
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


潜空间第六季活动开始报名!!
【第 2 期嘉宾介绍】杨松琳——MIT计算机科学与人工智能实验室二年级博士生。专注线性注意力机制、机器学习与大语言模型交叉领域,聚焦高效序列建模的硬件感知算法设计。围绕线性变换、循环神经网络优化开展研究,在多任务中取得成果,多篇论文被 ICLR 2025、NeurIPS 2024 等顶会收录;还开源 flash-linear-attention 项目,助力领域发展。本次活动她将带来《下一代LLM架构展望》的主题分享

学习
给定计算预算下的最佳LLM模型尺寸与预训练数据量分配
在大语言模型(LLM)的训练过程中,计算预算、模型参数量和训练数据量之间存在着密切关系。为了在给定计算预算下获得最佳的训练效果,如何合理地分配计算资源以平衡模型的尺寸和训练数据量,是一个关键问题。文中介绍了一种通过实验探索的最佳分配策略。
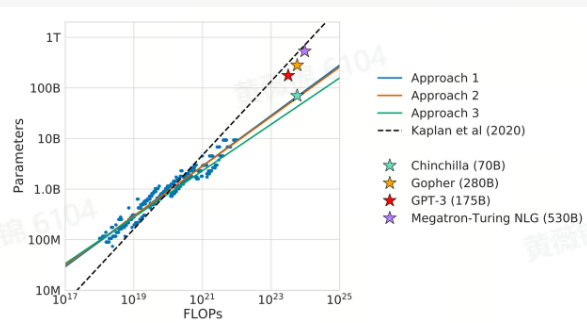
根据大语言模型的尺度扩展规律(Scaling Laws),模型的性能随着模型参数量、训练量和训练数据量的增加而提高。然而,如何在有限的计算预算下进行合理的资源分配,才能使模型的预训练损失最小化,是需要仔细分析的。为此,作者进行了大量实验,遍历了不同模型尺寸(从70M到16B参数)和预训练数据量(从5B到400B Tokens),通过超过400个数据点的实验结果来揭示计算预算下最佳的模型尺寸和训练数据量的关系。
通过固定模型尺寸和遍历不同数量的Token训练,作者发现,在每个给定计算量(FLOPs)下,不同的模型尺寸在达到最小训练损失时,所需的训练数据量有所不同。在某些情况下,较大尺寸的模型反而需要更多的训练Token才能达到最佳效果。此外,作者采用了三种方法来探索模型尺寸与训练数据量之间的比例关系,进一步推导出不同计算预算下的最优模型尺寸和训练Token数量。
在固定计算预算的情况下,作者通过调整训练Token数量,使得总计算量(FLOPs)保持恒定,观察到某些模型尺寸会出现损失低谷,这表明在给定FLOPs计算预算下,存在一个最优的模型尺寸。通过这些低谷点,作者能够推算出最适合的模型参数量和训练数据量。
作者进一步对损失函数进行了参数化拟合,使用L-BFGS算法最小化Huber损失,对不同实验点进行拟合,得出更为准确的最优模型尺寸和训练数据量估计。最终,通过这些方法,得出了在给定计算预算下的最佳模型尺寸和训练数据量,得出了例如Gopher模型的最佳计算预算(FLOPs)为5.76 × 10²³,而最佳的模型尺寸大约为70B,训练Token数量为1.4到1.5T。
最后,通过实验比较,作者验证了在固定计算预算下,Chinchilla模型(70B参数)在多个语言下游任务上,相较于Gopher和其他大型模型(如Megatron-NLG 530B)表现出色,甚至在某些任务中超过了530B的模型。
总的来说,本文的研究表明,在给定计算预算下,存在一个最佳的模型尺寸与训练数据量配比。对于大规模预训练模型,越大的模型通常需要更多的训练数据才能充分发挥其潜力。然而,模型训练和推理计算的分配并非是完全可互换的,预训练仍然是提升模型全方面性能的关键。因此,如何在预训练和推理之间合理分配计算预算,仍然是一个值得深入探讨的课题。
https://zhuanlan.zhihu.com/p/28222956720
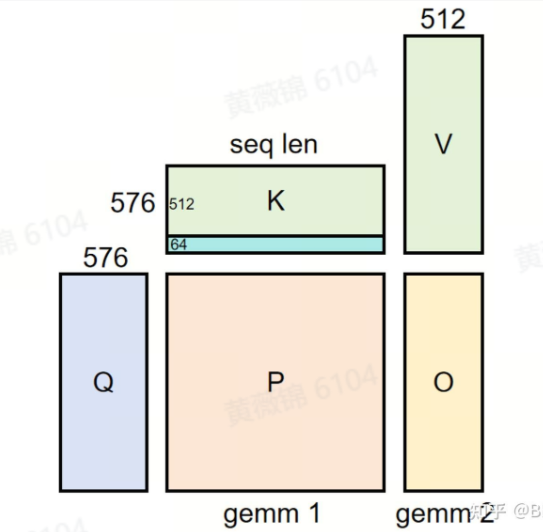
SGLang MLA 实现解析
本文详细分析了一下 SGLang MLA 的代码实现,并且指出了矩阵吸收以及FlashMLA应该应用的位置
https://zhuanlan.zhihu.com/p/28199298728
