我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
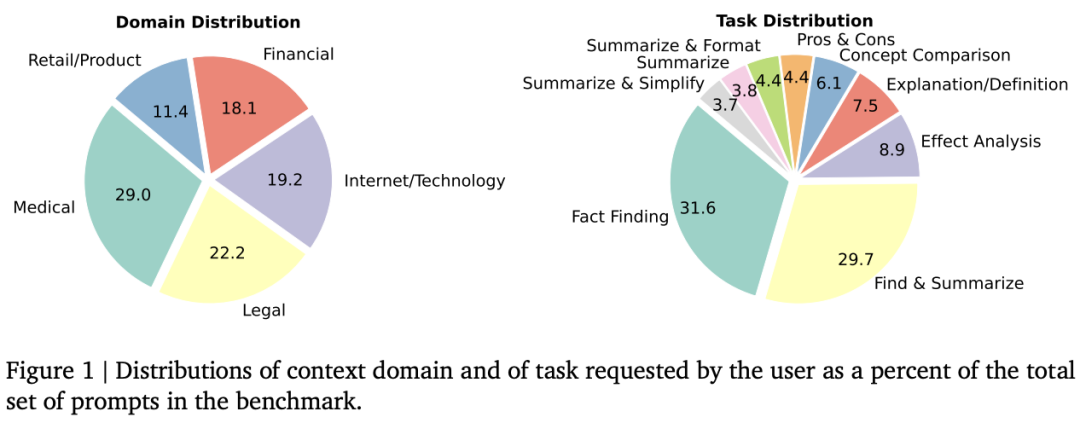
The FACTS Grounding Leaderboard: Benchmarking LLMs’ Ability to Ground Responses to Long-Form Input
论文推出了 FACTS Grounding,这是一个在线排行榜和相关基准,用于评估语言模型生成与用户提示中给定上下文相关的事实准确文本的能力。在论文的基准中,每个提示都包含一个用户请求和一个完整文档,最大长度为 32k 个标记,需要长格式响应。长格式响应需要在满足用户请求的同时完全基于提供的上下文文档。使用自动判断模型分两个阶段对模型进行评估:(1) 如果响应不符合用户要求,则取消其资格;(2) 如果响应完全基于提供的文档,则判断其准确。根据保留的测试集对自动判断模型进行了全面评估,以选出最佳提示模板,最终的事实性分数是多个判断模型的总和,以减轻评估偏差。FACTS Grounding 排行榜将随着时间的推移得到积极维护,并包含公共和私人分割,以允许外部参与,同时保护排行榜的完整性。
https://arxiv.org/abs/2501.03200
ResearchFlow链接:https://rflow.ai/flow/798277b3-0b47-4d19-b9ca-0b475f5cd9f5
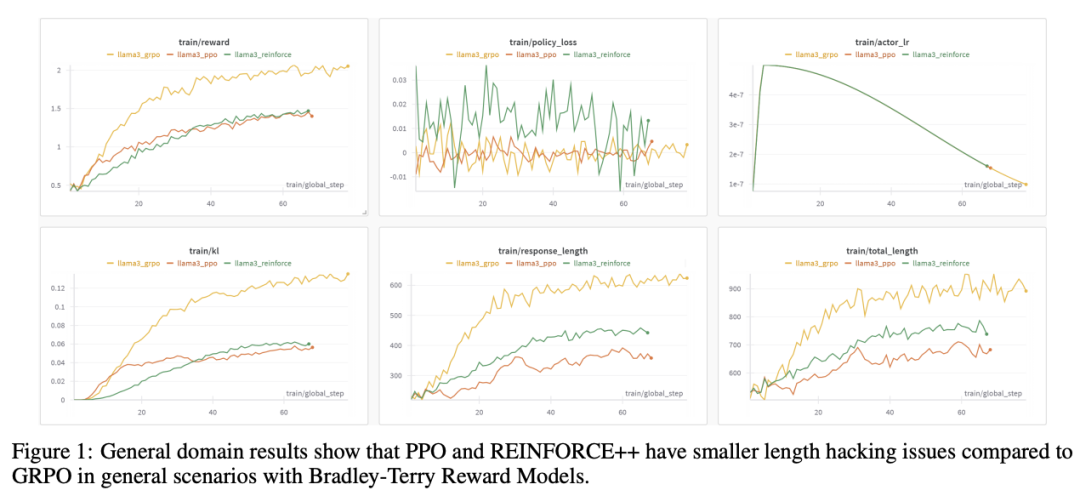
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models
基于人类反馈的强化学习 (RLHF) 已成为将大型语言模型与人类偏好相结合的关键方法,并通过近端策略优化 (PPO)、直接偏好优化 (DPO)、REINFORCE 留一法 (RLOO)、ReMax 和组相对策略优化 (GRPO) 等方法见证了算法的快速发展。论文提出了 REINFORCE++,这是经典 REINFORCE 算法的增强版本,它结合了 PPO 的关键优化技术,同时消除了对批评者网络的需求。REINFORCE++ 实现了三个主要目标:(1) 简单 (2) 增强训练稳定性,(3) 减少计算开销。通过大量的实证评估,论文证明 REINFORCE++ 比 GRPO 表现出更好的稳定性,并且在保持可比性能的同时实现了比 PPO 更高的计算效率。
https://arxiv.org/abs/2501.03262
ResearchFlow链接:https://rflow.ai/flow/1c25a271-6735-42d5-b9be-e0f1167c3ae4
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/32651.html