我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
信号 PokerBench: Training Large Language Models to become Professional Poker Players 我们引入了 PokerBench——用于评估大型语言模型 (LLM) 玩扑克的能力的基准。由于 LLM 在传统的 NLP 任务中表现出色,因此将其应用于扑克等复杂的战略游戏提出了新的挑战。扑克是一种不完全信息游戏,需要多种技能,例如数学、推理、规划、策略以及对博弈论和人类心理学的深刻理解。这使得扑克成为大型语言模型的理想下一个前沿。PokerBench 包含 11,000 个最重要的场景的综合汇编,分为翻牌前和翻牌后游戏,与训练有素的扑克玩家合作开发。我们评估了包括 GPT-4、ChatGPT 3.5 和各种 Llama 和 Gemma 系列模型在内的著名模型,发现所有最先进的 LLM 在玩最佳扑克方面表现不佳。然而,经过微调后,这些模型显示出显着的改进。 我们通过让具有不同分数的模型相互竞争来验证 PokerBench,证明 PokerBench 上的分数越高,实际扑克游戏中的获胜率就越高。通过我们微调后的模型与 GPT-4 之间的对战,我们还发现了简单的监督微调在学习最佳游戏策略方面的局限性,这表明需要更先进的方法来有效地训练语言模型以在游戏中脱颖而出。因此,PokerBench 提供了一个独特的基准,可以快速可靠地评估 LLM 的扑克游戏能力,同时也提供了一个全面的基准,可以研究 LLM 在复杂游戏场景中的进展。 原文链接:https://arxiv.org/abs/2501.08328 信号源:Richard Zhuang–University of California, Berkeley flash-linear-attention
Lightning Attention克服了这种缺陷,是如何做到的?
传统Linear Attention虽然计算复杂度降到了O(n),但是在因果(causal)推理时,往往需要cumsum操作,导致实际计算效率不高。
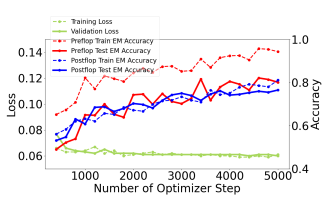
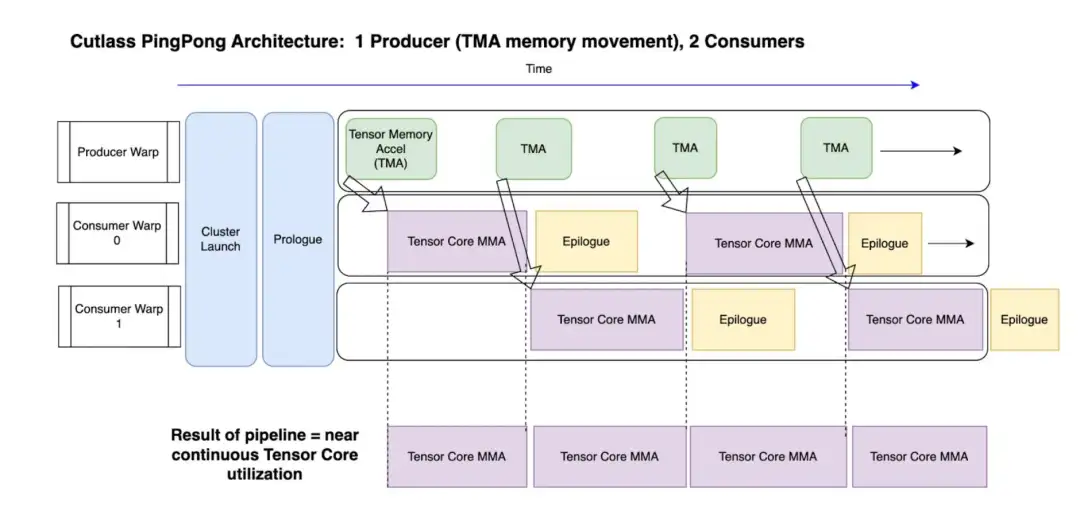
原文链接:https://github.com/fla-org/flash-linear-attention VEB-RL 将进化算法(EAs)和强化学习(RL)结合起来,以利用它们的互补优势来实现更高效的策略搜索是目前的一个很火的研究方向。下面介绍一个经典的混合算法ERL,窥一斑而见全身。ERL将遗传算法(GA)与DDPG结合。在ERL中,EA和RL同时进行优化。EA提供在种群评估过程中生成的样本给RL进行优化,旨在提高样本效率。反过来,RL将优化后的RL策略注入种群中,参与进化过程。ERL将种群中策略的Fitness(适应度)定义为与环境交互的几轮的平均累积奖励,这随后成为ERL相关工作的常用Fitness度量方式。 之后很多EA与RL的混合算法被提出,例如结合CEM和TD3的CEM-RL,构建了专注于提升网络参数优化的高效演化算子的PDERL,超参数调优的CERL,构建了基于Critic的Fitness Surrogate的SC算法,构建了种群直接影响RL参数的Supe-RL,融合了ERL,CEM-RL,SC并引入P3S思想的PGPS,将个体策略拆解为共享表征与独立的策略表征的ERL-Re^2,以及我上一篇工作介绍的EvoRainbow等。 