我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
如何让 RLHF 训练更稳定?
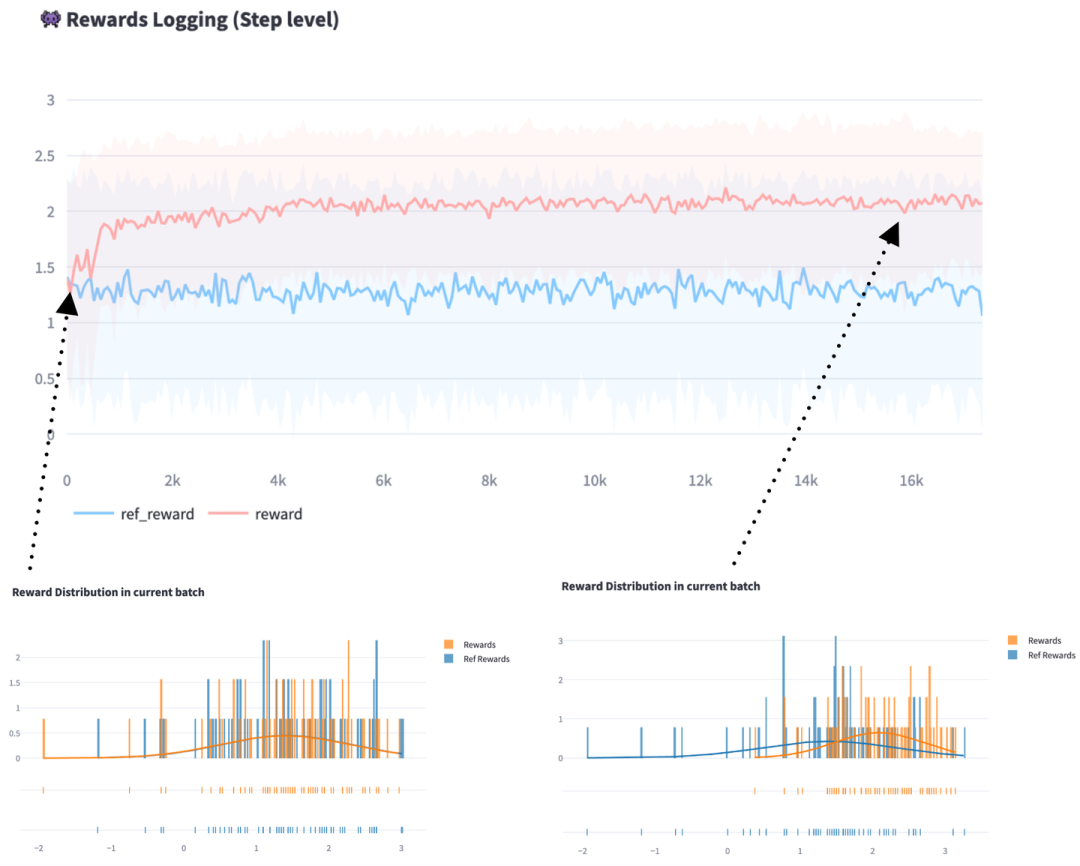
RL Logging Board 是一种用于可视化强化学习(RL)训练过程的工具,专注于展示来自人类反馈的强化学习(RLHF)的关键指标,帮助用户理解和监控训练的细节。其主要目的是直观地展示 RL 训练过程中的模型响应、奖励分布、KL 散度等,进而帮助发现潜在问题,如奖励操控(reward hacking)和模型训练不收敛等。与 TensorBoard 和 wandB 等工具不同,RL Logging Board 关注更细粒度的监控,尤其是在 token 级别的指标。
RL Logging Board 支持多种可视化功能,核心部分包括训练曲线、奖励分布、响应分布、token 级别的奖励和 KL 散度等。它可以通过对比 RL 模型与参考模型的性能,帮助研究人员分析训练的收敛性和异常情况。比如,训练过程中的奖励分布应呈现出越来越尖锐的趋势,而如果这一过程不符合预期,可能意味着训练存在问题。此外,该工具还可以帮助分析每个 batch 中高低奖励样本的分布,帮助定位可能的训练问题。
工具的运行需要与训练框架结合,并要求框架中保存相应的指标数据(通常为 .jsonl 格式)。这些数据包括了每个训练步骤(step)的 prompt、response、奖励、token 级别的 logprobs、reward、value 等信息。通过对这些数据的可视化,用户可以查看每个 token 在训练过程中的变化情况,了解其在策略优化中的作用。例如,观察某些 token 的奖励和 critic 值,能够揭示模型在某些 token 上的表现是否符合预期。
工具还提供了多种排序功能,允许按奖励、KL 散度等指标对样本进行排序,帮助快速定位训练中的异常样本,并分析其潜在问题。对于每个 token,工具可以展示其被选择的概率分布,这些数据有助于深入理解模型的策略变化。
https://zhuanlan.zhihu.com/p/16734946629
Flash Attention 3 深度解析
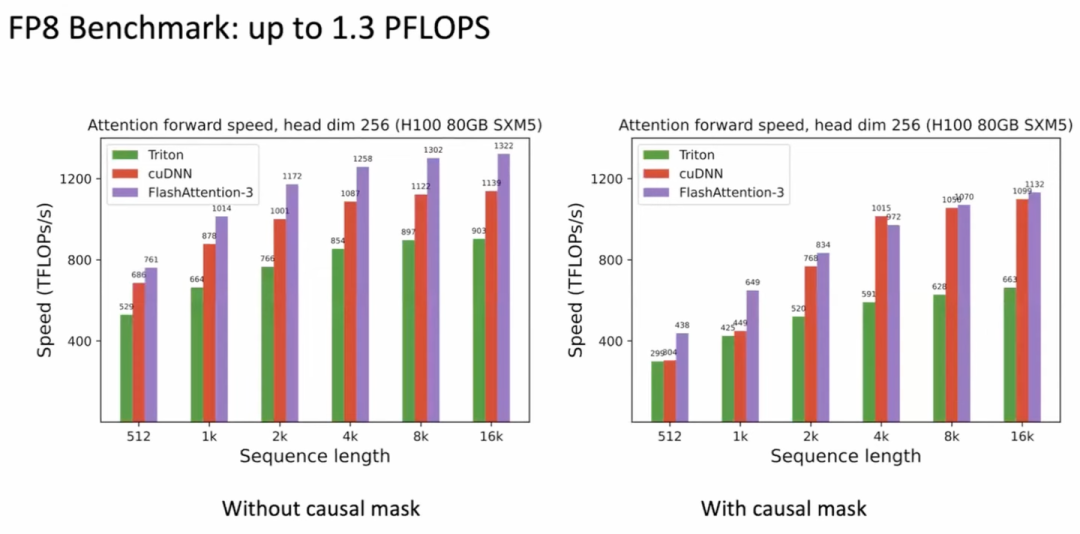
FA2 是当前在大规模语言模型(LLM)中广泛使用的 Attention 算法,它通过优化内存访问,减少了跨存储层级(如 GMEM 和 SMEM)的数据传输,在 A100 上实现了 2-4 倍的速度提升。然而,FA2 在 H100 上的性能表现并不理想,GPU 利用率仅为 35%-40%。这主要是因为 FA2 尚未充分利用 H100 架构的异步通信和低精度运算等新特性,这限制了其在现代硬件上的性能发挥。
H100 引入了 TMA 和 WGMMA 等新硬件指令,支持异步计算与通信,优化了低精度运算,如 FP8,使得计算和数据传输可以并行进行,显著提升性能。FA3 作为 FA2 的继任者,通过充分利用这些硬件特性,优化了 Attention 计算,尤其在长序列计算上表现出色,具有显著的性能优势。
