
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


潜空间第六季活动开始报名!!

资讯
《北京具身智能科技创新与产业培育行动计划(2025-2027年)》
近日,北京市科学技术委员会等部门联合发布了《北京具身智能科技创新与产业培育行动计划(2025-2027年)》,旨在推动具身智能产业发展,打造全球具身智能科技创新策源地和产业增长极。到2027年,北京计划突破不少于100项关键技术,产出不少于10项国际领先的软硬件产品,实现具身智能上下游产业链基本国产化。同时,将建设世界模型仿真、数据采集、中试验证、场景开放测试等新型研究创新平台,支撑不少于100家创新主体开展技术创新,推动具身智能在科研教育、工业商业、个性化服务等三大场景实现不少于100项规模化应用,培育千亿级产业集群。
技术方面,北京将重点攻坚六大核心技术。首先是突破多模态融合感知技术,研究时空同步与校准技术,以及跨模态学习、交互式感知、主动感知、视觉语言-动作多模态统一表征与融合等算法,提升机器人的感知理解能力。其次,研发具身智能“大脑”大模型,构建通用性强的多模态基础大模型,使其具备空间物体感知、环境自主理解、复杂任务规划等能力,实现感认知-决策-控制一体化。第三,提升具身智能“小脑”技能模型能力,推动技术供应方与场景应用方联合开发技能模型,实现机器人技能的持续改进与环境自主适应。第四,提高机器人运动控制性能,研究高动态运动机器人全身运动控制策略,搭建通用机器人运动控制算法框架,实现具身智能“大脑”在异构机器人本体的接入。第五,强化核心零部件技术创新和供给能力,优化精密加工工艺,研发伺服驱动系统、智能一体化关节、通用末端执行器、高精度机械臂和灵巧手系统等关键技术及轻质高强度、柔性材料。最后,研制国产高性能具身智能芯片,前瞻布局高性能云端推理芯片、超低功耗的端侧控制计算芯片、类脑芯片,打造模块化终端通用智能模组,构建全栈国产化软硬件生态。
此外,北京还将加快建设新型研究创新平台,推动“具身智能+”多场景示范应用,并优化具身智能产业生态,包括构建全栈人才梯队、开展高水平开放合作、加强企业梯度培育服务以及打造具身智能产业集聚区等。

https://mp.weixin.qq.com/s/Iq5CYz6gN6iSMpHkLrskrw
世界移动通信大会 MWC2025
MWC作为全球通信行业的重要展会,今年吸引了联想、华为、小米、谷歌、三星等众多科技巨头参展。与以往不同的是,今年的展会更加关注技术的实际应用,而非单纯的技术展示,AI成为各公司展示的重点。
小米在3号馆占据了较大场地,其SU7 Ultra成为焦点,吸引了众多观众。谷歌则在2号馆设置了Android、Google Cloud和Google Pixel三个展台,其中Google Cloud展台展示了自研大模型Gemini,成为吸引观众的重要因素。中国移动则通过“中国功夫”表演吸引观众。然而,尽管AI是展会的热点,但国内备受关注的大语言模型DeepSeek并未在任何展台上出现。这可能是因为参展公司大多直接使用了两个月前CES的展品,而那时DeepSeek尚未引起广泛关注。此外,MWC展商更倾向于展示底层技术和方案,而非像中国公司那样追求第一时间接入最新大模型。
文章还提到了宇树科技的机器狗,它们不仅为大公司展台引流,还在4号馆租了一个小展台。机器狗作为一种“具身”形象,暗示了AI在手机和电脑中应用时对物理存在的需求。联想在展会上展示了代号“flip”的带折叠外屏笔记本电脑,以及“Magic Bay”技术和适配的“Tiko”系列硬件。Magic Bay通过磁吸触点实现外屏与笔记本内屏的联动,可组成移动三屏联动巨屏或大屏加侧面小副屏的显示组合。Tiko Pro则是一个8英寸的小屏,可显示天气、故事信息等小组件功能,释放笔记本屏幕空间。更有趣的是Tiko,它是一个能在圆形屏幕上显示表情的小配件,可以通过语音和输入框与用户互动,类似于蔚来汽车的Nomi。Tiko可能成为未来PC和手机配备的AI助手的具身形象,为用户提供更多情绪价值。

