我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


学习
万字综述 LLM 训练中的 Overlap 优化:字节 Flux 等 7 种方案
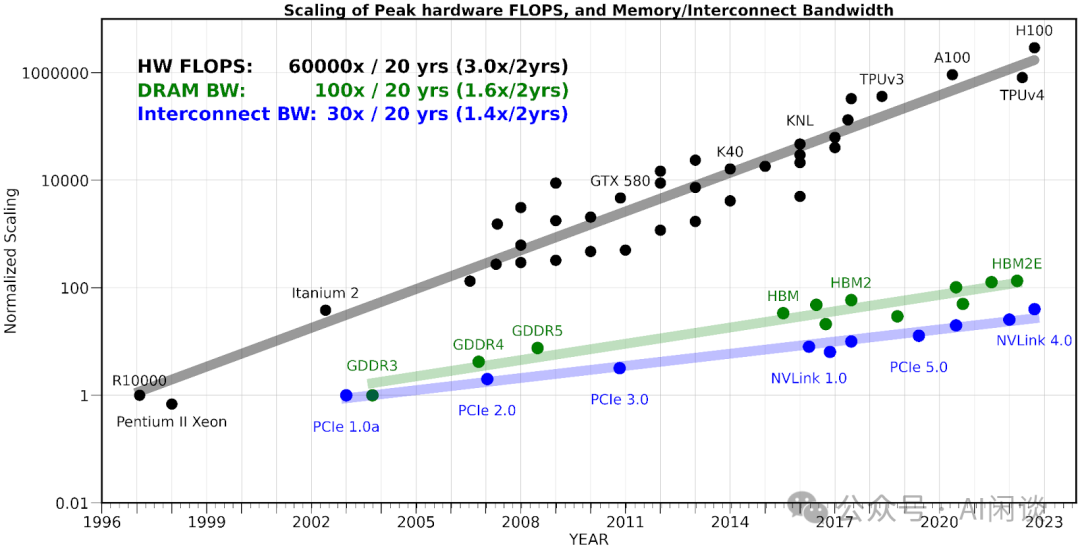
在大规模分布式训练场景中,计算和通信的重叠(Overlap)是提升训练性能的关键因素之一,尤其是在计算能力与通信带宽差距不断扩大的背景下。当前硬件的计算性能增长速度远快于网络带宽,这使得在训练任务中,通信成为了潜在的瓶颈,特别是在大型语言模型(LLM)的训练中。如何高效地实现计算与通信的重叠,成为了优化系统性能的重要策略。
通信与计算的重叠大致可以看作是生产者与消费者之间的重叠,其中生产者可以是计算操作或通信操作。通常情况下,短程依赖关系(如张量并行中的矩阵乘法与AllReduce通信)对于重叠的挑战更大,而长程依赖(如Deepspeed Zero的通信和计算)则相对容易实现。通过将计算与通信操作尽早交错执行,减少通信等待时间,可以提升系统的整体效率。
CoCoNet是微软提出的一种异步张量并行(Async Tensor Parallelism)框架,旨在通过自动化生成融合通信与计算的GPU内核来实现重叠。CoCoNet的关键在于通过领域特定语言(DSL)表示计算和通信操作,结合一组转换规则和编译器,优化计算与通信的调度。尽管该方法通过细粒度的重叠带来了性能提升,但在某些情况下,由于需要引入额外的同步操作,执行效率并未达到理想水平。
Google提出的Intra-layer Overlapping技术通过将通信与依赖计算操作分解为细粒度任务,从而在不同任务之间创造更多重叠机会。该方法特别适用于大规模模型训练,通过并行执行细粒度的通信与计算操作,隐藏通信延迟,提高系统吞吐量。
AMD的T3方案通过硬件与软件的协同设计,透明地将序列化的通信操作与计算重叠,减少了资源竞争并提升了重叠的效率。该方案引入了轻量级的追踪和触发机制,以确保计算与通信操作能够无缝协调执行,同时利用计算增强型内存处理通信任务,从而有效减少传输量并加速计算过程。
北京大学的Centauri框架则提出了一种全新的通信切分与层次调度方案,旨在为混合并行训练提供更加灵活和高效的通信与计算重叠策略。通过全面分析不同通信操作的切分空间,并结合层次化调度,Centauri能够在多种并行训练配置下有效提升系统性能。
