
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


潜空间第六季活动开始报名!!
【第 2 期嘉宾介绍】杨松琳——MIT计算机科学与人工智能实验室二年级博士生。专注线性注意力机制、机器学习与大语言模型交叉领域,聚焦高效序列建模的硬件感知算法设计。围绕线性变换、循环神经网络优化开展研究,在多任务中取得成果,多篇论文被 ICLR 2025、NeurIPS 2024 等顶会收录;还开源 flash-linear-attention 项目,助力领域发展。本次活动她将带来《下一代LLM架构展望》的主题分享

学习
LLM洗数据[MinHash LSH去重] 总结笔记
上周合成了多轮对话数据,计划进行清洗。最近在简中网上学习了MinHash和LSH(局部敏感哈希)去重的内容,但发现对新手不太友好,尤其是到LSH部分,解释得不够清晰。于是我总结了一下,写了一个简单易懂的版本,以帮助自己更好地记忆,也希望能帮助其他人。
首先,简单复习一下Hash算法。Hash算法的基本作用是对输入数据进行计算,生成一个固定长度的输出,类似于数据的“指纹”。其主要用途是验证数据是否被篡改,如文件校验和密码存储。Hash算法的特点是,相同输入一定得到相同输出,而不同输入大概率会得到不同输出(不过存在碰撞的可能性)。常见的Hash算法有MD5、SHA-1、SHA-256等,不同算法的输出长度不同,MD5的输出长度为128位,SHA-1为160位,SHA-256为256位。MD5虽然很常用,但因为其输出长度较短,现在已经不推荐使用,容易受到碰撞攻击。
在实际应用中,Hash算法主要用来加速查找,比如哈希表。哈希表通过哈希函数将数据映射到存储位置,从而加速数据查询。哈希函数的设计目标是确保输出值均匀分布,避免冲突。如果发生冲突,可以采用线性探针、双哈希等方法解决。
然后,我们引入了Jaccard相似度,主要用于衡量两个集合的相似度,即交集大小与并集大小的比值。对于文档来说,Jaccard相似度就是两个文档词汇交集与并集的比值。但是,计算所有文档对之间的Jaccard相似度非常耗费资源,尤其是在文档数很多的情况下。为了解决这个问题,我们引入了MinHash。
MinHash通过降维的方式,快速估算Jaccard相似度。它的基本思想是,对于每个文档,我们通过多次哈希运算得到文档的MinHash签名,即每次哈希运算的最小值。MinHash签名的计算方式是:对文档的每个分词进行哈希运算,得到哈希值,然后取最小值作为该文档的代表。这样,通过比较MinHash签名的相似度,就能间接估算Jaccard相似度。通过增加哈希函数的数量,MinHash的估算精度会更高。比如,经过5次哈希运算得到的MinHash相似度是0.6,经过1000次哈希运算后的MinHash相似度接近Jaccard的真实值0.4285。
接下来是LSH(局部敏感哈希)。LSH的核心思想是利用哈希冲突将相似的文档分组,从而避免两两全量比较。首先,我们将文档的MinHash签名分成多个band,每个band再通过哈希函数进行映射。具有相同映射值的文档会被分到同一个桶中。LSH通过这种方式,把文档分到不同的桶里,相似的文档很有可能出现在同一个桶中。之后,我们只需要在同一个桶内进行两两比较,而不是在所有文档之间进行比较。
具体来说,如果分成4个band,每个band用32位的哈希值表示,那么每个文档就会被分成4个部分,分别用不同的哈希函数映射。举个例子,假设文档A和文档B在第二个band上哈希值相同,那么它们就会被分到同一个桶中。之后,我们就可以在桶内进行相似度计算,进一步确定它们的相似度是否超过预设的阈值。
使用MinHash和LSH的代码示例也非常简洁。首先,我们创建一个MinHash对象,并通过update()方法对每个词汇进行更新,最终生成MinHash签名。然后,通过MinHashLSH对象将文档插入LSH中,文档就会被自动分到相应的桶中。查询时,我们可以用query()方法检查当前文档所在桶中的文档,计算相似度并返回相似文档的ID。

https://zhuanlan.zhihu.com/p/27712794839
llm+rl训练项目的一些takeaway
本文讨论了多种基于强化学习(RL)的方法及其在语言模型(LLM)中的应用。首先,OpenRLHF框架以及它的实现verl(Volcano Engine)被提及,verl通过结合FlashRag提升了7B模型在HotpotQA上的表现,旨在通过多次检索让模型学会更复杂的推理过程。SimpleRL则基于OpenRLHF框架进行复现,主要用于小模型(7B)在数学任务中的训练,采用PPO算法,结合长链推理(long-cot)初始化,观察到在RL的初期,模型的响应长度呈现先下降后上升的趋势,猜测是模型在自我探索新的推理方式。