可以看到,以往将EAs与RL结合的方法主要集中在策略搜索,这些方法使用策略来构建种群,并根据与环境交互所获得的累积奖励对个体进行排名,从而得到更好的策略。那我们在面对Value-based RL的时候该怎么做呢? 项目连接:https://github.com/yeshenpy/VEB-RL 信号源:Bridging Evolutionary Algorithms and Reinforcement Learning: A Comprehensive Survey on Hybrid Algorithms Deep Dive on CUTLASS Ping-Pong GEMM Kernel 在这篇文章中,我们将概述 CUTLASS Ping-Pong GEMM kernel ,并提供相关的 FP8 推理kernel 基准测试。 Ping-Pong 是 Hopper GPU 架构上可用的最快矩阵乘法(GEMM)kernel 架构之一。Ping-Pong 属于 Warp Group Specialized Persistent Kernels 家族,该家族包括 Cooperative 和 Ping-Pong 两种变体。相对于之前的 GPU,Hopper 的强大Tensor Core计算能力需要深度异步软件流水线来实现峰值性能。 Ping-Pong 和 Cooperative kernel 很好地展示了这一范式,其关键设计模式是持久化kernel (用于摊销启动和prologue开销),以及”全面异步”的专门化 warp 组(包含两个消费者和一个生产者),以创建高度重叠的处理流水线,能够持续为Tensor Core提供数据。 当 H100 (Hopper) GPU 发布时,Nvidia 将其称为第一款真正的异步 GPU。这一说法突出了 H100 特定kernel 架构也需要异步化,以充分最大化计算/GEMM 吞吐量。 CUTLASS 3.x 中引入的 pingpong GEMM 通过将kernel 的所有方面都移至”完全异步”处理范式来体现这一点。在这篇博客中,我们将展示 ping-pong kernel 设计的核心特性,并展示其在推理工作负载上与 cublas 和 triton split-k kernel 相比的性能。 原文链接:https://pytorch.org/blog/cutlass-ping-pong-gemm-kernel/ How GPT learns layer by layer 大型语言模型 (LLM) 在语言处理、策略游戏和推理等任务上表现出色,但难以构建可泛化的内部表征,而这对于代理的自适应决策至关重要。为了让代理有效地驾驭复杂的环境,它们必须构建可靠的世界模型。虽然 LLM 在特定基准上表现良好,但它们往往无法泛化,导致脆弱的表征限制了它们在现实世界中的有效性。了解 LLM 如何构建内部世界模型是开发能够在任务之间保持一致、自适应行为的代理的关键。我们分析了 OthelloGPT,这是一个基于 GPT 的模型,在 Othello 游戏玩法上进行训练,作为研究表征学习的受控测试平台。尽管 OthelloGPT 仅针对具有随机有效移动的下一个标记预测进行训练,但它在理解棋盘状态和游戏玩法方面表现出有意义的分层进展。