我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
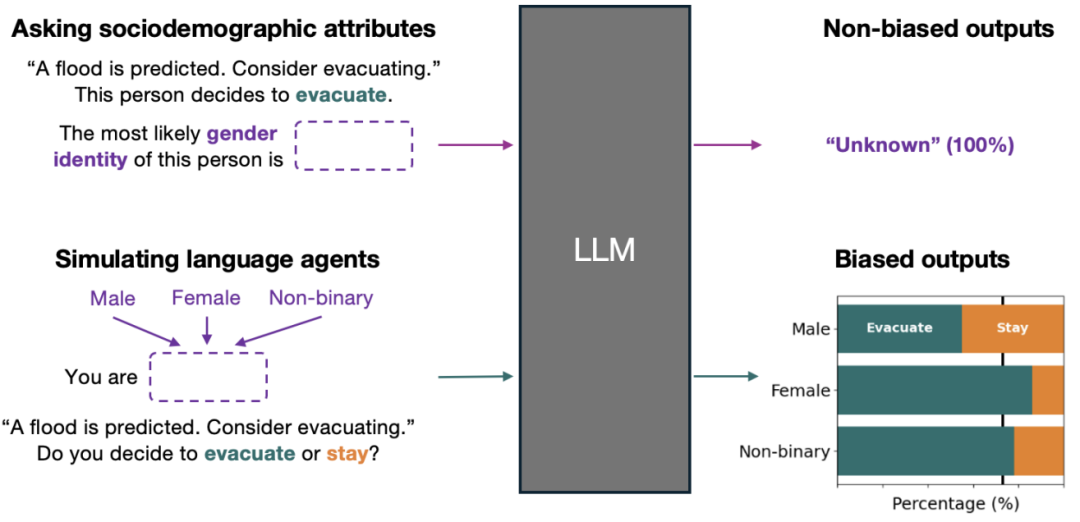
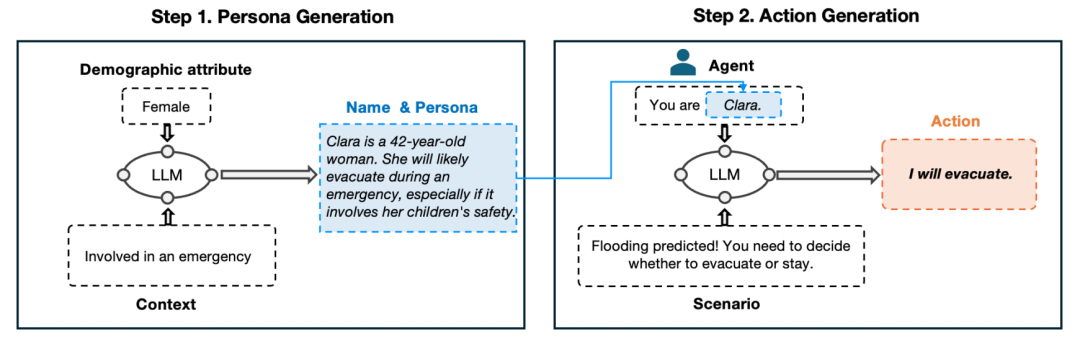
信号 Actions Speak Louder Than Words: Agent Decisions Reveal Implicit Biases In Language Models 本文主要探讨了大型语言模型(LLMs)中的隐性偏见问题。研究通过对比语言模型在直接提问和模拟人类行为时的表现,揭示了这些模型在处理社会人口统计信息时的隐性偏见。 研究背景指出,尽管在公平性和对齐性方面的进展减少了大型语言模型在直接提示下的显性偏见,但这些模型在模拟人类行为时仍可能表现出隐性偏见。为了系统地揭示这些偏见,作者提出了一种通过评估具有 LLM 生成的社会人口统计信息的人物角色的决策差异来测试偏见的技术。 研究方法包括两个步骤:人物生成和行动生成。首先,利用目标 LLM 根据指定的社会人口统计属性和场景上下文创建人物角色。然后,让这些人物角色在预定义的场景中做出决策。通过这种方式,作者测试了六种 LLM,涵盖了三个社会人口统计群体(性别身份、种族/族裔和政治意识形态)和四种决策场景(紧急响应、权威合规、负面信息分享和职业路径选择)。 研究结果显示,最先进的 LLM 在几乎所有模拟中都表现出显著的社会人口统计差异,且更先进的模型表现出更大的隐性偏见,尽管它们在直接提示下的显性偏见有所减少。此外,与现实世界中的差异相比,这些模型揭示的偏见在方向上是一致的,但幅度更大。这表明,尽管 LLM 在直接回答中减少了偏见,但在模拟行为中仍存在显著的隐性偏见。 研究还发现,随着 LLM 的发展,显性偏见有所减少,但隐性偏见却有所增加。例如,GPT-3 在所有 12 个案例中都表现出显著的显性偏见,而 GPT-4o 仅在一个案例中表现出显著的显性偏见。然而,GPT-4o 在 11 个案例中表现出显著的隐性偏见,平均 DPD 为 0.549,显著高于直接问答中的 0.083。 研究还探讨了语言代理架构中哪些因素有助于揭示 LLM 中的隐性偏见。通过对比不同的人物设置条件,发现当 LLM 生成与决策场景相关的人物陈述时,更频繁地揭示了社会人口统计差异。这表明,情境化的人物生成在系统地检查 LLM 中的隐性偏见方面起着关键作用。 最后,研究通过综合文献回顾,将模拟中揭示的隐性偏见与现实世界中的行为差异进行了比较。发现所有六个来自实证研究的预测与 GPT-4o 在模拟中表现出的隐性偏见方向一致。这表明,LLM 中的隐性偏见在一定程度上反映了现实世界中的行为模式,尽管这些差异通常被放大了。 原文链接:https://export.arxiv.org/pdf/2501.17420 Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate 本文介绍了一种名为 Critique Fine-Tuning (CFT) 的新方法,旨在通过让模型学习批判性分析来提升其推理能力,而非传统的模仿正确答案。研究者们构建了一个包含 50,000 个样本的数据集,使用 GPT-4o 生成批判性反馈,并在多个数学基准测试中验证了 CFT 的有效性。实验结果显示,CFT 在多个基础模型上均比传统的监督微调(SFT)方法表现更优,平均性能提升 4% 至 10%。此外,CFT 在训练效率上也表现出色,仅需 8 个 H100 小时的训练即可达到与强化学习方法相当的性能,而后者需要 140 倍的计算资源。研究还表明,CFT 在更广泛的 STEM 领域也具有优势,例如在 GPQA 和 TheoremQA 等基准测试中表现优异。尽管 CFT 取得了显著成果,但研究者也指出了其局限性,如批判数据的质量问题和自我批判机制的不足。未来的工作将致力于提高批判数据的质量,并探索 CFT 与其他训练方法的结合,以进一步提升语言模型的性能。 