FA2 的核心思想在于通过减少 GMEM 和 SMEM 之间的数据传输来提高效率。通过采用 Softmax Tiling 和重计算技术,FA2 能够有效降低对 GMEM 的依赖,提升性能。特别是在 A100 上,SMEM 的带宽较高,使用 SMEM 存储的数据可以大幅提高计算速度,FA2 在这方面表现尤为突出。
然而,H100 的设计增加了 Warpgroup 和 TMA 等硬件特性,这些尚未在 FA2 中得到充分利用。WGMMA 支持 Warpgroup 级别的异步矩阵乘法,使得不同计算单元可以并行工作,提升计算资源的利用率。而 TMA 则通过硬件支持异步数据传输,减少了 SM 线程对数据搬运的依赖,进一步优化了性能。
在 FA3 中,算法通过异步调度和数据重排等技术,使得计算和数据传输的重叠成为可能。例如,GEMM 和 Softmax 计算可以重叠进行,通过合理安排计算单元的调度,显著提高了算力的利用率。此外,低精度运算(如 FP8)在硬件上的支持,允许算子进行更多的计算,减少显存和带宽的消耗,进一步提升性能。
FA3 在细节实现上还包括了 Warp Specialization 和 Intra-warpgroup overlapping 等优化策略,这些技术通过在 Warpgroup 内部进行计算和通信的重叠,提高了计算效率。此外,Ping-Pong Scheduling 使得多个计算单元可以交替进行计算,进一步提升了吞吐量。
https://zhuanlan.zhihu.com/p/17533058076
HuggingFace&Github
多模式-教科书-6.5M 数据集
该数据集用于“2.5 年课堂:视觉语言预训练的多模式教科书”,包含 650 万张图像和来自教学视频的 8 亿条文本。
-
它包含使用交错图像文本格式的预训练语料库。具体来说,我们的多模式教科书包括从教学视频中提取的6.5M 个关键帧,与 0.8B ASR 文本交错。
-
所有图片和文字均摘录自在线教学视频(22000课时),涵盖数学、物理、化学等多个基础学科。
-
我们的教科书语料库为图像文本对齐提供了更连贯的背景和更丰富的知识。
该模型利用 GPT-4o 综合了我们的知识分类法,包含 6 个学科的 3915 个知识点,这使我们能够基于该分类法自动收集 159K 个英语教学视频。
按照我们的视频到教科书流程,我们过滤掉 53% 的低质量或重复视频,并保留 75K 个视频(22,697 个课时),平均时长为 18 分钟。
然后我们从这些视频中提取了 6.5M 个关键帧和 0.75B 个文本(ASR+OCR)标记。为了提高训练效率,我们将多个视频片段拼接成一个样本,总共生成 610K 个交错样本。每个样本平均包含 10.7 个关键帧和 1,230 个文本标记。
https://huggingface.co/datasets/DAMO-NLP-SG/multimodal_textbook
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/32712.html