最大可验证代码合成数据的背后:合成数据的危与机
在微软GenAI实习期间,作者参与了合成数据的项目,并且与团队发布了名为KodCode的数据集,这个数据集包含了447K个可验证结果的代码题,涵盖了12种不同的数据源。为了确保数据集的质量,他们使用了5种不同的合成方法并利用大量的计算资源进行验证。KodCode主要面向Code RL(强化学习)应用,并提供了基于RL的合成数据,能有效提升模型的性能。为了进一步支持模型训练,还发布了246K的SFT数据集(包括R1 Reject Sampling)。该项目通过Hugging Face平台对外公开,供开发者和研究人员使用。
在这一过程中,作者深刻感受到了合成数据在现代AI模型中的作用和挑战。尤其是合成数据的生成方式,最初主要分为两类:生成问题和生成答案。然而,随着RL(强化学习)的发展,生成答案的任务变得不再重要,重点转向了如何生成“验证器”(Verifier),即通过“问题-验证器”对生成的答案进行验证。虽然生成验证器的过程仍存在许多挑战,尤其是在生成数学或代码任务的验证器时,LLM(大型语言模型)在提供可靠验证的能力上仍然面临巨大困难。即使在代码问题上,尝试了自验证方法,通过生成函数和单元测试并执行测试,发现模型的解决方案正确率仅为97%,其余3%存在误解或没有涵盖所有边缘情况。
另一个问题是合成数据中的“问题生成”。当前的LLM生成的新问题通常与原始问题接近,缺乏足够的创造性,无法生成真正具有挑战性和新颖性的问题。这使得合成数据的生成趋向于依赖人工标注,尤其是在一些稀缺领域或模态中,这也限制了合成数据的应用范围。
尽管合成数据面临这些挑战,它仍然具有重要的应用潜力。尤其是在资源稀缺的领域或模态(如数学和代码)中,合成数据通过提供大量样本,能够弥补数据短缺的问题。此外,随着隐私保护的日益重要,合成数据可以在保护用户隐私的前提下提供训练数据,尤其是对于包含敏感信息的数据集,合成数据能够避免隐私泄漏的风险。
https://zhuanlan.zhihu.com/p/27513633121
Muon续集:为什么我们选择尝试Muon?
在最新的技术报告《Muon is Scalable for LLM Training》中,团队分享了对Muon优化器的一次大规模实践,特别是针对一个3B/16B的MoE模型Moonlight的训练结果。实验结果表明,Muon优化器相比于传统的Adam优化器,能提升近2倍的训练效率。
Muon的设计理念与其他优化器的区别在于其核心目标是确保每一步更新既稳健又快速。稳健性要求更新对模型的扰动尽可能小,快速性则要求更新能够尽可能降低损失函数。这两个目标通过优化问题进行平衡,其中稳健性通过约束更新量来实现,而快速性通过寻找使损失函数下降最快的更新量来实现。Muon将这一理论引入实践,通过谱范数来控制更新的幅度,从而达到最优的损失函数下降。
优化器的理论基础依赖于矩阵范数的选择,稳健性通过限制梯度的谱范数来控制模型更新的幅度,进而避免梯度过大导致的训练不稳定。Muon的设计本质上是对梯度更新过程进行精细化调整,从而使训练过程更为高效、稳定。
在实际应用中,Muon表现出了强大的潜力,尤其在MoE等大规模模型的训练中。然而,Muon也面临一些挑战。例如,Weight Decay的加入在初期收敛较快,但没有及时调整时,可能导致模型收敛到次优解。对此,团队通过调整Weight Decay的策略,改善了Muon的性能,确保其始终优于Adam优化器。
此外,超参数调节是一个重要问题。为了加速优化器的超参数调节过程,团队提出了一种基于RMS对齐的迁移方法,能够将Adam调优后的超参数迁移到Muon中,避免了重复的搜索过程,并且在实践中得到了较好的效果。
通过对比实验,Muon在多个大规模模型上展示了比Adam更快的收敛速度和更好的最终效果。值得注意的是,Muon不仅能提升收敛速度,还能使模型参数的奇异值分布更加均匀,说明其能够更有效地利用模型的潜力。