这些技术方案通过不同的方式优化计算与通信的重叠,在提升系统吞吐量的同时,也降低了通信延迟和资源竞争,尤其是在训练大规模语言模型时。这些进展展示了在硬件与软件的协同下,通过创新的重叠机制,可以显著提
高训练效率,推动大规模分布式AI模型训练的进一步发展。
https://zhuanlan.zhihu.com/p/18746648408
LLM GRPO R1复现&代码笔记&逐行 debug 看懂 GRPO
这篇笔记详细讲解了GRPO (Gradient-based Reward Optimization) R1模型的复现过程,适合已有GRPO理论基础的读者。文章从数据加载、模型加载到训练过程的各个环节逐步展开。
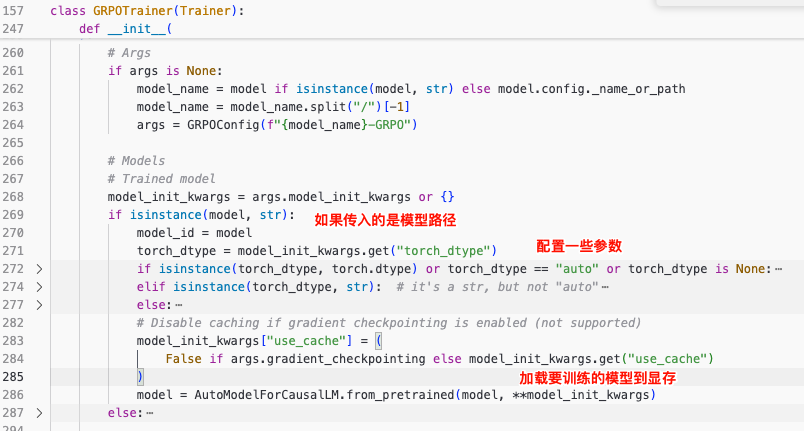
首先,数据集使用的是gsm8k,通过datasets包的load_dataset方法加载Hugging Face上的数据。数据集的形式是由问题、答案、提示和解决方案组成,共7473条数据用于训练。
接着是模型加载部分。通过TRL库的接口,加载了训练模型、参考模型和奖励函数。值得注意的是,GRPO采用的是基于规则的奖励函数,并不依赖额外的模型来生成奖励值。模型的加载过程中还使用了vllm框架进行推理操作,最终通过accelerator将模型分配到多个GPU卡上进行训练。
在训练过程的细节中,首先会计算训练的epoch数和每个epoch的step数,其中step指的是每16个样本更新一次梯度(一个问题贡献4个样本)。训练开始后,通过循环不断进行梯度更新。训练过程中最关键的步骤是如何计算advantage,即优势函数。通过采样得到多个答案后,计算出每个答案的奖励,并计算出与参考答案的KL散度。
对于奖励的计算,分为三种类型:accuracy reward、format reward和GRPO优势。accuracy reward是根据答案是否正确来给出奖励,正确答案得到奖励1,否则没有奖励;format reward则是根据答案格式的正确性来奖励。如果格式正确,返回奖励1,否则返回-1;而GRPO优势的计算比较简单,主要是对奖励的标准化处理。优势函数的设计在采样次数和奖励计算方式上进行了优化。