TinyZero是另一个RL微调的示例,使用3B模型解决计数倒数任务,表现出类似的响应长度波动现象。Self-rewarding方法通过模型自我验证并修正答案,分为两个训练阶段:self-reward IFT和RL训练,依赖模型根据最后一轮的答案给予奖励。
Ragen框架探讨了更具代理性的任务,如多臂老虎机和推箱子等简单游戏,采用RL和LLM相结合的方式,奖励设计较为简单,但也会遇到任务无解时的循环问题,强调了prompt多样性和在线rollout频率的重要性。
Search-R1框架在NQ数据集上进行标准答案搜索任务的训练,3B模型同样表现出响应长度的波动,最后趋于稳定。Logic-RL研究了7B模型在数学和逻辑推理任务中的表现,发现更长的回答不一定意味着更好的推理过程,语言混合现象可能会影响推理效果,而RL能更好地进行泛化,相比SFT,它在训练中更具灵活性。
ORZ框架强调了RL训练中的数据和模型规模对效果的影响,设置了λ和γ为1,并去除了KL惩罚项,发现32B模型相比7B模型更快获得更高的奖励。
PRIME则探索了隐式过程奖励(PRM),使用ORM估算PRM的值,并通过此方式优化模型的行为。RLSP方法提出基于生成的回答长度和创造性奖励的概念,奖励设计上前期偏向探索,后期转向结果的奖励。
最后,DeepSeek-R1-Zero的复现实验显示,与深度模型蒸馏相比,直接对小模型进行RL微调的效果较差。实验还发现,即使没有显式的“逐步思考”提示,模型仍能自主形成“思考”行为。RL微调的效果和奖励设计密切相关,简单的数学题目可以通过规定正确答案来获得奖励,且对格式的惩罚影响较小。
https://zhuanlan.zhihu.com/p/27973092256
R1相关:RL数据选择与Scaling
本文介绍了两篇关于强化学习(RL)规模扩展的研究,主要探讨数据对RL效果的影响,并得出了一些互补性的结论。
第一篇论文《LIMR: Less is More for RL Scaling》聚焦于RL训练数据的选择,而非算法优化。作者指出,现有的RL研究大多侧重于算法设计,但对数据规模和质量的研究相对缺乏。研究发现,扩大训练数据集的规模并不一定能提高模型性能,关键在于选择有价值的样本。LIMR提出了一种自动定量评估方法(LIM),通过计算每个样本在训练过程中的奖励曲线,量化样本对整体学习轨迹的贡献。实验结果表明,精心选择的1389个样本的效果优于数量更多的样本集(如8523个样本)。这一发现表明,在RL训练中,选择高质量的样本,而非仅仅扩展数据量,能更有效地提升推理能力。尤其在小模型(如7B)中,RL比SFT(监督微调)更能提升推理性能。
第二篇论文《Open-Reasoner-Zero (ORZ)》则探讨了RL在模型规模扩展中的应用。ORZ的研究发现,RL在推理任务中的性能提升主要来自于数据量、模型大小和训练迭代的扩展,而算法设计的复杂性影响较小。实验中,ORZ使用了简化的基于规则的奖励函数,并去除了KL惩罚项,这简化了训练流程。结果表明,适量的训练数据、模型规模的扩展以及较长的训练周期是提升模型推理能力的关键。此外,GAE(广义优势估计)在推理任务中的表现也得到了强调,特别是当γ和λ参数设置为1时,GAE在优化过程中发挥了关键作用。ORZ的研究还证明,模型在经历适当的训练后,能够在推理任务中表现出更好的响应长度和推理能力。
两篇研究尽管在数据处理的方向上有所不同,但它们的结论是互补的。LIMR强调了数据选择的重要性,而ORZ则通过扩大数据规模来增强模型性能。两者的核心思想是,数据的选择和分布对于激活模型能力至关重要,选择合适的数据能够更好地促进模型性能的提升。
综上所述,这两篇论文在强化学习的规模扩展领域提供了不同的视角,LIMR通过数据精挑细选提高模型效果,而ORZ则通过大规模数据和简单的奖励函数优化提升了推理任务的性能。这些研究为进一步改进RL训练方法和提高大模型推理能力提供了新的思路。
https://zhuanlan.zhihu.com/p/27510448395
Mooncake KVcache storage是如何提升LLM的能力
在LLM推理过程中,生成每个新token时需要进行attention操作,而这个过程会反复访问之前生成的Key/Value Cache(KVCache)。在Prefill阶段,所有输入tokens会一次性处理并缓存K/V,而在Decoding阶段,随着新token的生成,会逐个访问之前的KVCache。传统的LLM推理系统采用本地KVCache策略,将缓存存放在每个节点的HBM和DRAM中,但这种方法存在一些限制。由于缓存容量小,且无法跨节点共享,Cache命中率较低,导致Prefill阶段可能会进行大量重复计算。
