


此文章仅供内部学习,如果有问题欢迎指正。
内容由实习生与 GPT 整理
为什么要做基础模型新架构研究?



比如,如果现在数据和计算资源的边际效益递减,其实可能是因为架构本身已经到了瓶颈。
Component

-
Token Mixing 主要是在序列维度上面做一个混合
-
Channel Mixing 是在特征维度上面进行一个混合
因为这个输入就是序列长度乘特征长度,所以只能在这两个维度上进行混合,这两个部分可以说是非常本质的。
之前有一个叫 MetaFormer 的工作,它把整个 Transformer 的架构抽象成两个模块:
一个是 Token Mixer
一个是 Channel Mixer
Token Mixer 可以换成各种在序列维度上做混合的 layer,而 Channel Mixer 也可以换成在特征维度上做混合的 layer。
Token Mixing

-
第一个问题是 RoPE,RoPE 是一种相对位置编码,它在长度外推上有一些局限性,没法很好地进行长度外推。而且 RoPE 和Transformer 本身的表达能力也不够强,所以需要借助一些 Chain-of-Though 来增强它的表达能力。 -
另外一个方面是效率问题,Self-Attention 机制的时间复杂度是平方级的,这在长序列建模任务中有很大的问题。比如在视频生成任务中,如果直接在几百万长度的序列上跑 Full Attention,计算成本会非常高。像视频这种数据,随便几分钟的视频就能达到几百万的序列长度,在这种情况下,Attention 机制的平方复杂度即便有 Flash Attention 来优化,依然是不容忽视的。另外还有一个线性的空间复杂度问题。在解码过程中,KV Cache 的大小会随着解码长度的增加而不断增长,很容易导致 out of memory 的问题。
RoPE后已有的改进

首先,我们来讲 Position Encoding。也就是说 RoPE 还能换成什么别的东西?
-
之前有个方法叫 NoPE,它的做法是直接把 Position 空间去掉,但实际效果并不好。
-
另外,也有很多方法尝试改进 RoPE,让它可以做长度外推。但最后大家发现,直接增大 RoPE 的 base,然后在长文本上继续训练,整体上的超长文本能力会更好一些。
上下文相关的位置编码——看好的方向

那接下来,Position Encoding 未来可能的发展方向是什么?
我个人比较看好上下文相关的 Position Encoding。RoPE 其实是上下文无关的位置编码,它的值和前后词的内容没有关系。而有研究提出了一种Contextual Position Encoding,在一些任务上,比如 selective Copy、counting、Flip-Flop,比起 RoPE 这种相对位置编码,效果会更好一些。
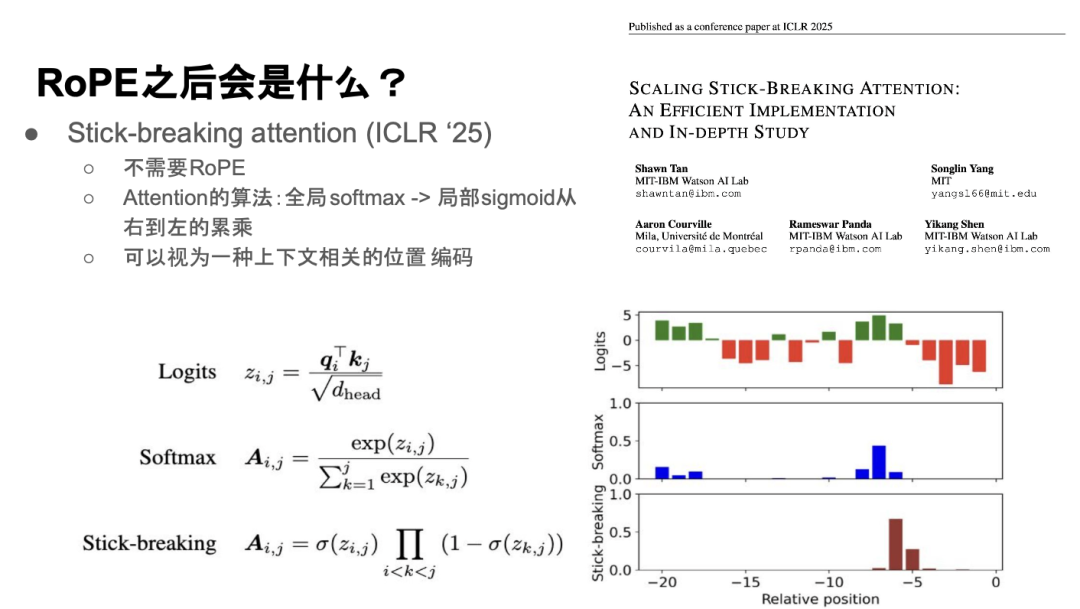
然后最近 ICLR 25 也有一些关于位置编码的改进工作,比如我们这篇Scaling Stick-Breaking Attention,我也是作者之一。
🔗论文链接:https://arxiv.org/abs/2412.06464
https://arxiv.org/abs/2412.06464
在这篇工作里,我们提出了一个完全不需要 RoPE 的编码方式,核心思路是改进 Attention算法。之前的全局 Softmax Attention 是位置不敏感的,而我们把它换成从右到左的 Sigmoid Attention,它本身的累乘机制就自带位置敏感性,所以不需要额外的位置编码。可以把这种自带的位置敏感性,看作是一种上下文相关的位置编码。然后下面有几个公式,核心的思想就是从右到左的 Sigmoid 计算,即 (1 – sigmoid) 的累乘。
实验结果表明,这种Stick-Breaking Attention 在性能上是稳压 RoPE 的。