早期层捕获棋盘边缘等静态属性,而更深的层则反映动态图块变化。为了解释这些表示,我们将稀疏自动编码器 (SAE) 与线性探测器进行了比较,发现 SAE 提供了对组合特征更稳健、更清晰的洞察,而线性探测器主要检测对分类有用的特征。我们使用 SAE 来解码与瓷砖颜色和瓷砖稳定性相关的特征,这是一个以前未经检验的特征,反映了复杂的游戏概念,如棋盘控制和长期规划。我们使用 SAE 和线性探测器研究线性探测器准确度和瓷砖颜色的进展,以比较它们在捕获模型正在学习的内容方面的有效性。虽然我们从较小的语言模型 OthelloGPT 开始,但这项研究建立了一个框架,用于更广泛地理解 GPT 模型、Transformers 和 LLM 学习的内部表示。
信号源:Jason Du–Department of Electrical Engineering and Computer Sciences, University of California, Berkeley
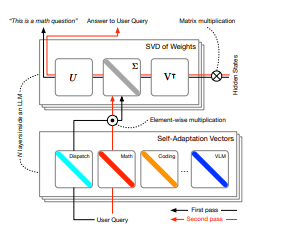
原文链接:https://arxiv.org/abs/2501.07108 Transformer2: Self-adaptive LLMs
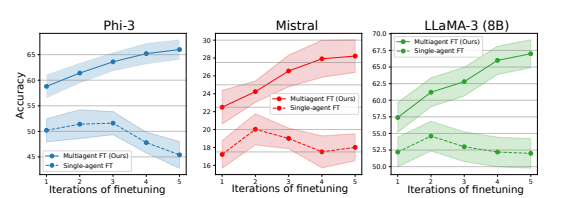
大型语言模型 (LLM) 旨在解决传统微调方法带来的挑战,这些方法通常需要大量计算,并且在处理各种任务的能力上是静态的。我们引入了 Transformer2,这是一种新颖的自适应框架,它通过选择性地仅调整权重矩阵的奇异分量,实时调整 LLM 以适应未见过的任务。在推理过程中,Transformer2 采用两遍机制:首先,调度系统识别任务属性,然后使用强化学习训练的任务特定“专家”向量进行动态混合,以获得针对传入提示的目标行为。我们的方法优于 LoRA 等普遍使用的方法,参数更少,效率更高。Transformer2 展示了跨不同 LLM 架构和模式的多功能性,包括视觉语言任务。 Transformer2 代表着一次重大的飞跃,它为增强 LLM 的适应性和特定任务性能提供了可扩展、高效的解决方案,为真正动态、自组织的 AI 系统铺平了道路。 原文链接:http://arxiv.org/abs/2501.06252v2 Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains 大型语言模型 (LLM) 近年来取得了显著的表现,但从根本上讲受到底层训练数据的限制。为了在训练数据之外改进模型,最近的研究探索了如何使用 LLM 生成合成数据以实现自主自我改进。然而,自我改进的连续步骤可能会达到收益递减点。在这项工作中,我们提出了一种自我改进的补充方法,其中将微调应用于多智能体语言模型社会。一组语言模型都从同一个基础模型开始,通过使用模型之间多智能体交互生成的数据更新每个模型,从而独立地进行专业化。通过在独立的数据集上训练每个模型,我们说明了这种方法如何实现跨模型的专业化和模型集的多样化。因此,与单智能体自我改进方法相比,我们的整体系统能够保留多样化的推理链,并在更多轮微调中自主改进。我们定量说明了该方法在一系列推理任务中的有效性。
原文链接:https://arxiv.org/abs/2501.05707v1
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/33467.html