我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


信号
Optimizing Return Distributions with Distributional Dynamic Programming
本研究介绍了分布式动态规划(distributional DP)方法在优化回报分布的统计函数方面的应用,其中标准强化学习是其特殊情况。之前的分布式动态规划方法只能优化与经典动态规划相同类别的期望效用函数。为了超越期望效用的限制,作者将分布式动态规划与“状态增强”(stock augmentation)相结合,这种技术此前在风险敏感强化学习中应用于经典动态规划,通过在状态中加入累计奖励的统计信息的方式。研究发现,许多最近研究的问题可以表述为状态增强的回报分布优化问题,并证明可以使用分布式动态规划解决这些问题。文中分析了分布式值迭代和策略迭代的理论边界以及这些方法能优化的目标类型。作者还描述了分布式动态规划在不同问题中的应用,如优化条件风险价值和实现动态平衡调节。最后,结合分布式值迭代和深度强化学习(如DQN代理),对所述方法在实际应用中的潜力进行了实证评估。
原文链接:https://arxiv.org/abs/2501.13028
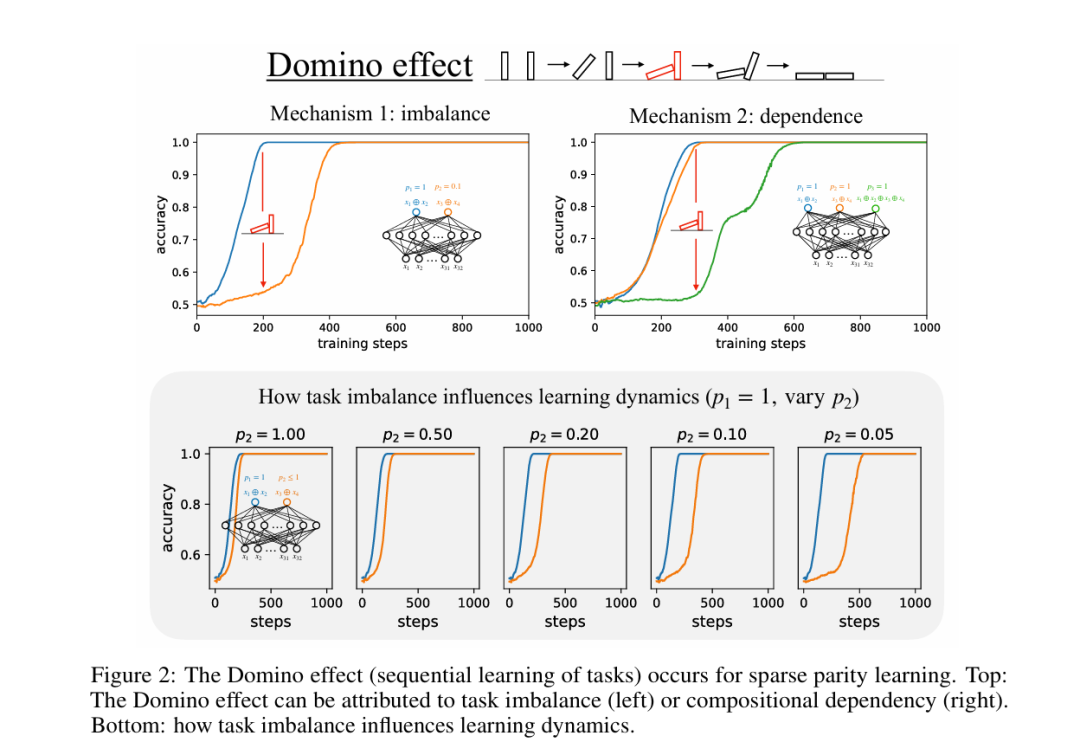
Physics of Skill Learning
本文研究了技能学习的物理机制,即神经网络在训练过程中如何学习技能。作者首先观察到“多米诺效应”,即技能是顺序学习的,特别是某些技能在其他技能学习完成后开始学习,这类似于多米诺牌的顺序倒下。为了理解这一现象,作者借鉴物理学家的抽象与简化方法,提出了三个模型:几何模型、资源模型和多米诺模型,它们在现实与简化之间进行权衡。这些模型展示了不同的抽象与简化层次,每个模型有助于研究技能学习的不同方面。几何模型揭示了神经扩展法则和优化器的有趣见解;资源模型对组成性任务的学习动态提供了洞察;多米诺模型则展示了模块化的好处。这些模型不仅在概念上具有趣味性(例如,几何模型可以推导出Chinchilla扩展法则),还在实践中对算法开发具有启发作用(例如,基于这些模型的简单算法修改可以加速深度学习模型的训练)。