另外的话,还有一篇 Mila 的工作,叫做Forgetting Transformer,它其实可以看成是 ALiBi 的一个动态版本。ALiBi 的话,大家应该也比较熟悉,它是一种位置编码,但是它的衰减方式在长文本任务上容易出问题,所以现在大家基本都不用 ALiBi,而是更多选择 RoPE。而Forgetting Transformer的核心想法,就是把 ALiBi 的衰减因子从一个固定的常数变成一个动态值。它通过类似 Forgetting Gate这种机制来计算这个衰减值。因为这个衰减是跟上下文相关的,所以它也可以看成是一种上下文相关的位置编码。
高效注意力机制

然后,除了位置编码之外,就是注意力机制的一些改进了。主要的话,还是有三种机制:

-
第一种是线性注意力,这部分的话,之前我其实也写过一些内容,包括 tutorial video,还有 slides,大家可以到我主页上去看,这里就不细讲了,简单提一下。像线性注意力,它基本上可以分成几类,比如加衰减率的模型,像MSR 做的RetNet,然后是Lightning Attention,就是MiniMax-01里面用的注意力机制。然后像Mamba-2,它其实就是一个线性注意力,再加上一个动态的衰减。而 Gating Linear Attention 这个是我之前在 ICML 的一个工作,它也是一个动态衰减的线性注意力。另外最近比较流行的一种线性注意力机制叫做Test-time 在线学习的线性注意力。最近这类方法比较流行,比如DeltaNet、Test-time Training、Titans。像Titans这篇工作,大家最近应该能经常在微信公众号、三大顶会上面看到。然后像RWKV-7、Gated DeltaNet这些都是表达能力更强的在线学习线性注意力的一些变体。如果大家对这些更感兴趣的话,可以去看我主页的 slides。

-
然后除了线性注意力,还有一种东西叫做稀疏注意力。稀疏注意力一般分为静态稀疏和 动态稀疏。静态稀疏指的是那个稀疏的 pattern 是事先给定的,它在计算过程中不会发生变化。像这种静态稀疏的一些经典工作,比如 BigBird,这其实是谷歌之前做的一个工作。然后 StreamingLLM,它是用一个 sliding window,再取最前面的那个 attention sink。动态稀疏 就是模型会根据不同位置的信息,动态地改变那个稀疏模式。最近比较火的就是 DeepSeek 和 Kimi,他们两个都同时出了两个动态稀疏机制。第一个是 Native Sparse Attention,另一个是 MoBA。

-
在这两种方法之外,我们还会碰到一种叫做混合注意力的一些模型,它主要可以分为两类:
-
一种是在层间混合;
-
另一种是在层内混合。层间混合的意思是,在不同的层里有不同的注意力机制,比如有的层使用 Linear Attention,有的层使用 Softmax Attention。而 层内混合 则是同一层中会同时使用 Sliding Window Attention 和 Linear Attention 等不同的机制。
-
线性注意力

