我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
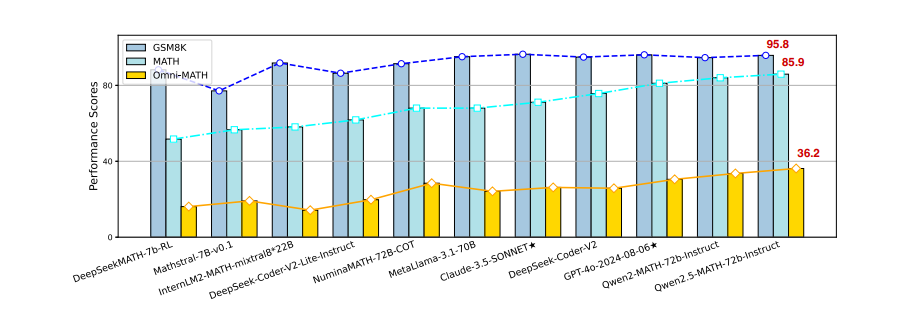
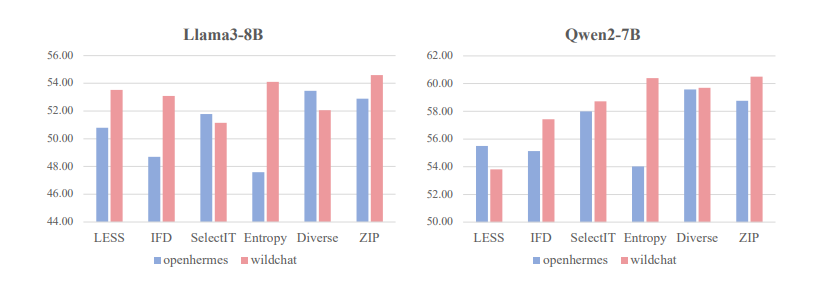
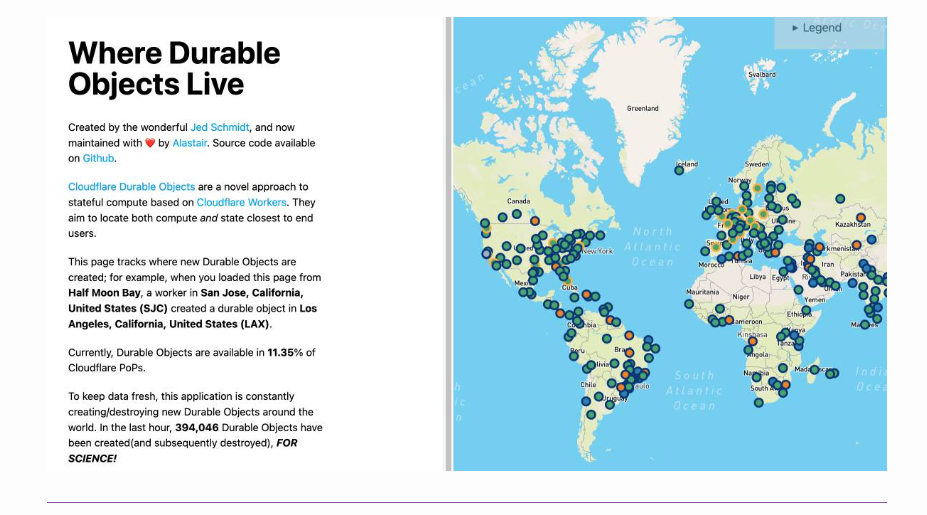
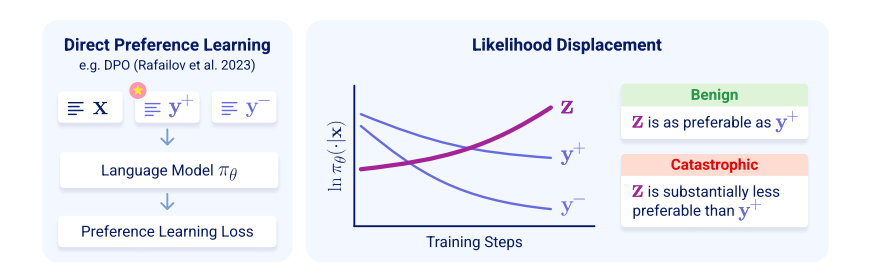
信号 Toward General Instruction-Following Alignment for Retrieval-Augmented Generation 这篇文章介绍了VIF-RAG,这是一个自动化、可扩展且可验证的合成流程,用于在检索增强生成(RAG)系统中提高指令遵循(IF)的一致性。研究者们首先手动创建了一组最小的原子指令,并开发了组合规则来合成和验证复杂指令。然后,他们使用监督模型来重写指令,并通过Python执行器自动生成代码以验证指令质量。此外,他们还创建了一个高质量的VIF-RAG-QA数据集,包含超过100k的样本,并通过自动化流程扩展。为了进一步缩小RAG系统在指令遵循自动评估方面的差距,研究者们引入了FollowRAG基准测试,包含约3K的测试样本,涵盖22种通用指令约束类别和四个知识密集型问答数据集。VIF-RAG显著提高了LLM在各种通用指令约束下的性能,并在RAG场景中有效利用了其能力。文章还提供了实现RAG系统中IF对齐的实际见解。研究者们发布了代码和数据集。 https://arxiv.org/pdf/2410.09584 MMIE: Massive Multimodal Interleaved Comprehension Benchmark for Large Vision-Language Models 这篇文章介绍了一个名为MMIE的大规模基准测试,用于评估大型视觉-语言模型(LVLMs)在交错多模态理解和生成方面的能力。MMIE包含20,000个精心策划的多模态查询,覆盖了3个类别、12个领域和102个子领域,支持交错输入和输出,并提供多种选择题和开放式问题格式来评估不同的能力。此外,文章还提出了一种可靠的自动化评估指标,该指标基于经过人类标注数据微调的评分模型和系统化的评估标准,旨在减少偏见并提高评估准确性。实验结果表明,MMIE能够全面评估交错LVLMs的表现,同时也揭示了现有最佳模型仍有很大的改进空间。 https://arxiv.org/pdf/2410.10139 Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models 这篇文章提出了一个新的基准测试,旨在评估大型语言模型(LLMs)在奥林匹克级别的数学推理能力。现有的基准测试,如GSM8K或MATH,已经被高级模型以高准确率解决,因此需要一个新的挑战性基准来测试这些模型的能力。新提出的基准测试专注于数学领域,包含4428个竞赛级别的问题,这些问题经过了严格的人工标注,并被细致地分类到超过33个子领域,涵盖了10个不同的难度级别。实验结果显示,即使是最先进的模型,如OpenAI o1-mini和OpenAI o1-preview,在面对高度挑战性的奥林匹克级别的问题时,准确率也分别只有60.54%和52.55%,这突显了在奥林匹克级别数学推理方面的重大挑战。 https://arxiv.org/pdf/2410.07985 LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models 这篇文章介绍了一个名为LOKI的新基准,用于评估大型多模态模型(LMMs)在检测合成数据方面的能力。随着AI生成内容的快速发展,区分真实与合成数据变得越来越重要。LOKI涵盖视频、图像、3D、文本和音频等多种模态,包含18,000个精心策划的问题,覆盖26个子类别,并有明确的难度等级。该基准测试包括粗粒度判断和选择题,以及细粒度异常选择和解释任务,能够全面分析LMMs的表现。