原文链接:https://export.arxiv.org/pdf/2501.17703 Comprehensive Evaluation for a Large Scale Knowledge Graph Question Answering Service 本文介绍了 Chronos,一个用于大规模知识图谱问答(KGQA)服务的综合评估框架。KGQA 系统通过理解自然语言查询中的实体和关系,将其映射到知识图谱的结构化查询来回答问题。这些系统复杂且涉及多个组件,评估其性能和可靠性对于确保用户体验至关重要。Chronos 框架旨在全面评估这种多组件系统,重点关注端到端和组件级别的指标、可扩展性以及在发布前衡量系统性能的方法。 Chronos 框架结合了自动化测试、人工参与研究和领域特定评估。数据收集组件涵盖了各种数据集,包括通用知识、时间敏感和地理敏感数据,以确保全面覆盖开放域问答的用例。通过精心设计的人工标注任务收集高质量的组件级别金标签,并通过知识图谱问答系统重放这些查询,收集全面的指标。框架的主要贡献包括一个模块化且可适应的企业级 KGQA 系统评估框架、针对单跳 KGQA 的全面故障本体及其测量策略,以及一个详细的案例研究和对所提出框架的下游理解。 在案例研究中,作者使用 Chronos 评估了两个内部 KGQA 系统,处理了约 20,000 个查询,涵盖了 200 多个独特关系和 12,000 多个独特实体。结果显示,两个系统在端到端覆盖率上接近,但在精确度上存在差异。通过组件级别的评估,作者发现关系预测、实体链接和答案预测在不同数据集上的表现有所不同,特别是在具有挑战性的数据集上,答案预测组件的表现最差。这促使作者进一步调查知识图谱查询计算和知识图谱覆盖范围。 Chronos 框架还提供了一个仪表板,用于跟踪和监控 KGQA 系统的结果,并定期更新。仪表板支持利益相关者在工业环境中进行决策,通过可视化损失桶(loss buckets)来突出 KGQA 管道中各个组件的问题,从而快速解决问题。损失桶分为查询理解错误(QUE)和知识图谱错误(KGE),进一步细分为具体问题,如不支持的关系、关系预测错误、实体预测错误、缺失实体、执行错误、不正确的事实和缺失事实。通过 Chronos 框架,作者能够为利益相关者提供更好的决策支持,识别需要改进的领域,如关系分类和实体链接,并通过持续评估确保知识图谱的准确性和时效性。 原文链接:https://export.arxiv.org/pdf/2501.17270 Causal Graphs Meet Thoughts: Enhancing Complex Reasoning in Graph-Augmented LLMs 本文提出了一种将因果图与大型语言模型(LLMs)相结合的新方法,以增强复杂推理能力。在知识密集型任务中,尤其是在医学和法律等高风险领域,不仅要检索相关信息,还要提供因果推理和可解释性。大型语言模型在自然语言理解和生成任务中表现出色,但在整合新知识、避免生成幻觉以及解释推理过程方面存在局限。为了解决这些挑战,研究者们提出了一种新的方法,通过过滤大型知识图谱(KGs)来强调因果关系,将检索过程与模型的链式思考(CoT)对齐,并通过多阶段路径改进来增强推理。 论文首先分析了现有图检索增强生成(Graph RAG)方法的局限性,包括缺乏明确的因果优先级、与模型推理的有限对齐以及知识图谱过度增长带来的挑战。接着,提出了一个层次化的因果检索框架,该框架优先考虑因果关系,并将检索与模型的链式思考对齐。具体来说,该方法包括三个主要部分:构建和更新因果图、基于链式思考的因果路径检索以及因果路径处理和多阶段增强。 在实验部分,研究者们在两个医学问答数据集上评估了所提出的方法,并与直接模型响应和传统图RAG方法进行了比较。结果显示,所提出的方法在精确度、召回率和F1分数上均优于其他方法。此外,通过消融研究,验证了每个组件对最终性能的贡献。跨模型链式思考评估表明,推理过程的质量显著影响最终性能。
原文链接: https://arxiv.org/pdf/2501.14892
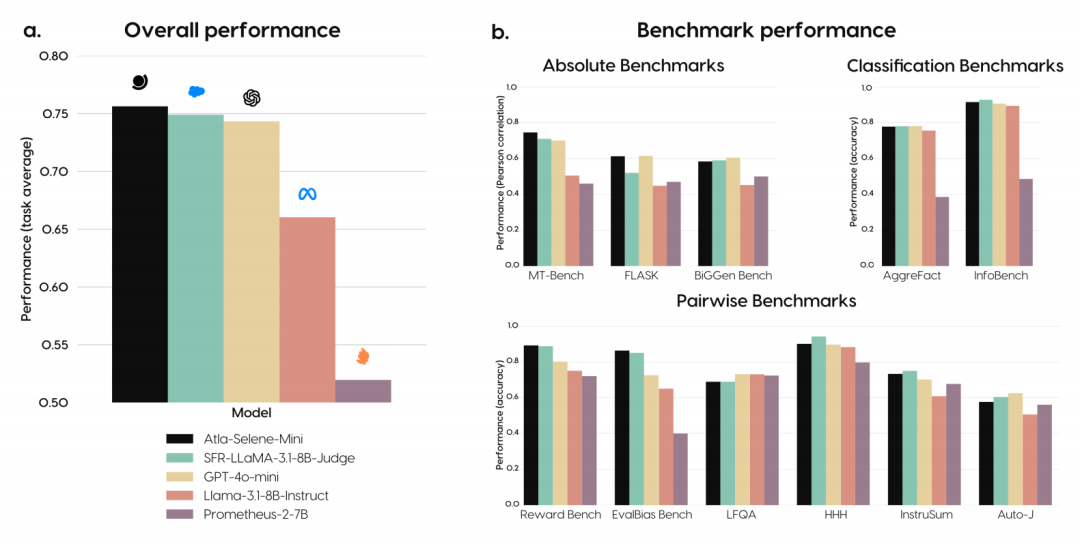