这里我展示了一些来自我主页的 slides,基本上想表达这都是一些线性注意力在硬件上非常高效的RNN。

它通过一些高效的操作,比如外积,来更新状态,而外积有很多良好的性质,这也让其在硬件上训练时非常高效。具体细节这里就不再展开了。另外,加Decay的方法是在 Hidden State 前加一个 Gamma(Gamma 介于 0 和 1 之间)。这样做的效果是,逐步忘掉之前的信息,更加关注当前的状态。
这种机制其实就是 Lightning Attention 在 MiniMax-01 中使用的那种方法,是一个相对简单的机制。
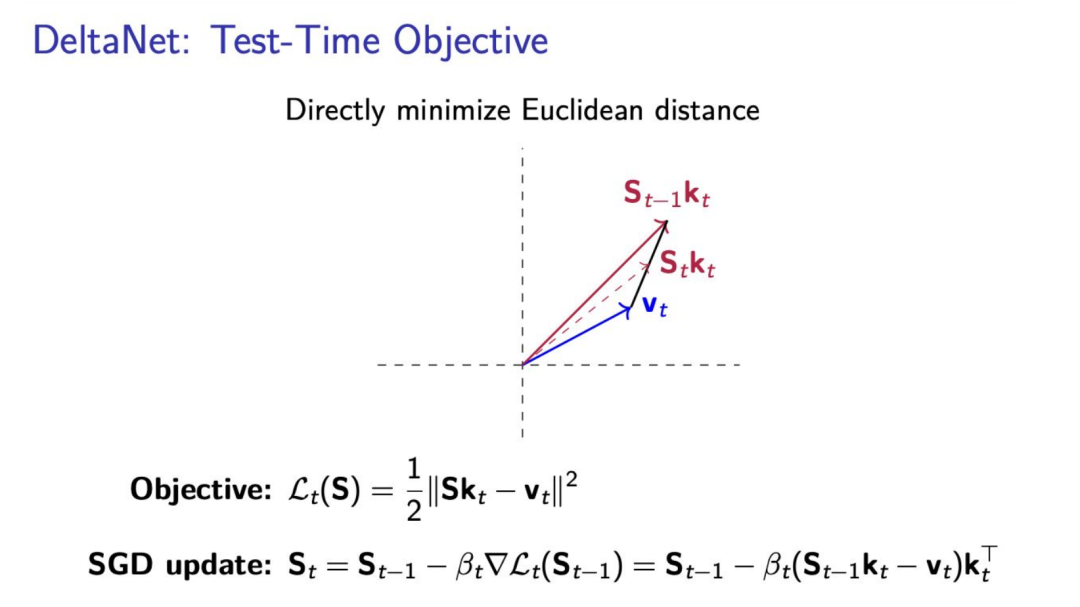
另外,还有一种方法是 test-time 训练模型。这种方法的目标函数其实是在线学习的目标函数,而隐状态的更新是通过在线梯度下降来进行的。例如 DeltaNet,它通过在线优化一个线性回归损失来更新模型的参数,通过一次梯度下降,进而得到 DeltaNet 的更新公式。
以上这些方法都是典型的线性注意力方法,它们的基本思想在之前的工作中已经有了一些总结,具体细节可以参考我的主页。
2. 稀疏注意力
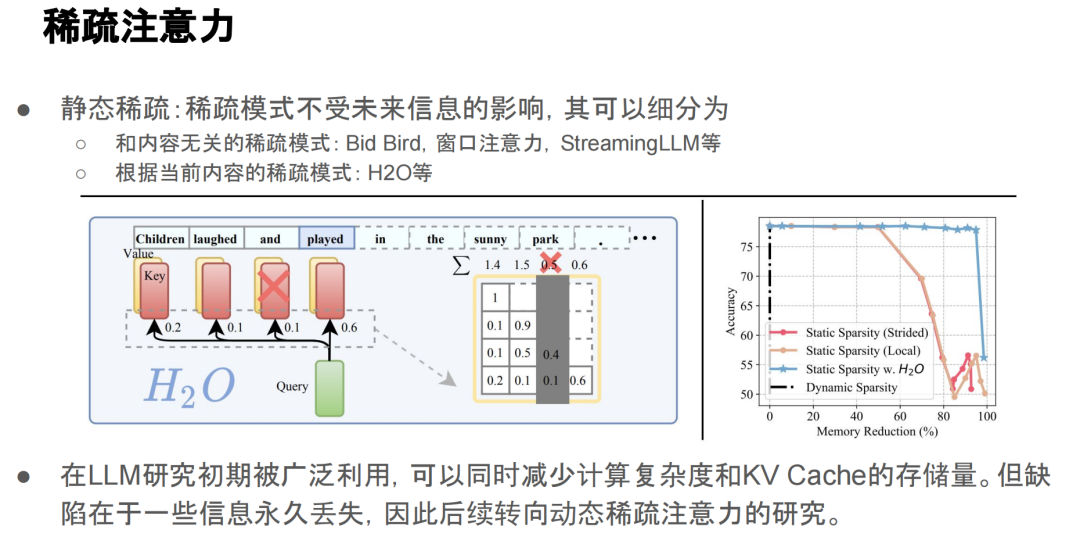
稀疏注意力可以分为静态稀疏和动态稀疏。
-
静态稀疏的模式是事先设定好的,并且不会随着输入的变化而变化。通常这些方法因为给定了很强的先验,所以它们的表达能力相对较弱。现今,这类方法已经不太被使用了。

