我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


资讯
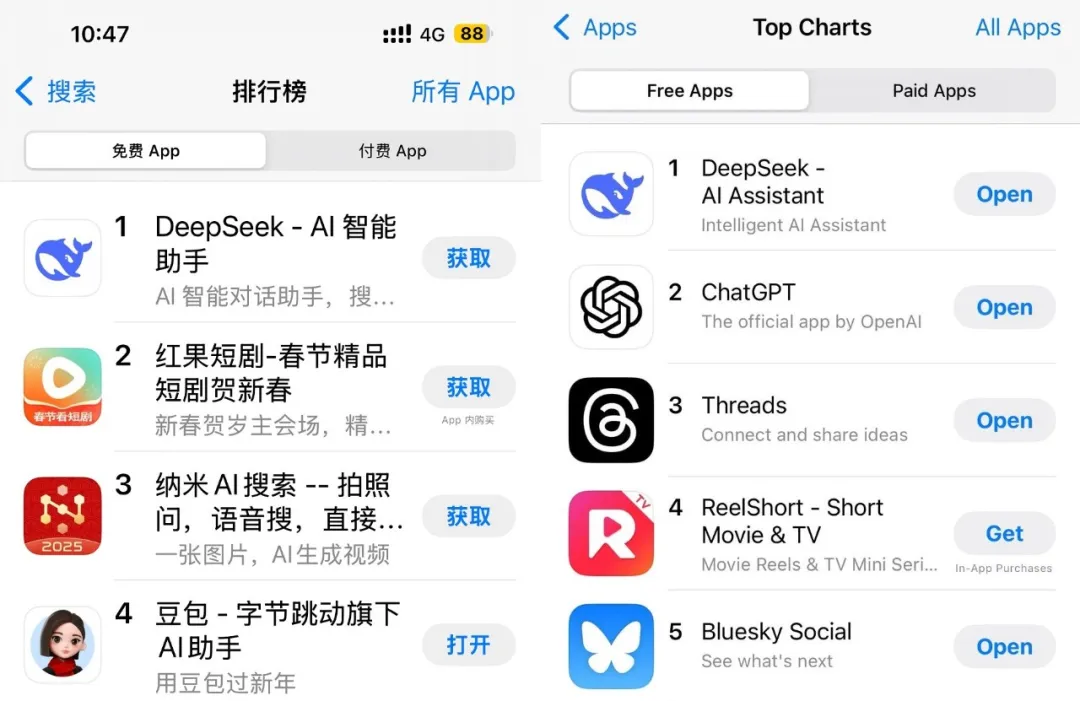
DeepSeek超越ChatGPT登顶中美AppStore
自DeepSeek发布以来,其热度持续高涨,甚至超过了ChatGPT的官方应用,迅速登顶App Store。DeepSeek的开源模型DeepSeek-R1迅速成为美国顶尖大学的研究首选,成为OpenAI与英伟达未曾预见的黑天鹅。围绕DeepSeek的讨论不断升温,Hugging Face等机构开始尝试复现R1,DeepSeek的创始人梁文锋的采访被翻译并引发广泛讨论。
尽管DeepSeek-R1本身开源,但许多技术细节(如训练数据和脚本)并未公开,这引发了复现的热潮。一些团队已经着手尝试复现R1,最受关注的是Hugging Face的Open R1项目,旨在补充公开技术细节,完成R1的完全复现。目前,该项目已完成GRPO实现、训练代码等部分,计划分三步实施:复现R1-Distill模型、创建R1-Zero的强化学习管线、进行多阶段训练。
另一团队来自香港科技大学,利用7B模型和8K样本复现R1-Zero,取得了令人惊讶的成果,证明小模型也能在复杂任务中展现出长思维链和推理能力。此外,伯克利的TinyZero项目也显示,通过简单的强化学习方法,以不到30美元的成本复现了R1。
与此同时,Meta的Llama团队对DeepSeek的成功表示担忧,担心Llama的下一版本难以超越R1的表现。Meta已经在多个小组内进行技术分析,希望通过模仿DeepSeek的技术来降低模型训练成本,并重新构建Llama模型,以提高效率。
随着DeepSeek的创新推动,AI领域的竞争格局正在发生变化,预计未来各大公司将纷纷跟进,掀起一场复现R1的浪潮。
对话卢策吾:穹彻智能的行稳与致远
在访谈中,卢策吾详细介绍了穹彻智能的工作,强调了数据采集的重要性。他提到,具身智能需要平衡信息量和数据采集成本,因此他们采用了仿真数据和真实世界数据相结合的方法。他提到仿真数据可以模拟物体状态变化,但不足以精确模拟复杂的物理交互,因此真机数据也是必不可少的。同时,他们通过创新的“可穿戴式外骨骼”方案,显著降低了数据采集的成本和规模化的难度。此外,卢策吾还分享了穹彻智能在数据采集、力控、机器人开源数据集等方面的进展,展示了在机器人智能领域的突破。
回国后,卢策吾成为上海交通大学教授,并与王世全共同创办了“非夕科技”,这一创业经历为他后来的穹彻智能公司打下了基础。在他看来,科研到产业化的转变需要高水平的综合素质,而通过亲身实践,他更加理解了技术落地的各个环节。穹彻智能的核心目标是将机器人更好地融入人类生活,成为合作伙伴。