在计算loss时,使用了两个公式,首先计算每个token的优势与token概率的乘积,然后计算KL散度,最后求均值。这一步是通过反向传播来优化模型参数的。
最后,文章总结了整个训练流程。训练中每个步骤都会反复进行,直到完成指定的epoch数。在训练过程中,针对每个batch数据,进行采样、计算优势、计算loss,并更新梯度。
文章还提到,使用vllm框架进行多卡训练时可能会遇到性能问题,单卡训练效果通常好于多卡训练,可能是由于多卡训练时的通讯速度限制。
https://zhuanlan.zhihu.com/p/26473368775
[AI Infra] VeRL 框架入门&代码带读
VeRL 是字节跳动和香港大学联合开发的一个强化学习框架,旨在优化大规模模型训练的效率,特别是在复杂推理任务中的应用。其设计融入了混合编程模型,结合了单控制器(Single-Controller)和多控制器(Multi-Controller)的优势,使得框架在执行多种强化学习(RL)算法时,能提高训练吞吐量并降低开发和维护的复杂度。
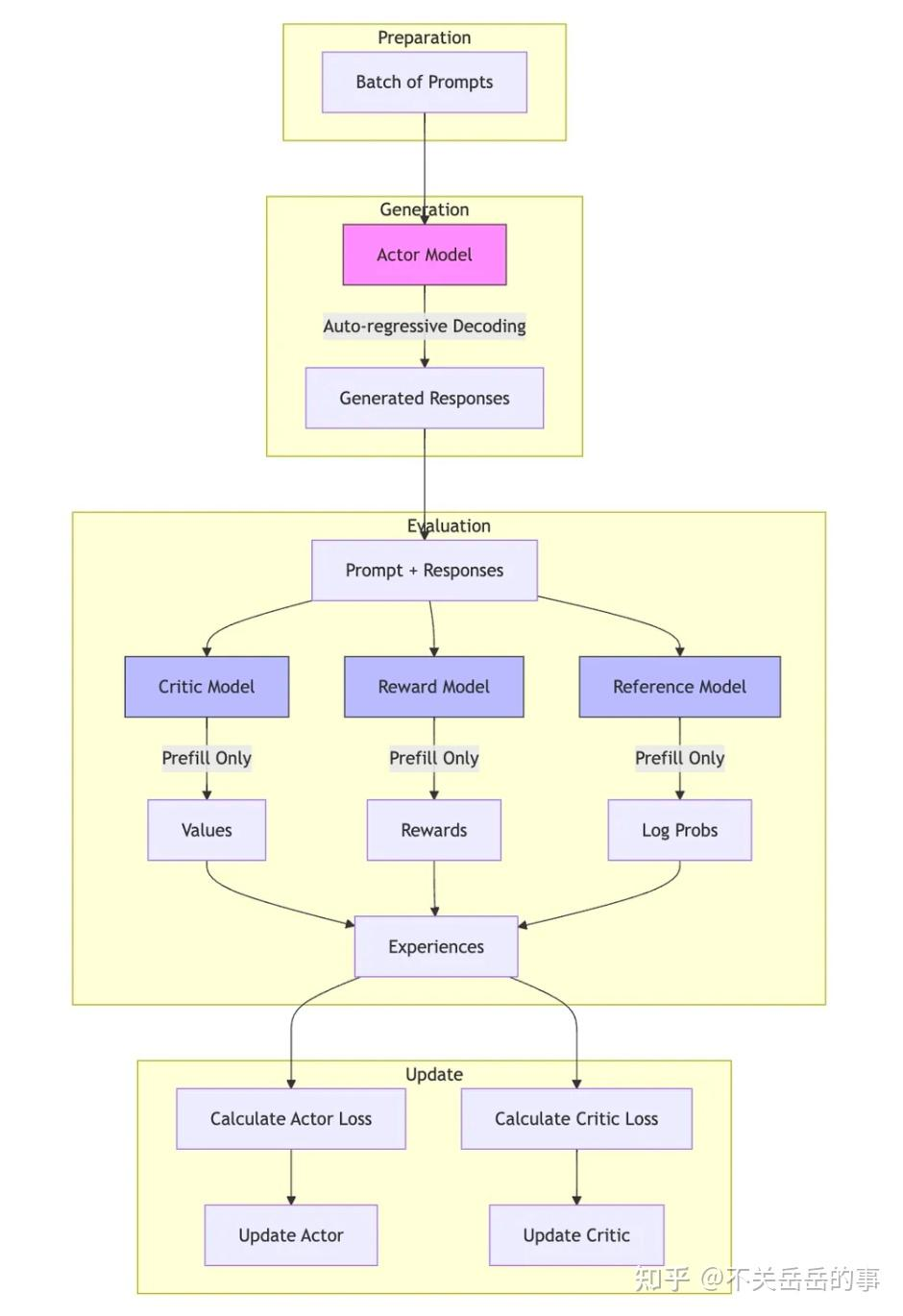
VeRL 的架构分为两大层次:控制流和计算流。控制流是高层次的,描述了模型之间的交互逻辑,例如在 RL 算法中,如何通过 Actor 生成经验,然后由 Critic、Reward Model(RM)和 Reference 模型来评分并计算优势函数(GAE)和损失。而计算流则是低层次的,涉及到每个模型的内部计算过程,例如前向反向传播、优化器更新等。为了有效管理这一流程,VeRL 采用了单控制器和多控制器两种设计模式:单控制器模式在控制流方面提供了清晰的架构和简易维护,而多控制器模式则用于计算流,减少了通信开销。
VeRL 利用了 Ray 框架来管理分布式计算中的资源,Ray 的异步执行能力使得不同的计算任务能够重叠执行,例如在更新批次时,生成新批次的任务也能并行进行。Ray 的资源管理器通过智能分配 CPU、GPU 和内存资源,优化了训练中的任务调度。除此之外,VeRL 支持多种并行策略,包括数据并行、张量并行和序列并行,后者尤其适合于超长文本的训练。
在训练引擎方面,VeRL 支持基于 FSDP 和 Megatron 两种后端,前者适合学术研究,后者则更适合工业界的大规模模型训练。训练过程中,VeRL 会根据不同任务和硬件资源,动态调整模型的放置策略,如分开放置、分组放置和一起放置,以便最优化计算资源的使用。