-
动态稀疏是近年来比较流行的一种方式。它的特点是稀疏模式是由每个 token 动态选择的。动态稀疏的主要挑战在于,由于其稀疏模式非常灵活,没有固定规则,因此可能会出现不连续的稀疏模式,而不连续的模式在硬件上会比较慢。为了应对这一问题,近期的研究通过将选择分为 block 来进行优化。因为一个 block 通常包含多个连续的 tokens,所以它的读取是连续的,这样有助于提高硬件效率。
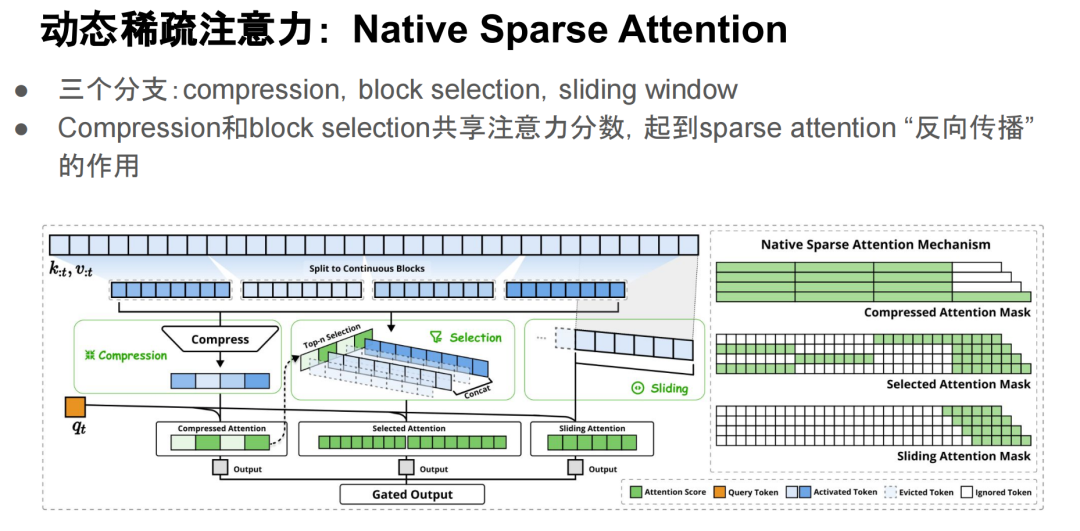
接下来简单介绍一下 NativeSparseAttention 的思想,一共有三个分支(compression/block selection/sliding window)。它将整个序列划分成若干个 chunk,每个 chunk 首先通过 compression 将其压缩成一个 token 表示。然后使用新的橙色的querytoken对这些 compressed tokens 进行注意力操作,得到一个 compressed attention的output。在这个过程中,注意力分数会用来选择 top-k 的 attention blocks,然后在这些 blocks 上执行 sparse attention。最终,再补充一个 sliding window attention,这就是 Native Sparse Attention 的主要做法。