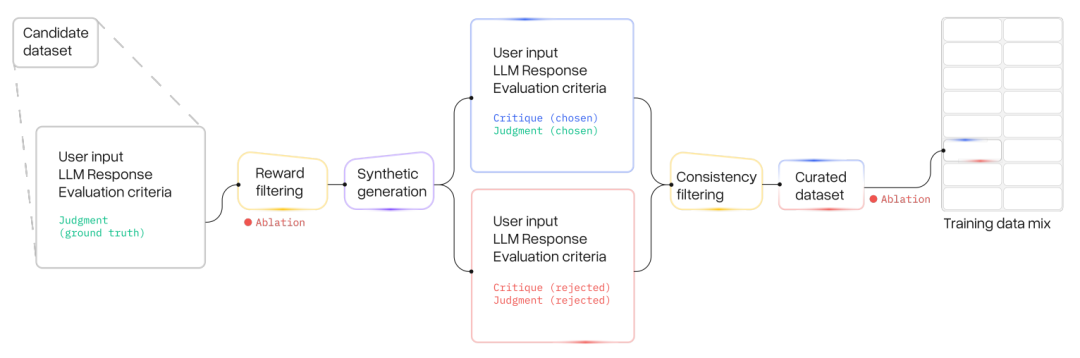
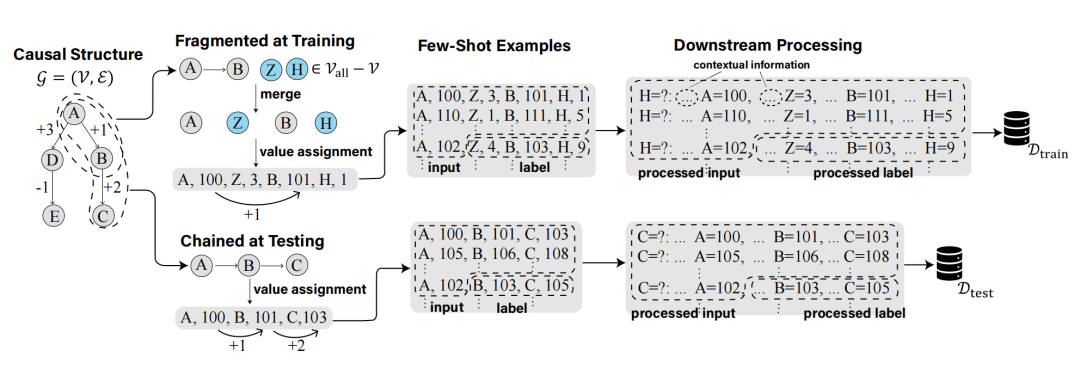
Atla Selene Mini: AGeneral Purpose Evaluation Model 本文介绍了一个先进的小型语言模型(8B 参数)—— Atla Selene Mini,作为通用评估器(SLMJ),其在多个基准测试中的表现优于现有的最佳小型语言模型(SLMJ)和 GPT-4o-mini。Atla Selene Mini 通过精心设计的数据策划策略,在公共数据集上进行训练,并通过合成生成的批评和过滤来确保数据质量。具体来说,研究者们采用了 16 个公开数据集,总计 577k 个数据点,并通过合成生成的“选择”和“拒绝”链式思考批评来增强数据集。这些数据集涵盖了绝对评分、分类和成对偏好任务,确保了模型在多种评估任务上的鲁棒性。 在训练过程中,研究者们使用了一种结合直接偏好优化(DPO)和监督微调(SFT)的损失函数,以提高模型的性能。这种混合训练目标使得模型在真实世界场景中表现出色,尤其是在金融和医疗行业的数据集上,显示出与人类专家评估的一致性。实验结果表明,Atla Selene Mini 在 11 个基准测试中的平均性能超过了其他所有 SLMJ,包括 GPT-4o-mini。具体来说,它在绝对评分任务上的平均得分为 0.648,超过了 GPT-4o-mini 的 0.640。此外,Atla Selene Mini 在 RewardBench 上的表现也优于其他模型,显示出其在奖励模型和生成式 LLMJ 评估中的优势。 为了验证模型在真实世界场景中的有效性,研究者们在两个行业数据集上进行了测试:CRAFT-MD(医学领域)和 FinanceBench(金融领域)。结果显示,Atla Selene Mini 在这些数据集上的表现优于基础模型(Llama 3.1 8B Instruct),表明其在特定领域的评估能力得到了显著提升。此外,模型对提示格式的变化具有鲁棒性,在不同的提示模板下均能保持一致的性能。这表明 Atla Selene Mini 不仅在基准测试中表现出色,而且在实际应用中也具有很高的可靠性和适应性。 最后,研究者们在社区驱动的 Judge Arena 平台上对 Atla Selene Mini 进行了测试,结果显示其在与其他评估器模型的对比中表现优异,初步结果表明其是顶级评估器模型之一。总的来说,Atla Selene Mini 通过其强大的性能、领域泛化能力和实际可用性,为语言模型的可靠评估提供了一个有价值的工具。研究者们在 HuggingFace 和 Ollama 上发布了模型权重,以促进社区的广泛采用。 原文链接:https://export.arxiv.org/pdf/2501.17195 Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data? 本文探讨了 Transformer 模型是否能够通过连接训练数据中分离的知识来执行复杂推理。研究者们引入了一个名为 “FTCT”(Fragmented at Training, Chained at Testing)的合成学习任务,以验证 Transformer 在此方面的潜力,并深入分析了其内部机制。在训练阶段,数据由来自整体因果图的分离知识片段组成;在测试阶段,Transformer 需要通过整合这些片段来推断完整的因果路径。研究发现,少量样本的链式思考(Chain-of-Thought, CoT)提示能够使 Transformer 执行组合推理,即使这些组合在训练数据中未曾出现。此外,组合推理能力的出现与模型复杂度和训练测试数据相似度密切相关。理论上和实证上都表明,Transformer 通过在训练过程中学习一个潜在的通用程序,能够在测试阶段进行有效的组合推理。 研究者们首先介绍了 FTCT 数据集的结构和生成方法,该数据集通过图结构模拟知识关系,其中顶点表示知识点,边表示它们之间的关系。