
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


潜空间第六季活动开始报名!!
【第 2 期嘉宾介绍】杨松琳——MIT计算机科学与人工智能实验室二年级博士生。专注线性注意力机制、机器学习与大语言模型交叉领域,聚焦高效序列建模的硬件感知算法设计。围绕线性变换、循环神经网络优化开展研究,在多任务中取得成果,多篇论文被 ICLR 2025、NeurIPS 2024 等顶会收录;还开源 flash-linear-attention 项目,助力领域发展。本次活动她将带来《下一代LLM架构展望》的主题分享

学习
深度学习的分布式训练与集合通信(三)
本专题讨论了深度学习分布式训练中常见的并行策略以及相关的集合通信操作。重点介绍了多个并行方案,如数据并行(DP)、模型并行(TP)、序列并行(SP)、上下文并行(CP)及混合序列并行(Ulysess)等,并分析了它们在训练过程中的通信模式和效率。
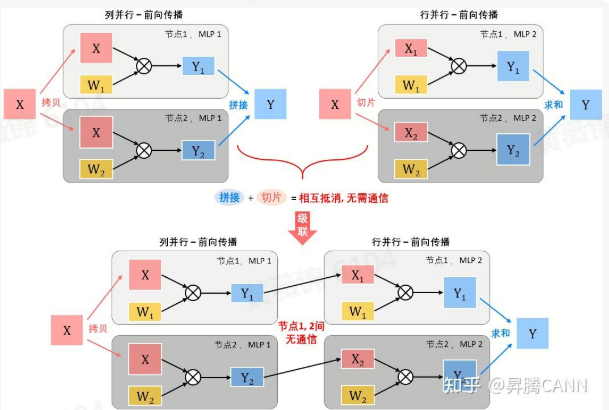
序列并行是一种细粒度的数据并行,专为处理Transformer模型中超长上下文的序列数据而设计。序列并行的核心思想是将输入的序列切分为多个片段,在多个节点上并行计算,从而突破单卡存储限制,特别适用于长序列的训练。序列并行可分为两种应用:一种是在Attention阶段(例如Colossal-AI的序列并行和Megatron-LM的上下文并行),另一种则是在LayerNorm和Dropout阶段。Attention阶段的序列并行主要是减少存储压力,通过按列分割输入的token矩阵,实现矩阵乘法时的并行计算。在这种方式下,常见的通信操作包括AllGather(收集矩阵数据)和ReduceScatter(分散计算结果)。此外,Causal Attention在计算时需要特别处理以提高通信效率。
在LayerNorm与Dropout阶段,序列并行则通过减少中间激活值的存储需求,配合TP的模型并行策略,减少了通信和计算开销。其通信模式涉及AllGather和ReduceScatter,确保节点间的计算负载均衡。
接着,ZeRO系列并行优化(尤其是ZeRO-3和完全分片数据并行FSDP)介绍了如何通过切分模型参数、梯度及优化器状态来减少内存开销。ZeRO的核心思想是通过通信代替存储,尽量避免每个节点存储完整的模型数据,减少冗余存储。FSDP进一步将模型参数和梯度进行切分,优化大规模模型的内存使用效率,广泛应用于LLM(大语言模型)训练中。
https://zhuanlan.zhihu.com/p/21892745224
Groq LPU 架构和LLM推理性能分析
Groq的TSP架构是基于”软件定义”的流处理设计,通过简化硬件控制,最大化计算和内存的利用率,主要应用于深度学习推理任务。与传统的CPU/GPU架构相比,TSP架构不依赖复杂的硬件调度控制,而是将调度任务交由软件处理。通过这一方式,TSP能够将更多的资源分配给计算单元和内存,从而提高效率。该设计的核心特点是确保计算、访存和通信的确定性,尤其是在高效执行时,避免DRAM的非确定性延迟,转而使用SRAM。
TSP芯片由多个Super Lane组成,每条Super Lane内部有矩阵处理单元(MXM)、内存单元(MEM)、向量处理单元(VXM)和数据交换单元(SXM)。每条Super Lane的设计都遵循16×32的SIMD架构,具有高效的指令流和数据流交互。数据流在流水线中流动,指令流通过指令控制单元(ICU)引导每个单元进行数据处理。与传统GPU不同,TSP摒弃了DRAM,完全依赖SRAM,以确保确定性操作。