Native Sparse Attention 之所以被称为原生稀疏注意力,是因为它可以直接进行预训练,并且有一些假设:每个 query group 下的每个 head 选择相同的 KV block,这样可以避免不同的 head 重复读取不同的 KV block,从而减少 IO 开销。
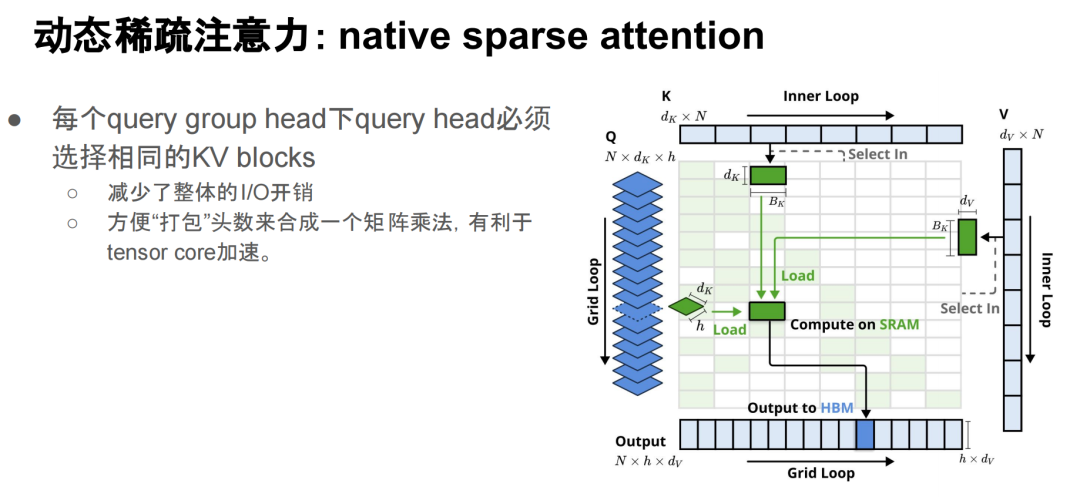
此外,Native Sparse Attention 还可以将每个位置的 attention heads 合并成一个矩阵乘法,这对硬件加速有很大帮助。
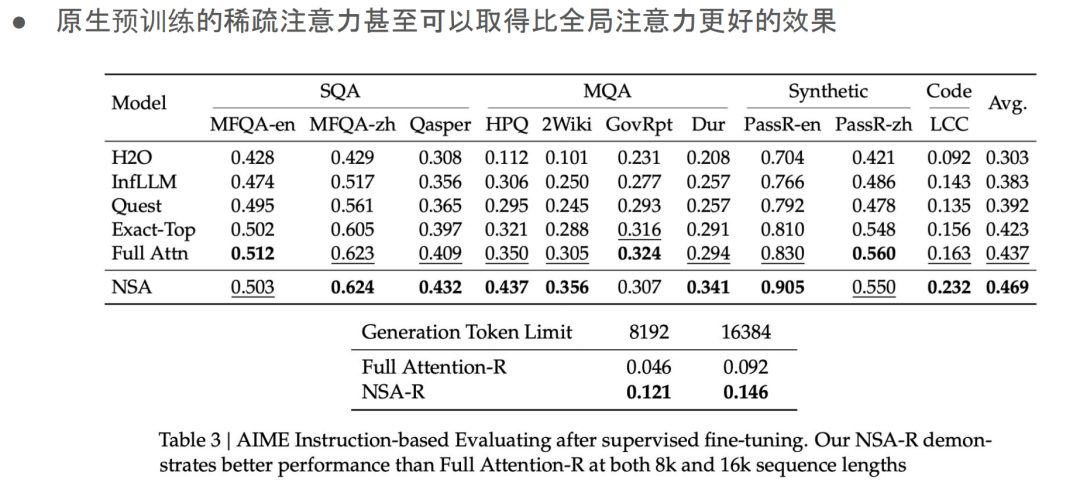
一个有趣的发现是Native Sparse Attention 甚至在一些任务上能超过全局注意力 的效果。传统上大家认为稀疏注意力只是掉点,也就是效果只能保持,无法提高,但 Native Sparse Attention 通过学习自己的注意力分布,能够达到不输于全局注意力的效果。这表明,通过设计新的架构并进行预训练,可能会得到比现有架构更好的效果。