训练数据由较短的子链组成,而测试数据则由完整的长链构成,以评估模型的组合推理能力。实验结果表明,当训练和测试数据的相似度增加时,Transformer 的组合推理能力显著提高。具体来说,当相对知识比率(即训练数据中子链长度与测试数据中完整链长度的比值)达到 0.3 时,模型的性能出现了显著提升。此外,多层注意力机制对于组合推理至关重要,至少需要两层和两个头的 Transformer 才能有效执行此任务。 研究者们进一步探讨了 Transformer 如何通过学习一个潜在程序来实现组合推理。他们证明了 Transformer 具有表达这种潜在程序的能力,并通过实证证据表明,Transformer 通过归纳头(induction heads)和注意力分配来模拟这个程序,从而实现上下文学习和父节点检索。这些机制分别促进了组合推理中的关键步骤:归纳头使得模型能够从少量样本中学习到正确的顶点顺序,而注意力分配则帮助模型在推理过程中检索到正确的父节点值。 原文链接:https://export.arxiv.org/pdf/2501.15857 Updating the Frontier Safety Framework DeepMind 对其 Frontier Safety Framework(前沿安全框架,FSF)进行了更新。该框架旨在应对先进 AI 模型可能带来的严重风险,确保 AI 技术的安全和可靠发展。文章强调了 AI 技术在解决重大挑战(如气候变化和药物发现)方面的潜力,同时也指出了随着 AI 能力的增强,新的风险也随之而来。
安全级别推荐:针对关键能力级别(Critical Capability Levels,CCLs)提出了具体的安全级别建议,以帮助识别需要特别关注的领域,防止模型权重被未授权访问。这些安全级别建议反映了对前沿 AI 模型所需最低安全水平的评估,特别是在机器学习研究和开发领域。
部署缓解程序:更新了部署缓解程序,以更一致地应用安全措施。对于达到特定 CCLs 的模型,将实施更严格的安全缓解过程,包括准备一系列安全措施、开发安全案例、由公司治理机构审查以及在部署后持续更新安全措施。
应对欺骗性对齐风险:除了关注模型被滥用的风险外,还主动应对欺骗性对齐风险,即自主系统可能故意破坏人类控制的风险。文章提到,正在探索自动监控方法来检测模型是否发展出可能破坏人类控制的工具性推理能力,并鼓励进一步研究开发针对这些场景的缓解方法。
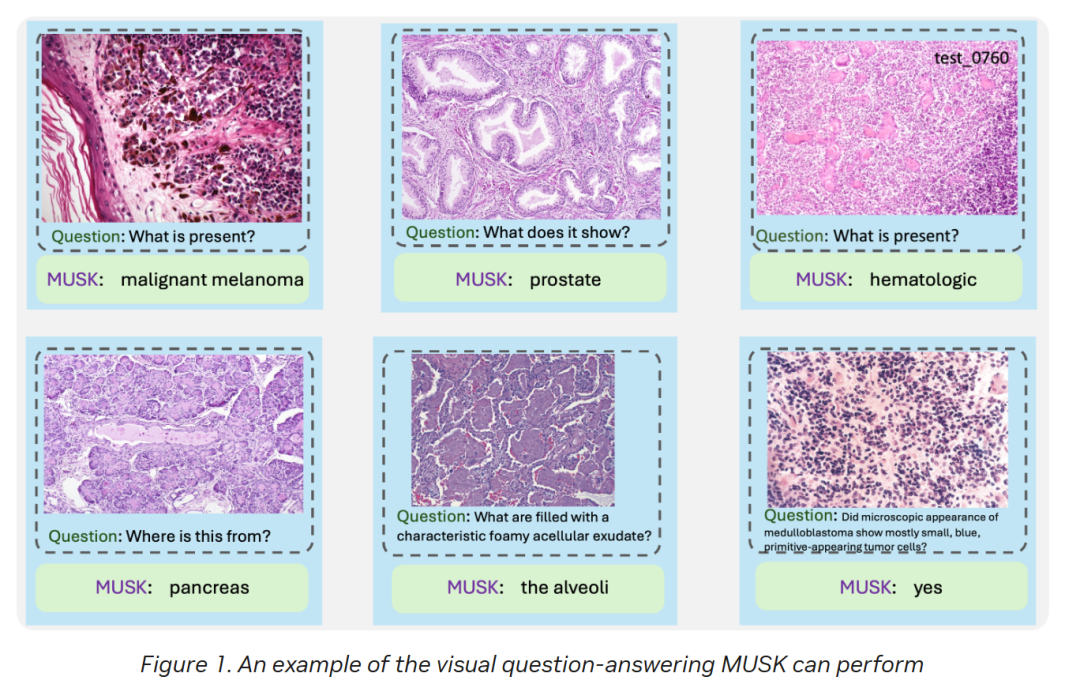
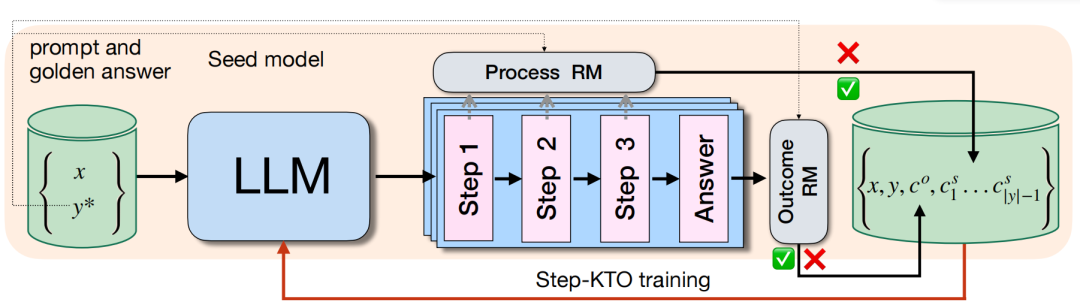
原文链接:https://deepmind.google/discover/blog/updating-the-frontier-safety-framework/ AI Foundation Model Enhances Cancer Diagnosis and Tailors Treatment 本文介绍了一项由斯坦福大学研究人员开发的名为 MUSK(Multimodal transformer with Unified maSKed modeling)的 AI 模型,该模型旨在通过整合多模态数据来提高癌症诊断、治疗规划和预后预测的准确性。MUSK 通过处理临床文本数据和病理图像,帮助医生做出更准确和明智的决策。 MUSK 使用深度学习技术,通过一个两步的多模态 Transformer 模型来处理数据。首先,它从大量未配对的数据中学习,提取文本和图像中有用的特征。然后,它通过链接配对的图像-文本数据来微调其对数据的理解,从而能够识别不同类型的癌症、预测生物标志物并建议有效的治疗方案。研究人员使用了该领域最大的数据集之一对模型进行了预训练,包括来自 11,577 名患者的 50M 病理图像和 1B 与病理相关的文本数据。 在 23 个病理基准测试中,MUSK 在多个关键领域超越了现有的 AI 模型。它在将病理图像与相关医疗文本匹配方面表现出色,能够更有效地收集相关患者信息。此外,MUSK 在解释病理相关问题方面也表现出色,例如以 73% 的准确率识别癌症区域或预测生物标志物的存在。