在多芯片设计方面,Groq的TSP支持高效的跨芯片通信,完全依赖软件调度指令与数据流的时序安排。TSP的芯片间互联设计通过简化路由和数据收发的控制,避免了复杂的硬件调度,减少了传输延迟。通过与传统GPU的对比,TSP在小数据传输和低延迟推理中展现出明显的优势。
TSP的互联设计相较于传统GPU系统(如NVLINK)具有较高的效率,特别是在小数据量传输场景下。尽管TSP的带宽比NVLINK低,但在小批量数据传输中,TSP能够利用其低延迟的优势,大幅提高带宽利用率。这对于LLM(大型语言模型)推理尤其重要,因为这些模型在推理时常涉及小批量数据传输,Groq的设计能有效减少延迟。
尽管Groq的单卡内存较小,仅为230MB,但其通过优化计算和通信的方式,能够在低延迟推理任务中超越传统的GPU系统。进一步来看,Groq的设计也考虑到扩展性问题,支持多TSP芯片互联,并通过高效的集群拓扑结构进行大规模并行计算。这使得Groq在LLM推理任务中,尤其是在低延迟、低批量大小的场景中表现尤为突出。
尽管当前Groq TSP面临内存带宽的瓶颈,但通过对互联性能的进一步优化,未来可能在大规模并行推理任务中继续提升其性能。此外,Groq正在探索优化KV-Cache的方式,解决大模型所需的存储和内存带宽问题,未来可能针对更大规模的模型进行优化。总体来看,Groq的低延迟设计为LLM推理提供了一种高效的解决方案,在低延迟推理领域具有独特优势,尤其适合需要实时响应的应用场景。

https://zhuanlan.zhihu.com/p/684952952
2025 年的 RAG 之推理篇
DeepSeek R1在2025年初的发布大大提前了我们对LLM推理和决策能力的预期,使得LLM的推理能力成为研究的热点。本文主要讨论在LLM推理过程中,如何调整RAG(检索增强生成)框架以更好地配合推理任务。
LLM推理分为两类:Inference(训练推理)和Reasoning(推理)。后者指的是通过已知信息进行推演和综合,推导出新结论的过程,是LLM展现更大价值的核心驱动力。推理能力并非R1特有,2024年已经有Agent框架广泛使用推理,其中包括Plan、Memory、Action、Tool四个模块,ReAct是较为简单的实现方式。ReAct结合Reasoning与Action逐步生成推理步骤并依赖前一步结果,但这种推理方法较为线性,容易受前一环节错误影响,且并未充分发挥LLM的能力,因此对Agent的实际价值存在局限。
R1的创新在于通过强化学习训练鼓励LLM形成CoT(Chain of Thought,推理链),有效提升计算和推理能力。CoT通过将复杂问题分解为多个步骤,增加计算和信息处理环节,使得LLM可以逐步接近正确答案。与之相关的RAG框架则通过引入记忆模块和Agent机制,强化了推理的精准性。RAG的优势在于利用数据基座推动推理,使其更有针对性,避免单纯依赖LLM和简单工具的局限性。
推理本质上是对求解空间的搜索,在RAG中,通过启发式搜索和增量微调来优化推理过程。引入蒙特卡洛树搜索(MCTS)作为启发式搜索,有助于避免陷入局部最优,提高推理质量。但MCTS需要大量计算,并且依赖于奖励函数或模型进行评估,因此在工程实现上较为复杂。通过MCTS,RAG能够在特定领域提供更好的推理路径。
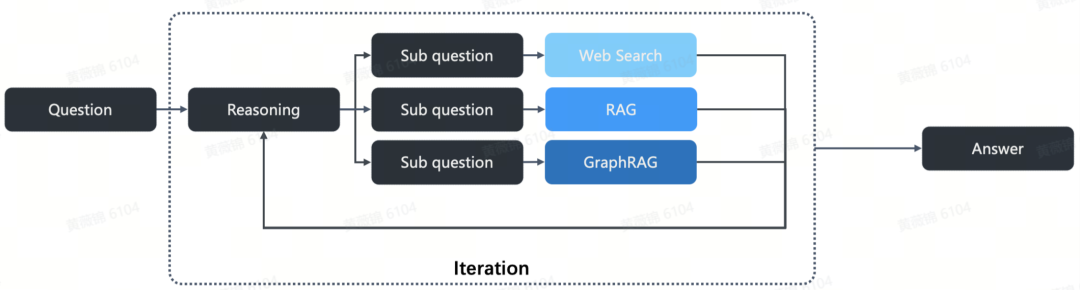
RAGFlow的目标是进一步提升推理能力,它基于RAG架构,通过迭代式推理链生成和子问题的搜索来解锁推理功能。在此过程中,模型会依据用户数据、API调用或Web搜索进行推理,生成高质量答案。尽管如此,RAG本身并未能完全解决推理链质量评估和迭代终止的问题。因此,RAGFlow的实现方法,虽然非常有效,但仍有待进一步发展和完善。