报告也指出,在某些情况下,例如将Adam与Muon结合使用时,可能会遇到预训练效果不理想的问题。尽管如此,团队仍然认为Muon在未来的优化器领域中有着很大的应用潜力,尤其是在更大规模的模型训练中。团队计划继续深入研究Muon在模型预训练和微调中的表现,以及如何进一步优化其性能。

https://zhuanlan.zhihu.com/p/28129254107
我的 RL 人生哲学: 写给Sutton & Barto的图灵奖时
这篇文章回顾了强化学习(RL)领域的技术发展与经验教训,强调了“Bitter Lesson”(苦涩的教训)对RL学者的重要性。强化学习的根本是对人类经验的突破和克服偏见,依赖的是更强的算力和通用的方法而非依赖具体领域的知识。Sutton在其论文中指出,真正推动AI前进的应当是能够高效利用算力的算法,而人类的领域知识反而可能在AI的发展中成为障碍。作者提到,RL的成功不在于调整细节、技巧,而在于对算力的充分挖掘和规模化应用。
此外,Barto的演讲也指出了强化学习在探索与学习过程中的重要性。强化学习的本质不仅是算法技术的挑战,更是哲学性的问题:如何在有限的资源下探索,如何判断探索结果的好坏,以及如何在稀疏的信号中学习。这些问题不仅仅是AI的难题,也是每个人生路上的挑战。
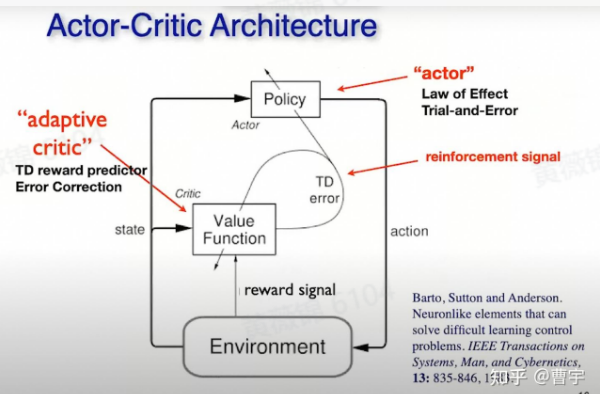
强化学习中,”Actor Critic” 架构的引入是一项重要创新,通过价值函数来判断行为的优劣,并通过价值与现实的差距调整策略。它在机器人控制、游戏AI、大模型对齐等领域的应用,进一步证明了RL的强大潜力。然而,这一切的核心依然是如何合理地使用“奖励”信号,以及如何通过对过往经验的总结和对未来行为的优化来持续提升性能。
作者强调了RL的“道”与“术”,指出在探索过程中需要保持耐心与冷静,而不是急功近利的追求技术的突破。尤其在面对RL中的不确定性和复杂性时,如何管理自己的探索与反馈过程,避免过度依赖短期的奖励或惩罚,才是进步的关键。
https://zhuanlan.zhihu.com/p/28202119556
Huggingface&Github
QwQ-32B:开源推理模型
QwQ-32B 是Qwen 系列的中等规模的推理模型,其性能可与当前最先进的推理模型(如智谱清言的 DeepSeek-R1、o1-mini 等)相媲美。
-
类型:因果语言模型
-
训练阶段:预训练和后训练(监督微调和强化学习)
-
架构:具有 RoPE、SwiGLU、RMSNorm 和 Attention QKV 偏差的 transformer
-
参数数量:32.5B
-
参数数量(非嵌入):31.0B
-
层数:64
-
注意力头 (GQA) 数量:Q 为 40 个,KV 为 8 个
-
上下文长度:全部 131,072 个词条

https://huggingface.co/Qwen/QwQ-32B
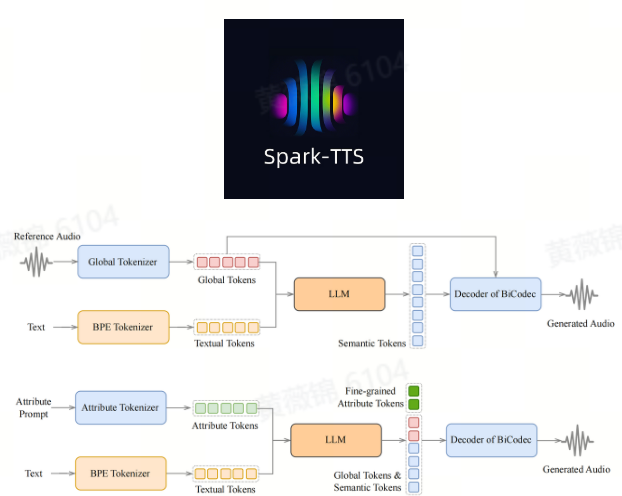
Spark-TTS-0.5B
Spark-TTS 星火语音合成模型是一款文本转语音系统,它借助大语言模型(LLM)的强大能力,实现了高度准确且自然逼真的语音合成效果。
-
星火语音合成模型完全基于通义千问 2.5(Qwen2.5)构建
-
高质量语音克隆:支持零样本语音克隆,即使没有针对特定语音的专门训练数据,它也能够复制说话人的语音。
-
双语支持:中文和英文。
-
可控的语音生成:支持调整性别、音高和语速等参数。
https://huggingface.co/SparkAudio/Spark-TTS-0.5B
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43273.html