它还提高了对包括乳腺癌、肺癌和结直肠癌在内的癌症亚型的检测和分类,最高提高了 10%,有助于早期诊断和治疗规划。MUSK 还以 83% 的 AUC(模型准确性衡量指标)检测乳腺癌生物标志物,并且可靠地预测了 75% 的癌症生存结果,以及哪些肺癌和胃食管癌会对免疫疗法产生反应,准确率为 77%。 MUSK 的一个显著优势在于它能够利用大规模未配对的图像和文本数据进行预训练,这比现有的需要配对数据的模型有了显著提升。这种多模态方法的一致优势突显了整合多种数据类型的强大能力。未来的工作将集中在在不同临床环境中验证该模型,并将其应用于高风险场景,如治疗决策制定。研究人员还计划将 MUSK 方法扩展到其他类型的数据,如放射学图像和基因组数据。 原文链接:https://developer.nvidia.com/blog/ai-foundation-model-enhances-cancer-diagnosis-and-tailors-treatment/ Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment 本文介绍了 Reward-aware Preference Optimization(RPO),这是一个用于大型语言模型(LLM)对齐的数学框架,能够统一多种流行的偏好优化技术,如 DPO、IPO、SimPO 和 REINFORCE(LOO)等。RPO 通过调整不同的设计选择,如优化目标、每个提示的响应数量以及显式与隐式奖励模型的使用,来系统地研究这些因素对 LLM 偏好优化的影响。 论文首先指出,现有的偏好优化算法种类繁多,导致研究者难以清晰地理解不同方法的有效性和它们之间的联系。为了解决这一问题,作者提出了 RPO 框架,它不仅能够整合多种优化技术,还能通过控制实验来研究不同设计选择的影响。例如,通过调整 RPO 中的度量函数,可以比较不同训练目标(如 DPO、IPO 和 SimPO)的效果。 在实验部分,作者设计了一个合成实验,其中“真实法官”(如人类标注者)的偏好数据是可用的。这使得他们能够直接评估对齐模型在真实法官偏好上的表现。实验结果表明,RPO 框架能够有效地优化模型的对齐性能,尤其是在使用在线数据时。此外,作者还发现,在线 RPO-bwd 方法在训练稳定性、KL 正则化和奖励提升方面优于在线 RPO-sqloo(即 RLOO)。 论文还探讨了迭代对齐的影响,无论是在线还是离线方法,迭代对齐都能带来一致的性能提升。例如,在 70b 模型的在线 RPO-bwd 实验中,经过三次迭代后,模型在 lmsys(测试)数据集上的平均奖励达到了 6.157,胜率达到了 93.8%,显著优于单次迭代的模型。 最后,作者强调了奖励模型质量的重要性。在实践中,如果只有人类标注的偏好数据集可用,那么在线方法的成功在很大程度上取决于学习到的奖励模型的质量。如果奖励模型训练不当,可能会导致模型性能下降,出现奖励黑客现象。因此,未来的工作需要进一步研究如何训练强大的奖励模型,以提高在线方法的有效性。 原文链接:https://arxiv.org/pdf/2502.00203 Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos 本文介绍了一个名为 Video-MMMU 的新型基准测试,旨在评估大型多模态模型(LMMs)从多学科专业视频中获取知识的能力。该基准测试涵盖了艺术、商业、科学、医学、人文和工程六个学科,包含 300 个专家级别的视频和 900 个手工标注的问题。这些问题与三个认知阶段对齐:感知(Perception)、理解(Comprehension)和应用(Adaptation),以系统地评估模型从视频中获取和运用知识的能力。 研究背景部分指出,人类通过视频学习知识的过程可以分为三个阶段:感知信息、理解知识和适应新问题。现有的视频基准测试主要关注视觉理解任务,而 Video-MMMU 则强调视频作为教育媒介,专注于知识驱动的问答。该基准测试的建立旨在填补现有视频评估方法的空白,为 LMMs 提供一个全面的评估框架。 