MoBA 的思想与 NativeSparseAttention 非常相似。它的 chunk pooling 使用的是 mean pooling,不像 NSA 中那样有多个分支,因此不会引入额外的参数,也不强制选择相邻的 blocks。它也比较兼容 Flash Attention 的 kernel,但在硬件训练效率上不如 Native Sparse Attention。不过,MoBA 通过预训练,能够实现与 full attention 相比完全不逊色的性能。
3. 混合注意力
接下来就是混合注意力。
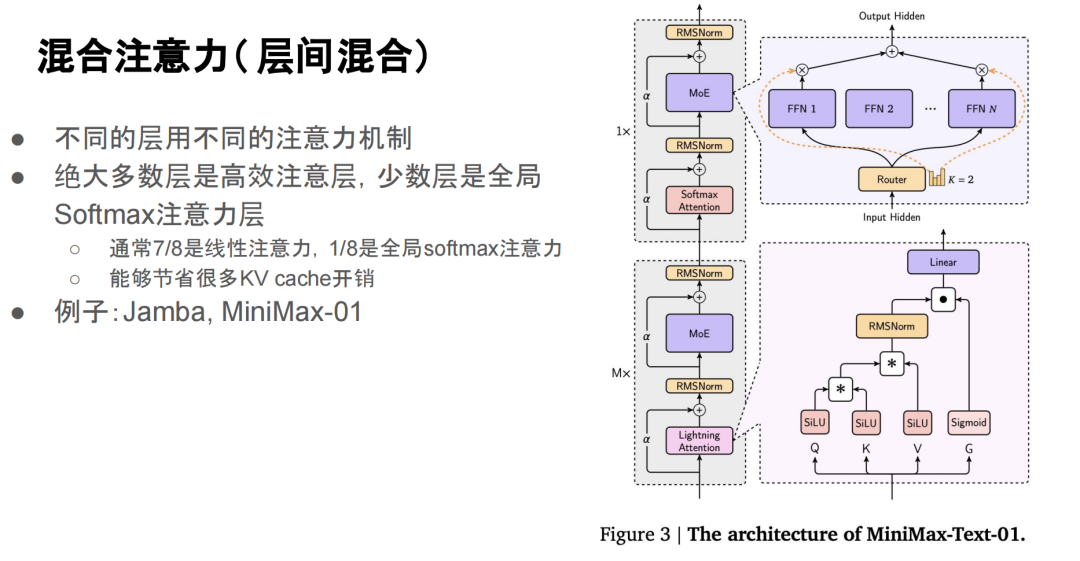
前面我们讲到,它有很多种混合方法,基本上就是说不同的层就用不同的混合方式,也就是说在不同层之间我们用不同的注意力机制。大部分层都用的是高效的注意力机制,只有少数层用的是全局的 softmax attention。
举个例子,通常我们会有 7/8 层用线性注意力,而 1/8 层用全局 softmax attention。
这样做的好处就是,我们可以把 7/8 层 的 KV cache 直接省下来,因为线性注意力的 hidden state 可以表示为 RNN,它的 KV cache 基本上可以忽略不计。
这方面比较典型的例子,比如 Jamba 和 MiniMax-01。他们的做法就是每七层使用 Lightning attention。前面提到过,Lightning attention 其实就是最简单的线性注意力,再加一个衰减项。这里的 m 通常取的是 7,所以形成了 7:1 的比例,这个比例在实际中是比较常见的。
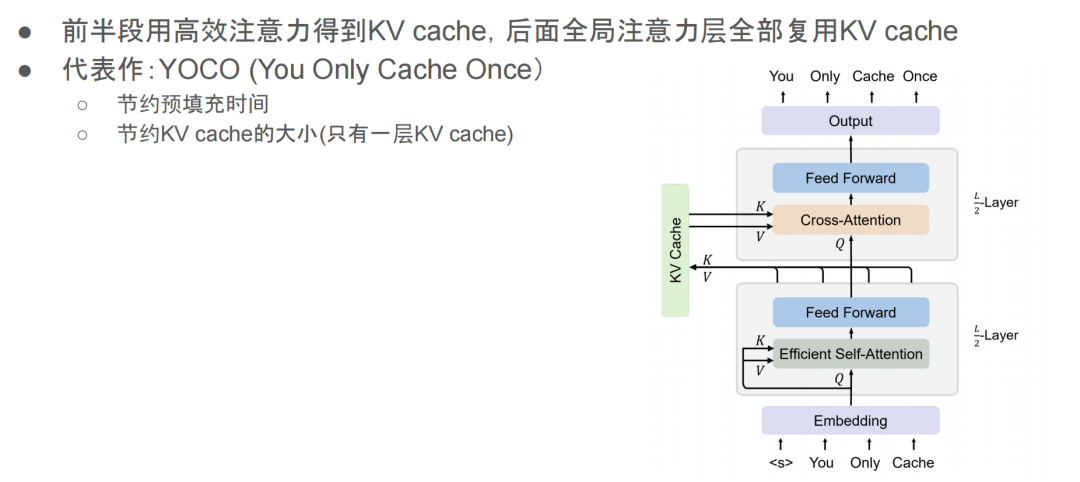
前面我们也说过,这种方法需要存储 1/8 层的 KV cache。如果层间混合做得更极致的话,可能只需要存储一个 KV cache。也就是说,前半部分的层采用高效的注意力机制,然后它算出来的 KV cache 就可以用于后面所有的全局注意力层。这样的话,首先能节省预填充的时间,因为在预填充时,我们只需要计算前面的高效层,得到 KV cache 就好了,不需要计算后面的全局注意力层,我们只需要存储中间那一层的 KV cache,后面的层可以共享这个中间层的 KV cache。
这篇就叫 YOCO,也就是 You Only Cache Once,意思是我只存一层的KVcache,然后做层间混合。