随着长上下文的需求增加,KVCache的管理变得越来越重要。在LLM中,每个token的K/V向量需要存储在KVCache中,而随着上下文长度的增加,KVCache的使用量也会急剧增大。例如,对于LLaMA3-70B模型,假设每层的K/V向量维度为8192,且上下文长度为128k tokens,那么所需的KVCache容量可能达到320GB,远超过单张显卡的显存容量。这导致Prefill计算量随着上下文长度的增加而爆炸性增长,每个新token都需要与之前所有tokens进行attention操作,极大地增加了计算压力。
为了解决这个问题,Mooncake提出了分布式的KVCache管理方式。Mooncake采用了“More Storage for Less Computation”的策略,打破了传统vLLM的本地KVCache限制,提供了分布式的全局KVCache存储。它利用整个GPU集群的CPU、DRAM、SSD和NIC资源,允许不同节点的请求共享KVCache,从而避免重复的Prefill计算,提升了缓存命中率,降低了计算开销。
Mooncake的KVCache体系包括多层缓存设计:GPU VRAM用于存储最热的KVCache,保证高效解码;本地DRAM存储当前节点的热数据;全局分布式KVCache Pool则用于跨节点共享,冷数据存储在远程DRAM或SSD中。通过分离Prefill和Decoding集群,Mooncake实现了异步流水线式的KVCache管理,使得Prefill计算和逐token生成解耦。
此外,Mooncake还引入了分布式KVCache调度器,优先调度Cache命中率高的节点,并通过RDMA传输技术优化缓存加载速度,提升了数据传输效率。实验表明,Mooncake的KVCache命中率比传统方法提升了2.36倍,Prefill阶段的GPU时间减少了64%。
这种全局KVCache优化架构的优势在于:它解决了传统本地缓存容量有限的问题,并通过高效的缓存管理和调度,显著提升了LLM推理性能。在未来,大规模LLM推理的瓶颈将不再是计算,而是带宽和缓存管理。因此,分布式缓存和Cache-aware调度成为了优化LLM性能的关键。
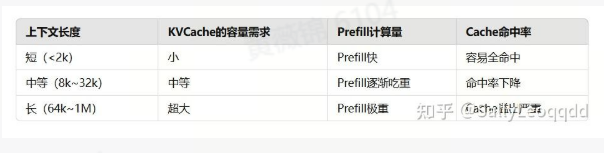
https://zhuanlan.zhihu.com/p/28072165267
一种基于cache机制的video diffusion模型的推理加速方法
本文提出了一种名为FasterCache的新策略,用于加速视频扩散模型的推理过程,同时确保生成视频质量的保持。该方法通过动态调整特征复用,避免了传统缓存机制中相邻时间步之间细微差异的丢失,从而提高了视频生成的细节质量,并加速了推理过程。FasterCache的主要创新包括引入了动态特征复用策略和CFG-Cache模块。在传统的基于缓存的加速方法中,特征复用的做法通常忽略了时间步之间的细微差别,这导致了生成视频中细节的退化。FasterCache通过动态调整时间步之间的特征复用,确保特征的差异得到有效保留,避免了细节损失。
此外,文章还探讨了CFG(Classifier-Free Guidance)模块中的冗余现象,发现同一时间步的条件输出和非条件输出之间具有较大的相似性,这为加速提供了潜在的机会。FasterCache通过优化这些输出的复用,提出了CFG-Cache策略,使得条件和无条件输出之间的差异得到有效处理,进一步加快了推理速度并提高了视频生成质量。
实验表明,FasterCache在多个视频生成模型上取得了显著的加速效果,且生成视频的质量与原始模型相当,甚至优于现有的一些加速方法。与传统的缓存加速方法相比,FasterCache能够显著减少推理时间,同时保持更高的视频质量。作者还通过实验验证了该方法在不同视频分辨率、长度以及采样调度器上的稳定表现。
FasterCache的核心思想是动态特征复用和高效的CFG模块加速,结合自适应的缓存策略,能够在不增加训练成本的情况下,提升视频扩散模型的推理效率。虽然该方法在复杂场景下可能存在一定局限性,但总体而言,它为视频生成任务提供了一种高效且无训练成本的加速解决方案,为大规模视频生成的应用场景提供了更为有效的技术路径。
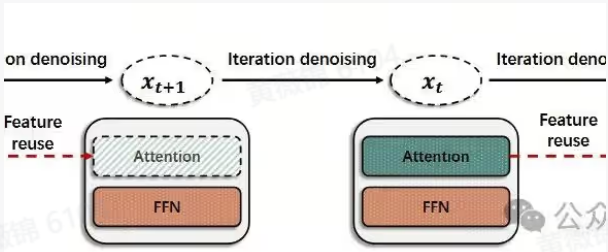
https://zhuanlan.zhihu.com/p/27783512611
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43250.html