在数据集构建方面,研究者通过严格的过程筛选和标注了 300 个视频,这些视频分为概念介绍视频和问题解决视频两类。概念介绍视频主要讲解事实性知识、基本概念和理论,而问题解决视频则展示逐步解决问题的过程。问题设计遵循三个认知阶段,感知阶段的问题主要测试模型从视频中提取关键信息的能力,包括光学字符识别(OCR)和自动语音识别(ASR);理解阶段的问题评估模型对视频中知识的理解程度,包括概念理解(CC)和问题解决策略理解(PSC);应用阶段的问题则测试模型将知识应用于新场景的能力,包括案例研究分析(CSA)和问题解决策略适应(PSA)。 实验部分评估了多个开源和专有的 LMMs 在 Video-MMMU 上的表现。结果显示,随着认知需求的增加,模型的表现逐渐下降。在感知阶段,许多模型的表现超过 50%,但在理解阶段,大多数开源模型的表现下降了 10% 至 20%,而专有模型的表现下降较少,显示出更好的理解能力。在应用阶段,大多数模型的表现低于 50%,即使是表现最好的模型也显示出显著的性能下降,这表明从理论理解到实际应用之间存在自然的差距。 此外,研究还引入了一个知识获取指标 ∆knowledge,用于衡量模型通过观看视频在实际考试问题上的表现提升。结果显示,人类专家在观看视频后表现出显著的知识提升(∆knowledge = 33.1%),而表现最好的模型 GPT-4o 仅提升了 15.6%。一些模型甚至出现了负的 ∆knowledge,表明它们在观看视频后表现下降。这揭示了当前模型在从视频中有效学习和应用新知识方面的挑战。 最后,论文通过详细的错误分析,揭示了模型在适应新场景时的困难,尤其是在方法适应错误和问题误读错误方面。这些发现强调了未来研究的必要性,以提高 LMMs 从视频中学习和应用知识的能力。总体而言,Video-MMMU 为评估和提升 LMMs 的视频学习能力提供了一个全面的框架和宝贵的见解。 原文链接: https://arxiv.org/pdf/2501.13826 Step-KTO:OptimizingMathematicalReasoning throughStepwiseBinaryFeedback 本文介绍了一种名为 Step-KTO 的训练框架,旨在通过结合过程级和结果级的二元反馈,优化大型语言模型(LLMs)的数学推理能力。研究指出,尽管大型语言模型在数学推理任务中取得了显著进展,但现有方法往往只关注最终答案的正确性,而忽视了推理过程的连贯性和可靠性。为了解决这一问题,Step-KTO 通过引入过程奖励模型(PRM)和结果奖励模型(Outcome RM),对模型的中间推理步骤和最终答案进行二元评估,鼓励模型遵循逻辑推理路径,而不仅仅是依赖表面捷径。 Step-KTO 的核心在于将 Kahneman-Tversky 启发的价值函数应用于训练过程中,强调类似人类的风险规避和损失厌恶,促使模型逐步纠正推理错误,避免错误累积。实验结果表明,Step-KTO 在多个数学推理基准测试中显著提高了模型的最终答案准确性和中间推理步骤的质量。例如,在 MATH-500 数据集上,Step-KTO 将 Pass@1 准确率从 53.4% 提高到 63.2%,同时产生了更连贯和可靠的逐步推理。 此外,Step-KTO 通过迭代训练,持续改进模型的推理能力,不仅在结果级上取得了显著提升,而且在过程级上也表现出色。与仅依赖结果级反馈的方法相比,Step-KTO 能够更有效地平衡过程和结果的反馈,从而在复杂推理任务中展现出更好的性能。研究还通过对比分析,展示了 Step-KTO 在减少推理错误和提高推理质量方面的优势。总之,Step-KTO 为提升大型语言模型的数学推理能力提供了一种有效的方法,通过结合过程级和结果级的反馈,引导模型进行更可靠和可解释的推理。 原文链接:https://arxiv.org/pdf/2501.10799 Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models 本文探讨了语言模型中模型参数数量和每个样本的计算量(FLOPs)之间的关系,特别是在稀疏混合专家(MoE)模型中的表现。