https://mp.weixin.qq.com/s/KwOIttsMamDSr_S5K6tlVg
DeepSeek R1技术成功迁移到多模态领域,全面开源
Visual-RFT(视觉强化微调)项目成功将 DeepSeek-R1 的基于规则奖励的强化学习方法从纯文本大语言模型拓展到视觉语言大模型(LVLM),为视觉语言模型的训练开辟了全新路径。
Visual-RFT 通过为视觉任务(如细分类、目标检测等)设计对应的规则奖励,突破了传统方法在视觉领域的局限性。与传统的视觉指令微调(Visual Instruction Tuning/Supervised Fine-Tuning,SFT)相比,Visual-RFT 具有少样本学习能力和更强的泛化性,尤其在数据量有限的场景下表现出显著优势。在验证过程中,Visual-RFT 在多个视觉感知任务上展现出卓越性能,包括目标检测、开放目标检测、少样本检测与分类、推理定位等。实验结果显示,仅需少量数据,Visual-RFT 就能在这些任务上取得显著提升,且结果明显优于 SFT 方法。
为了验证可验证奖励在视觉多模态领域的作用,Visual-RFT 提出了基于 IoU(交并比)的 verified reward 奖励应用于 detection 和 grounding 任务,以及基于分类正确判断的 cls reward 用于 classification 任务。通过这些奖励机制和强化学习策略(例如 GRPO),Visual-RFT 能够有效更新模型参数,提升模型的视觉理解与推理能力。
实验主要基于视觉语言大模型基座 QWen2-VL 2B/7B 模型进行,测试数据涵盖了通用场景(如 COCO、LVIS)和开放场景(如互联网中收集的卡通人物等)。结果显示,Visual-RFT 在开放目标检测、少样本检测、细粒度分类和推理定位任务上全面超越 SFT 方法,仅需几十条数据即可学会检测特定动漫中的角色形象,验证了其卓越性能和鲁棒性。
目前,Visual-RFT 项目已全面开源,包含训练、评测代码和数据,为多模态模型、强化学习、视觉语言理解等领域的研究者提供了新的探索方向。

https://mp.weixin.qq.com/s/VCSUQXV7yv9MdIWQlxh7dQ
推特
Maxime Labonne教授如何使用 GRPO 微调 LLMs
我与 Huggingface 和 Ben Burtenshaw,教授如何使用 GRPO 微调 LLMs。
在这个 notebook 中,我们对一个小型的 SmolLM-135M 模型进行了微调,使用的是我筛选后的 smoltldr 数据集。借助我们的奖励函数,我们鼓励模型生成大约 50 个字符的摘要(“TL;DR”)。
有趣的是,这个 135M 规模的模型仅用 2000 条样本就能学会这种行为!最终结果的质量有所不同,但调整超参数的过程非常有趣,也帮助我们更直观地理解这些小型模型在 GRPO 机制下的表现。
这次合作非常有趣,希望你会喜欢这门课程!

https://x.com/maximelabonne/status/1896594006324244680
Perplexity与Deutsche Telekom携手推出Perplexity Assistant,作为 AI 手机原生功能
我们很自豪能与 Deutsche Telekom 合作,将 Perplexity Assistant 作为其全新 AI 手机的原生功能。

SmolVLM-2:最新的模型,可完全在设备端实时运行,为医疗保健应用提供坚实的基础
很高兴发布 SmolVLM-2,我们最新的模型,可完全在设备端实时运行,为医疗保健应用提供坚实的基础。
通过适当的领域特定训练,小型模型可以实现 2D(心电图 ECGs、胸片 CXRs)甚至 3D(CT、MRI)数据的离线推理,同时在设计上符合 HIPAA 合规要求。
今年,VLMs 取得了巨大进展,我们很高兴分享我们的最新 SoTA 解决方案。