相比之下,注意力的混合方法主要是层内混合,比如 Jamba 这种比较典型的层内混合方法,它就是在一层里同时用 sliding window attention 和 linear attention。具体来说,它先跑一个 sliding window attention,然后在此基础上再加一个 linear attention,这样就能在同一层里实现两种不同的注意力机制。
Channel Mixing
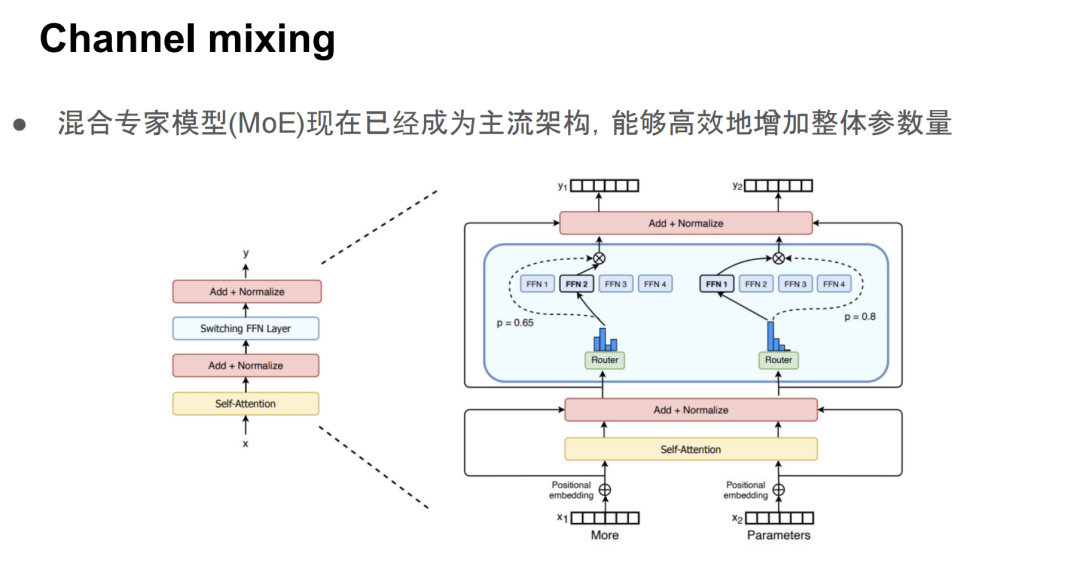
再来看注意力机制的 token mixing,它主要是在位置编码和注意力机制本身上做一些研究。而 channel mixing 一般就是 FFN 层,FFN 层可以被看成是一种key-value形式的associative memory。它的参数可以理解为存储了一些全局知识,所以大家普遍认为 FFN 和知识存储是相关的。那么很自然的一个思路就是,我想增大 FFN 的容量,但又不想大幅增加计算量,于是就有了 Mixture of Experts(MoE)模型。现在 MoE 结构基本上成了主流架构,很多支线模型都会带一些 MoE 组件,因为它是目前非常高效的扩展整体参数规模的方式。
MoE 还是有很多可以做的东西。
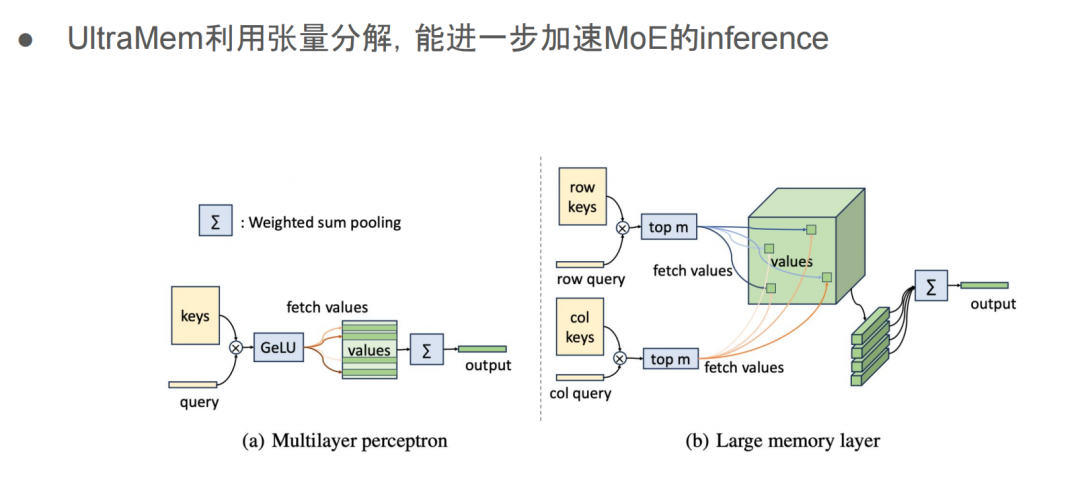
比方说,UltraMem 这篇文章就是用张量分解进一步加速 MoE 的 inference。它提出了一个叫做 Memory Layers at Scale 的方法。
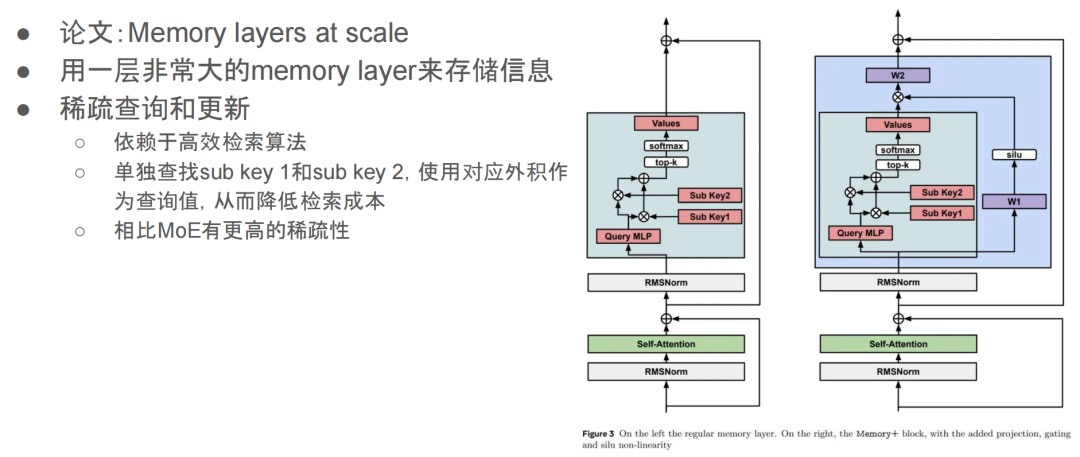
前面提到,FFN layer 可以理解成一个 memory layer,是用来存全局知识的。而这篇文章的做法就是用了一层非常非常大的 memory layer,来存储更多的信息。因为这层很大,所以他们不想做全局更新,而是通过一些高效的检索算法,找到激活的部分,只对这些部分进行查询和更新。这样的话,就能在拥有一个超大 memory layer 的同时,不会让整体的计算复杂度变得不可控。
未来方向预测