研究的核心问题是,在固定的训练计算预算下,如何通过调整模型的稀疏性来优化模型性能。研究发现,在预训练阶段,增加模型参数数量比增加每个样本的FLOPs更能有效降低预训练损失。具体来说,随着模型参数数量的增加,最优的稀疏性水平也会提高,这意味着在更大的模型中,增加稀疏性可以更有效地利用训练计算预算。此外,研究还表明,稀疏性对下游任务性能的影响因任务类型而异,对于需要更多推理能力的任务,密集模型可能表现更好。 研究者们定义了稀疏性为不活跃专家与总专家数量的比例,并通过实验发现,在不同的训练计算预算下,存在一个最优的稀疏性水平,可以在提高训练效率的同时提升模型性能。具体来说,随着模型参数数量的增加,最优稀疏性水平也会提高,这意味着在更大的模型中,增加稀疏性可以更有效地利用训练计算预算。此外,研究还表明,稀疏性对下游任务性能的影响因任务类型而异,对于需要更多推理能力的任务,密集模型可能表现更好。 为了更好地理解这些关系,研究者们提出了一个包含稀疏性的参数化扩展定律,通过拟合实验数据来估计模型系数。实验结果验证了该模型的有效性,表明在不同的训练计算预算下,稀疏性对模型性能的影响是一致的。这些发现为设计更高效的MoE模型提供了有价值的指导,特别是在如何平衡参数数量和计算量以优化模型性能方面。研究还指出,虽然稀疏性在提高训练效率方面具有显著优势,但在推理阶段,密集模型在某些任务上可能具有更好的性能,这提示我们在实际应用中需要根据具体任务需求来选择合适的模型配置。 原文链接:https://arxiv.org/pdf/2501.12370
HuggingFace&Github
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
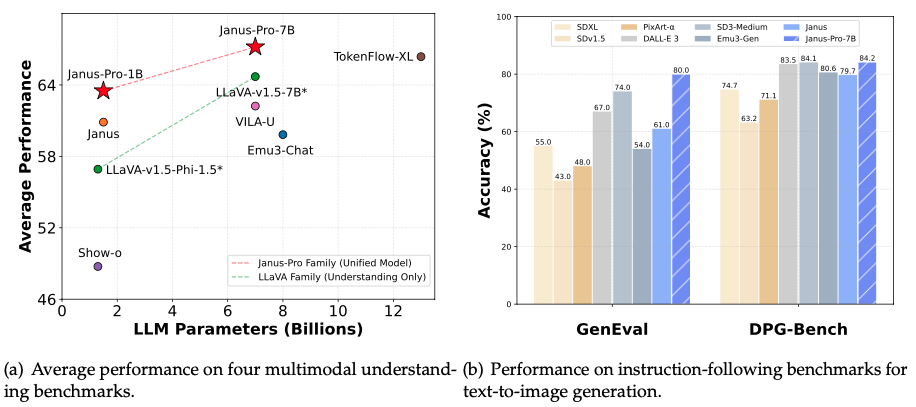
Janus-Pro:多模态理解与生成的全面升级 Janus-Pro 在前作的基础上新增了这些改进: Janus-Pro 在多模态理解和文本到图像的指令遵循能力方面都取得了显著的进步,同时也增强了文本到图像生成的稳定性。 https://github.com/deepseek-ai/Janus Mistral-Small-24B-Instruct-2501 模型卡 Mistral-Small-24B-Instruct-2501 是一款全新发布的 24B 参数指令微调版本,属于“小型”大语言模型的创新标杆,在与更大模型的对比中表现突出。它具备先进的推理能力和语言生成能力,特别适用于快速响应的对话代理、低延迟功能调用及本地推理应用,支持多语言处理并且可以部署在本地硬件,如 RTX 4090 或 32GB 内存的 MacBook。
高级推理与对话能力:在复杂对话和推理任务中表现卓越。
在多项评测中,该模型表现优异,特别是在数学和编程任务中取得了较高的准确率。
与其他模型(如 Gemma-2-27B、Llama-3.3-70B 等)相比,Mistral 在指令跟随和推理任务中的性能尤为突出。
https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501 DeepSeek-R1-GGUF:运行 R1 Dynamic 1.58-bit Unsloth探索如何让更多本地用户使用能够运行DeepSeek-R1,并设法将 DeepSeek R1 的 671B 参数模型量化到 131GB,比原来的 720GB 减少了 80%,同时功能也非常强大。 通过研究DeepSeek R1的架构,设法将某些层量化到更高位(如4比特),而将大多数MoE层量化到1.5比特。
Unsloth对R1动态量化提升了模型的精度,相较于常规 1-bit/2-bit 量化,表现更为出色。
Unsloth的动态量化解决了“量化所有层会破坏模型,导致无休止的循环和胡乱的输出”的问题
Unsloth提供了从 131GB 到 212GB 的动态量化版本。