其中的一些技术路线,例如Search o1、PIKE-RAG和Agentic Reasoning,都是试图通过更加精细化的推理链构建和迭代优化来提高推理能力,这些方法虽然有效,但也存在终止机制的挑战。RAG-Gym则通过强化学习解决了推理过程中质量评估的问题,而DeepRAG通过模仿学习辅助推理改进,处理了子任务拆分不合理和决策机制缺失的问题。
RAGFlow结合了多种先进技术,包括Search o1、PIKE-RAG、Agentic Reasoning等,构建了一个通用的推理引擎,致力于为企业提供基于自有数据的推理服务。通过迭代生成推理链、自动化检索外部和内部数据,RAGFlow能够在不同领域(如健康诊断、商业决策等)为企业提供实际价值。
尽管目前RAGFlow与R1连接的效果差异不大,R1的推理过程较长,因此在某些场景中并不适合直接使用R1。此外,RAGFlow与R1的结合并非总是最佳选择,特别是在数据处理时可能会增加延迟。当前RAGFlow的开发重点是提升推理链的生成能力,而等待R1提供推理链API接口,这将进一步解锁LLM的推理能力,推动AI决策的普及和应用。
https://zhuanlan.zhihu.com/p/27605080899
DeepSeek AI Infra(2) – FlashMLA的原理与代码剖析
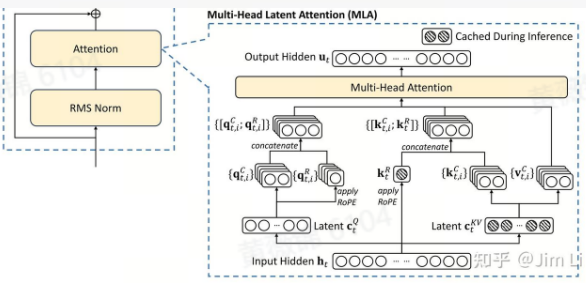
FlashMLA 是专为 NVIDIA Hopper 架构的 GPU 设计的一款高效多层注意力解码内核,优化了变长序列推理。它采用了“先压缩后解压”的低秩联合压缩方法,通过压缩键(K)和值(V)矩阵减少了内存占用,同时保留了原始信息,显著降低了 KV 缓存的需求,减少了约93.3%的内存压力。FlashMLA 对比其他压缩算法,能够在不损失性能的情况下,极大提升计算效率。
FlashMLA 通过对输入序列的压缩和解压处理,将输入的 token 压缩成低维潜在向量,在推理时再通过上投影矩阵还原为键和值。这样,内存需求减少的同时,依然保持了足够的计算精度。此外,旋转位置编码(ROPE)被独立处理,以避免对计算流程的影响。
技术上,FlashMLA 基于低秩联合压缩,将 Q、K、V 数据通过低维嵌入共享,减少了计算时的矩阵乘运算。它还利用 Hopper 架构中的硬件加速功能,如 WGMMA(Warpgroup Matrix Multiply-Accumulate)和 TMA(Tensor Memory Accelerator),提高了吞吐量和内存传输效率。同时,通过 FP8 精度和双缓冲技术,进一步提高了计算性能。
代码层面,FlashMLA 采用了模板元编程优化,能根据编译时参数进行内存布局和计算模式调整,从而减少运行时计算开销。此外,使用了双缓冲技术,在计算和数据加载过程中避免了内存访问等待,提升了效率。共享内存管理方面,通过精确控制内存布局和使用联合体(union)来共享空间,确保了内存占用的最优化。
性能上,FlashMLA 在 NVIDIA Hopper 架构的 GPU 上能够实现每秒处理 3000GB 数据和每秒执行 580 万亿次浮点运算的能力。它能够高效处理变长序列,并通过优化内存访问和计算流程,在保持高效推理性能的同时,降低了内存开销。
https://zhuanlan.zhihu.com/p/27508725949
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43229.html