原文链接:https://arxiv.org/abs/2501.12391
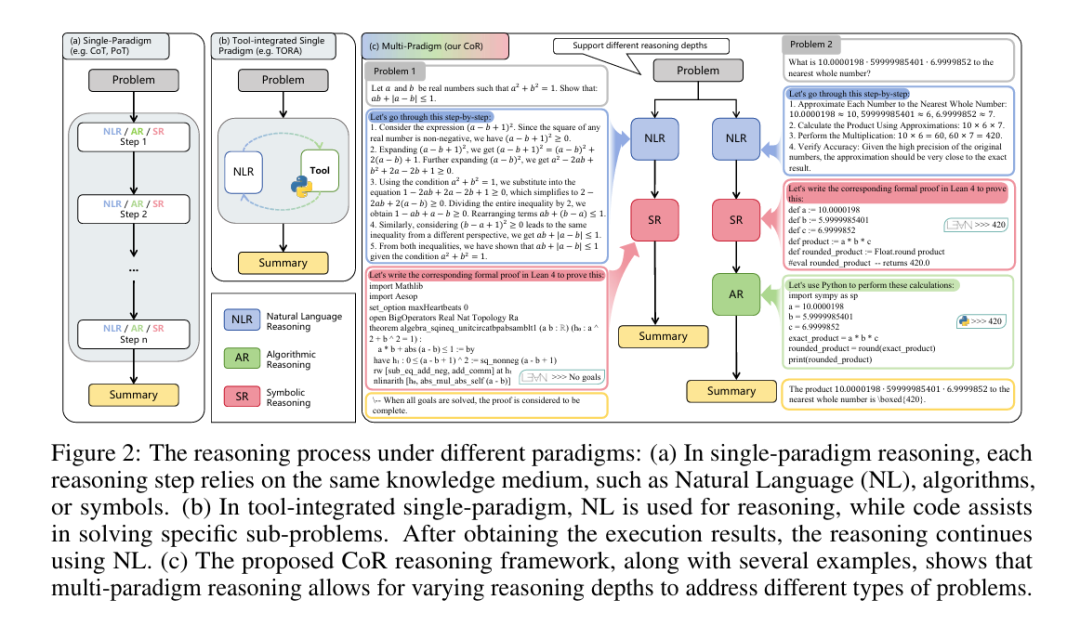
Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective
本文提出了链式推理(Chain-of-Reasoning, CoR)框架,这是一种整合多种推理范式的新方法,用于提升大型语言模型(LLMs)在数学推理任务中的表现。传统LLMs通常依赖单一推理范式,限制了它们在多样化任务中的表现。CoR框架结合了自然语言推理(NLR)、算法推理(AR)和符号推理(SR),通过多种推理范式生成潜在答案并综合成最终解答。此外,作者提出了渐进式范式训练(Progressive Paradigm Training, PPT)策略,使模型逐步掌握这些推理范式,并据此开发出CoR-Math-7B模型。实验结果表明,CoR-Math-7B在数学推理任务中显著优于当前SOTA模型,在定理证明任务中相较GPT-4实现了高达41.0%的提升,在算术任务中比基于强化学习的方法提升了7.9%。这些结果表明该模型不仅在特定任务上表现出显著优势,还具备跨任务的零样本泛化能力。
原文链接:https://arxiv.org/abs/2501.11110
HuggingFace&Github
00Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
DeepSeek-R1 WebGPU:在浏览器本地运行的下一代推理模型
https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/36562.html