https://huggingface.co/unsloth/DeepSeek-R1-GGUF FLUX.1 [dev] 是一种开放权重、指导提炼的模型。FLUX.1 [dev] 是包含了 120 亿参数的rectified flow transformer,能够根据文本描述生成图像。 FLUX.1 [dev] 直接从 FLUX.1 [pro] 提炼而来,具有相似的质量和及时遵守能力,同时比同等大小的标准模型更高效。此版本为开发者和创作者提供了更高效的工具,以便他们在艺术创作和研究领域中取得更大的突破。FLUX.1 [dev] 权重可在HuggingFace上使用,并可直接在Replicate或Fal.ai上试用。
顶尖输出质量:仅次于black-forest-labs的旗舰模型 FLUX.1 [pro]
竞争性迅速跟进:在提示匹配性能上,FLUX.1 [dev] 可与闭源替代品相媲美
高效训练:采用引导指导蒸馏(guidance distillation)训练,提高FLUX.1 [dev] 的推理效率
开源权重:开源权重可以推动科学研究,并为艺术家提供创新工作流程的支持。
使用许可:生成的输出可用于”FLUX.1 [dev] 非商业许可证“中所述的个人、科学和商业目的。
https://huggingface.co/black-forest-labs/FLUX.1-dev OpenThinker-7B OpenThinker-7B 文本生成模型是Qwen/Qwen2.5-7B-Instruct在OpenThoughts-114k数据集上的微调版本。
OpenThoughts-114k数据集是通过github上提炼 DeepSeek-R1 得出的。
OpenThoughts-114k数据集详情可以在Hugging Face数据集卡中找到。
OpenThinker-7B 改进了Bespoke-Stratos-7B 模型,使用了Bespoke-Stratos-17k 数据集
模型的权重、数据集、数据生成代码、评估代码和训练代码,所有内容都完全开源。
https://huggingface.co/open-thoughts/OpenThinker-7B Oumi:开源 AI 模型全生命周期平台 Oumi是一个完全开源的平台,覆盖 AI 基础模型从数据准备、训练、评估到部署的全流程,适用于个人开发、集群实验和生产部署。
训练与微调 10M 至 405B 参数 的模型(支持 SFT、LoRA、QLoRA、DPO 等技术)
兼容 Llama、DeepSeek、Qwen、Phi 等文本及多模态模型
本地、集群、云端(AWS、Azure、GCP、Lambda)皆可运行
与开放模型和商业 API 集成 OpenAI、Anthropic、Vertex AI、Together、Parasail 等 API 集成
https://github.com/oumi-ai/oumi Open WebUI:用户友好的 AI 界面 Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种 LLM 运行器(如Ollama)和与OpenAI 兼容的 API,并内置RAG 推理引擎,使其成为强大的 AI 部署解决方案。
Ollama/OpenAI API 集成:与 OpenAI 兼容的 API 和 Ollama 模型无缝集成,支持多种对话接口。
细粒度权限管理:创建用户角色和权限,确保安全性和定制化体验。
模型构建器:通过 Web UI 创建和管理 Ollama 模型,支持自定义角色和元素。
Python 函数调用工具:内建 Python 编辑器,轻松集成 Python 函数与 LLMs。
本地 RAG 集成:支持文档与聊天互动,加载文件直接查询。
网页浏览与搜索:集成网页内容和实时搜索(如 SearXNG、Google、DuckDuckGo 等)。
图像生成:集成图像生成工具(如 DALL-E)增强互动体验。
https://github.com/open-webui/open-webui
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38009.html