.09798v1SynthesizRR: 利用检索增强生成多样化数据集
 http://arxiv.org/abs/2405.10040v1
http://arxiv.org/abs/2405.10040v1大型离散动作空间的随机Q学习
 http://arxiv.org/abs/2405.10310v1
http://arxiv.org/abs/2405.10310v1LoRA学习更少,遗忘更少
 http://arxiv.org/abs/2405.09673v1
http://arxiv.org/abs/2405.09673v1LLM和模拟作为双层优化器:推进物理科学发现的新范式
 http://arxiv.org/abs/2405.09783v1
http://arxiv.org/abs/2405.09783v1自然语言有助于弥合从Sim到Real的差距
 http://arxiv.org/abs/2405.10020v1
http://arxiv.org/abs/2405.10020v1OpenAdapt
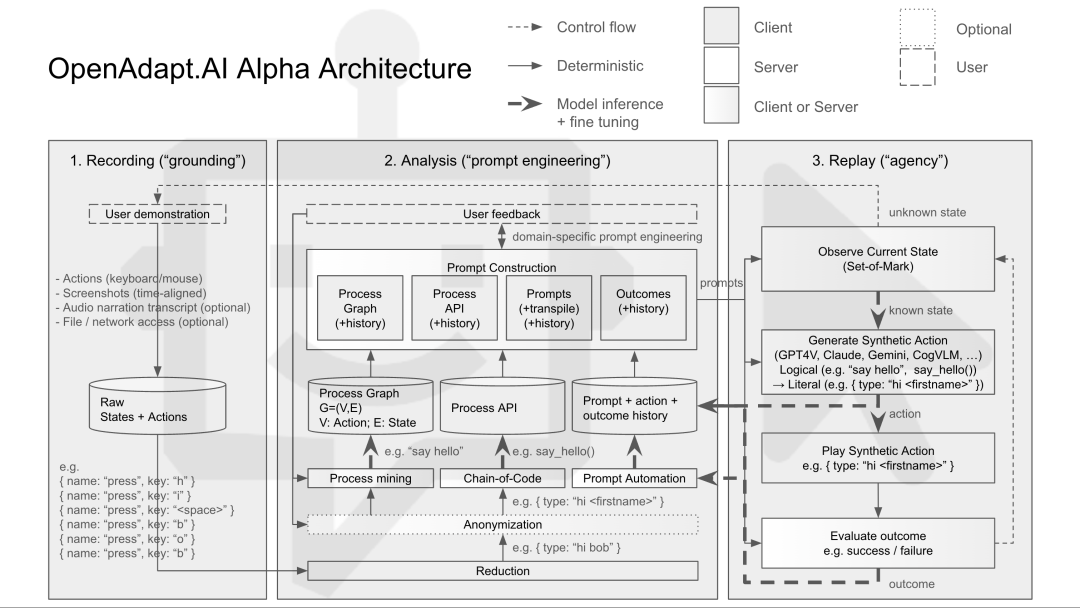 https://github.com/OpenAdaptAI/OpenAdapt
https://github.com/OpenAdaptAI/OpenAdapt杜克大学 LLMOPs 课程
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15345.html