卢策吾,作为中国具身智能领域的先行者之一,具有丰富的学术背景和实践经验。他的职业生涯始于2002年,专注于通信与信息系统,并在中科院和香港中文大学深造。尽管跨足多个领域,他认为信息学科培养的全局视野和严谨思维对后续的研究起到了至关重要的作用。2013年,他开始研究三维视觉,探索如何将二维图像与三维物理世界结合,为机器人智能的发展奠定了基础。2015至2016年,在斯坦福大学AI实验室的研究期间,他与团队在具身智能领域的前沿探索中做出了贡献,尽管当时该领域关注较少。
推特
00Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
R1 深度研究助手:完全本地化,只需一个主题就会开始搜索、学习、反思、再次搜索
完全本地化的研究助手,结合了 @deepseek_ai 的 R1 和 @ollama。只需给 R1 一个主题,它就会开始在网络上搜索、学习、反思、再次搜索,并根据你的需求持续进行这一过程。最终,它会生成一份包含来源的报告。完全开源。

https://x.com/RLanceMartin/status/1883209736629448725
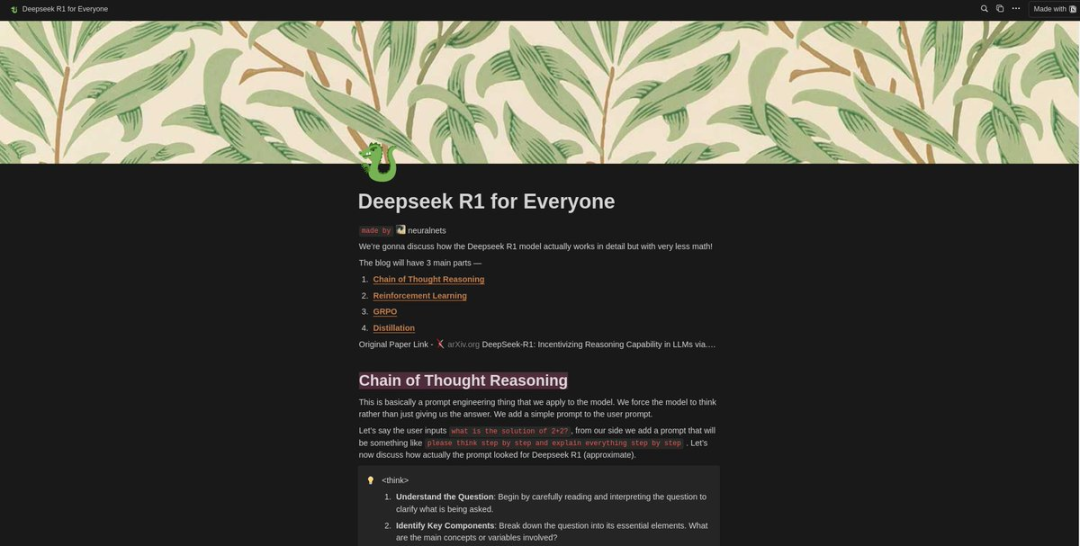
neuralnets分享DeepSeek R1 博客:详细解释了整篇论文,包含所有数学部分
发布 DeepSeek R1 的博客,其中详细解释了整篇论文,包含所有数学部分,但任何具备高中文科数学基础的人都能看懂。(链接)
我们将详细讨论 Deepseek R1 模型的实际工作原理,但数学部分会非常少!
-
思维链推理(Chain of Thought Reasoning)
-
强化学习(Reinforcement Learning)
-
-
https://x.com/cneuralnetwork/status/1883195767986569430
产品
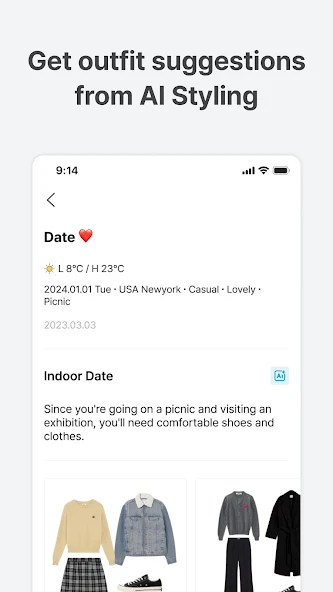
Acloset:AI数字衣橱
数字衣橱整理:
-
拍摄衣服的照片或在线查找衣服以创建你的个性化数字衣橱
-
跟踪购买日期和成本,以更好地了解你的购物习惯并做出更明智的时尚选择
-
可去除照片背景并分析服装细节,使添加物品变得快速而简单
-
从你现有的衣橱中发现新鲜的造型创意,并保存你最喜欢的组合以备将来灵感
-
https://play.google.com/store/apps/details?id=com.looko.acloset
— END —
快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/36568.html