前面主要讲了 token mixing 和 channel mixing 能做的一些事情,那架构层面还能有哪些新的思路呢?
目前的模型基本上都是基于 next word prediction,但能不能探索一些非 next word prediction 的方法?
比如,最近有很多研究在做 diffusion large language model,用扩散来做文本生成。还有像 Meta 去年年底推出的一个模型,它做的是 next concept prediction,而不是直接做 next word prediction。此外,还有一些研究在做 Multi-token Prediction,比如 DeepSeek-V3 也有相关的模块。
另外,现在大家特别关注 test-time scaling,而 test-time scaling 一般是通过长的思维链来做的。这种方式可以看作是水平方向的 scaling,那能不能在垂直方向上也做 test-time scaling?
这里的垂直方向指的是layer,如果从这个维度来做,一种比较自然的思路就是 Universal Transformer。那么,在 test-time scaling 的背景下,这类方法能不能有更大的应用空间?这其实也可以归为 latent reasoning,因为它不像 Chain of Thought 那样显式地依赖推理链,而是通过隐式的方式进行推理,因此被称为 latent reasoning。
另外的话,就是关于 memory 机制的进一步探索。之前,FFN 的权重基本上都是静态的,那能不能让这些权重随着输入的变化而动态调整?这样的话,其实就有点类似于 fast weight 这种比较经典的概念。然后还有一个方向,就是我们能不能加一些显式的外部记忆?比如 Transformers with Explicit Memory 这篇文章,它就在模型外部外挂了一个很大的知识库,来作为 KV memory。
最后的话,我们前面讲的 token mixing 和 channel mixing 是完全分开的,那能不能把它们结合在一起,直接做一个统一的更新呢?这些都是可以继续探索的方向。然后整体来看,在架构层面,其实还有很多优化的空间。
小编寄语

大模型空间站再次感谢各位朋友的支持!
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43303.html