为了实现不同角色间的高效协作,VeRL 设计了一套数据传输协议,支持在不同的计算任务间传递数据和结果,且每个 worker 的任务都通过装饰器机制进行灵活配置。此外,VeRL 还支持多种 RL 算法,包括 PPO、GRPO 和 Reinforce++ 等,并在算法中实现了针对性地优势函数计算和 KL 约束的优化。
https://zhuanlan.zhihu.com/p/27676081245
这篇内容描述了围绕自动驾驶和芯片领域的三条主要产品线,分别是soDLA线、Cora线和Palladio-garden线,并对NVDLA(NVIDIA Deep Learning Accelerator)项目的历史和现状进行了反思。具体内容包括技术细节和行业反响:
soDLA线是一个商用版的NVDLA,它与开源版本的soDLA相比,作为chipyard的一个patch,能够支持nvdla中所有神经网络的运行。与开源版本不同,商用版soDLA经过了调试和验证,能更好地适应实际应用。具体性能方面,在28nm工艺、1GHz频率下,与NVDLA相比,soDLA节省了7%的面积,主要得益于Chisel到firrtl的直接性以及去除了NVDLA中的冗余事务逻辑。
Cora线是在soDLA基础上进行扩展,专为无人驾驶场景设计。无人驾驶不仅涉及机器学习,还包括控制、定位和路径规划等技术。Cora线的目标是将soDLA的处理能力扩展到这些领域,进一步增强自动驾驶的综合能力。
Palladio-garden线则源自NProcessor与ARM合作的项目,通过将ARM的IP封装在chipyard中,旨在实现ARM与RISC-V处理器的集成,支持在同一SOC中进行仿真。这种集成模式特别适合需要高性能ARM核心同时又需要定制RISC-V核的场景,能够加速芯片开发过程。
这三条产品线都以patch的形式增加到chipyard中,促进了芯片设计的开源化和模块化。
文章接下来反思了NVDLA的不足,并列出了从行业用户收集到的一些常见问题。首先,NVDLA在软件使用上的难度较大,特别是在汽车行业,CPU端需要大量工作来准备数据,导致工程师更倾向于使用着色器核心或SIMT(单指令多线程)。其次,在服务器端的可扩展性方面,NVDLA的控制模块(CSC)存在性能瓶颈,每一步计算需要“锁定”,无法提升计算能力。再者,构建基于NVDLA的SOC成本较高,虽然理论上可以在没有CPU的情况下构建SOC,但实际上仍需依赖CPU配置寄存器并添加内存控制器等组件。