https://x.com/cyrilzakka/status/1896631022747627744
Stability和Arm合作:将生成式音频引入移动设备,使其能够直接在设备端生成高质量音效和音频样本
📲 音频生成首次实现设备端离线运行!
我们与 @Arm 合作,将生成式音频引入移动设备,使其能够直接在设备端生成高质量音效和音频样本,无需互联网连接!
以下是我们的实现方式 ⬇️

https://x.com/StabilityAI/status/1896549967998923096
产品
Teamble AI:提取质量提升 10 倍的反馈
Teamble AI 有助于全年提供和获取质量提升 10 倍的员工反馈。更好的反馈→更好的学习→更高的绩效!并且可在 Slack 和微软 Teams 上无缝使用!
Teamble 2.0,每个员工都有一个 AI 助手支持,它:
-
接受过反馈科学和最佳实践的培训
-
基于成长心态、彻底坦率和基于优势的发展理念构建
-
由先进的推理模型驱动,可帮助你实时给出高质量的反馈
把它想象成你的个人反馈教练 —— 触手可及,随时在线,助力你成长。
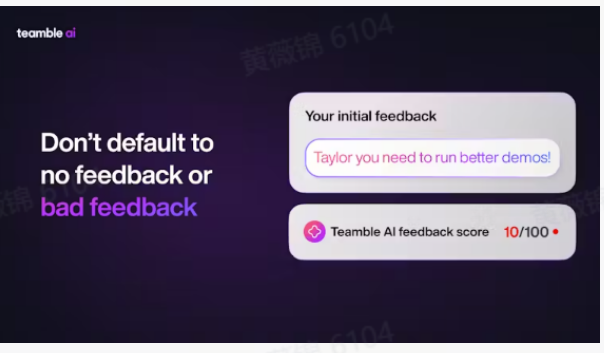
https://teamble.com/
投融资
Anthropic完成35亿美元融资
AI初创公司Anthropic于2025年3月3日宣布完成35亿美元的融资,此轮融资由Lightspeed Venture Partners主导,其他参与者包括Bessemer Venture Partners、Cisco Investments、D1 Capital Partners、Fidelity Management & Research Company、General Catalyst、Jane Street、Menlo Ventures以及Salesforce Ventures。此轮融资使公司估值达到615亿美元,Anthropic至今总共融资达到了182亿美元。
公司表示,融资将用于推动下一代AI系统的开发,扩大计算能力,深化机制可解释性与对齐研究,并加速国际扩展。Anthropic的目标是打造能够作为真正协作者的AI系统,协助团队处理复杂项目,跨领域综合信息,并帮助组织实现更大的影响力。
近期,Anthropic推出了其最新的旗舰AI模型Claude 3.7 Sonnet,这是一款“混合推理”模型,能够在回答问题前更加仔细地考虑查询内容。此举是Anthropic简化用户体验的一部分,旨在减少用户在使用AI产品时面临的选择困扰,理想状态下,单一模型能够完成所有任务。
公司业务不断增长,据报道,其2024年年度营收接近10亿美元,2025年迄今已增长30%。然而,随着公司加大AI系统开发投入,预计2025年将烧掉30亿美元。为了增强盈利能力,Anthropic调整了部分战略,推出了新的工具和订阅层级,如计算机“代理”、桌面客户端和移动应用等。公司还在欧洲开设了办公室,并招聘了一些知名高管,包括Instagram联合创始人Mike Krieger、OpenAI联合创始人Durk Kingma以及前OpenAI安全研究员Jan Leike。
此外,Anthropic与亚马逊的合作关系也日益紧密。亚马逊不仅成为其主要投资者,还于2024年11月向Anthropic投资了40亿美元,并与公司合作优化自家AI芯片Trainium以支持模型训练工作负载。两家公司还共同打造了升级版的Alexa虚拟助手Alexa+,Anthropic的模型为Alexa+提供了部分支持。
Anthropic由前OpenAI副总裁Dario Amodei于2021年共同创办,Amodei此前因与OpenAI在发展方向上的分歧而离职,并带领一批前OpenAI员工一起成立了Anthropic。该公司常常将自己与OpenAI区别开来,宣称其更注重AI安全性。

https://techcrunch.com/2025/03/03/anthropic-raises-3-5b-to-fuel-its-ai-ambitions/
— END —
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43217.html