文章提到,尽管NVDLA发布已有七年,作者和其公司NProcessor曾尝试将NVDLA扩展至自动驾驶应用,但由于软件栈、可扩展性和验证等问题未能成功。尽管如此,作者依然继续在空闲时间维护soDLA,并为其添加了更多集成和验证功能。
未来的计划是将NVDLA转变为一个更加友好于软件和低端处理器的IP,并支持更好的可扩展性。目标是使NVDLA能运行主流框架,并且可以轻松集成到低功耗的FPGA中,同时解决现有的可扩展性问题。
https://zhuanlan.zhihu.com/p/20330072886
OpenManus 是来自MetaGPT等的 @mannaandpoem @XiangJinyu @MoshiQAQ @didiforgithub和@Xinyu Zhang等,在 3 小时内推出开源项目,简单实现Manus的功能。此外,他们还推出了开源项目OpenManus-RL,致力于基于强化学习 (RL)(例如 GRPO)的 LLM 代理调整方法,由 UIUC 和 OpenManus 的研究人员合作开发。
https://github.com/mannaandpoem/OpenManus
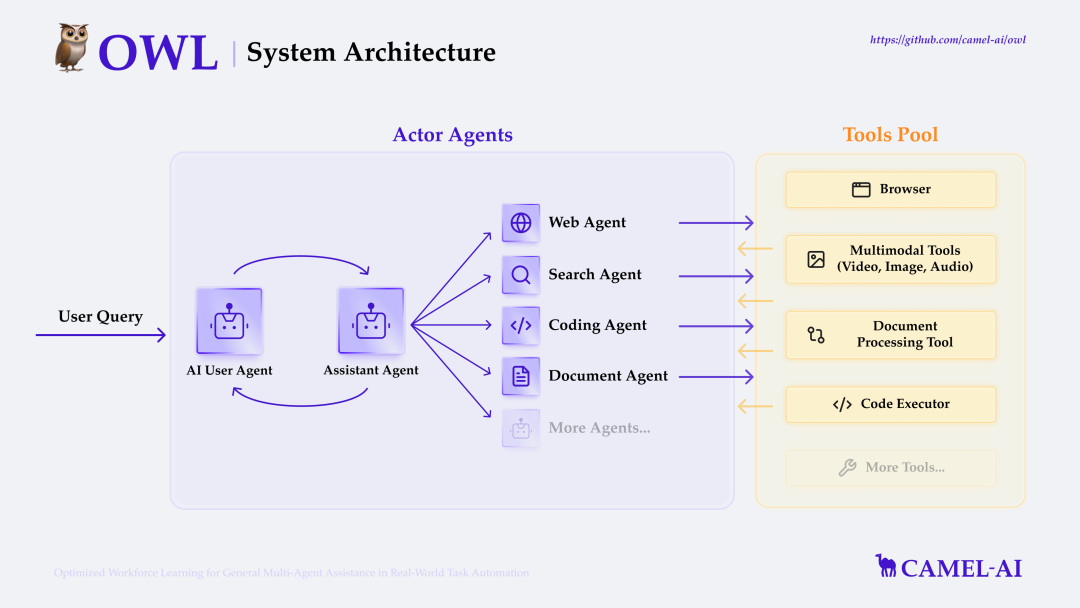
OWL是多智能体协作框架,推动任务自动化的边界,构建在 CAMEL-AI Framework下,用于处理现实世界的自动化任务。OWL 在 GAIA 基准测试中取得 58.18 平均分,在开源框架中排名第一。- 在线搜索:使用维基百科、谷歌搜索等,进行实时信息检索
- 浏览器操作:借助Playwright框架开发浏览器模拟交互,支持页面滚动、点击、输入、下载、历史回退等功能
- 文件解析:word、excel、PDF、PowerPoint信息提取,内容转文本/Markdown
https://github.com/camel-ai/owl?tab=readme-ov-file
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43295.html