文章对22个开源LMMs和6个闭源模型进行了LOKI上的评估,展示了这些模型作为合成数据检测器的潜力,同时也揭示了它们在能力发展上的一些局限性。 https://huggingface.co/papers/2410.09732 Rethinking Data Selection at Scale: Random Selection is Almost All You Need 这篇文章探讨了在大规模数据集中对大型语言模型(LLMs)进行监督式微调(SFT)时的数据选择问题。文章的主要目标是在SFT中从更大的数据池中选择一个小型但具有代表性的子集,以便使用这个子集进行微调能够达到与使用整个数据集相当或更好的结果。研究发现,大多数现有的数据选择技术都是为小规模数据池设计的,无法满足现实世界中SFT场景的需求。文章复制了几种自评分方法,这些方法不依赖于外部模型的帮助,并且在大规模数据集上进行测试,发现几乎所有方法在处理大规模数据池时的表现都难以显著优于随机选择。此外,文章还分析了几种当前方法的局限性,并解释了为什么它们在大规模数据集上表现不佳,以及为什么它们不适合这样的环境。最后,文章发现通过令牌长度过滤数据提供了一种稳定且高效的方法来提高结果,特别是当训练长文本数据时,这种方法对相对较弱的基础模型(如Llama3)非常有益。 https://huggingface.co/papers/2410.09335 Language model developers should report train-test overlap 这篇文章指出了语言模型评估中一个关键但常被忽视的问题:训练-测试重叠(train-test overlap),即模型在测试时所用的数据与训练数据的重合程度。当前公众缺乏关于训练-测试重叠的充分信息,因为大多数模型没有公开相关的统计数据,第三方也无法直接测量这一重叠,因为他们无法访问训练数据。文章调查了30个模型的实践情况,发现只有9个模型报告了训练-测试重叠信息,其中4个模型开放了训练数据,5个模型发布了它们的训练-测试重叠方法和统计数据。通过与语言模型开发者合作,作者为另外三个模型提供了新的训练-测试重叠信息。文章主张语言模型开发者应当在报告公共测试集上的评估结果时,发布训练-测试重叠统计数据或训练数据,以增加评估透明度和社区对模型评估的信任。 https://arxiv.org/abs/2410.08385 Zero-latency SQLite storage in every Durable Object 这篇文章介绍了Cloudflare的Durable Object平台的最新迭代,它将一个基于SQLite的完整关系系统整合到了Durable Object中,实现了零延迟的SQLite存储。文章强调了Durable Objects的设计理念,即将应用逻辑与数据存储在同一物理主机上,以实现快速的读写性能。此外,还讨论了如何在大规模应用中实现这一点,包括通过创建更多的对象来处理更多的流量,以及如何通过Cloudflare的网络路由请求到特定的Durable Object。技术细节包括每个Durable Object不断向对象存储流式传输WAL日志条目,以及如何确保在10秒窗口内的数据持久性。 https://x.com/swyx/status/1845714328260878535 DROP: Dexterous Reorientation via Online Planning 这篇文章探讨了在接触丰富的操作任务中使用在线规划方法的可行性,特别是针对著名的手内立方体重定向任务。作者提出了一种简单的架构,该架构结合了基于采样的预测控制器和基于视觉的姿态估计器,以在线搜索接触丰富的控制动作。通过广泛的实验,文章评估了该方法在现实世界中的性能、架构设计选择以及关键因素,并展示了这种基于简单采样的方法能够达到与先前基于强化学习(RL)的方法相媲美的性能。 https://arxiv.org/abs/2409.14562 Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization 这篇文章探讨了直接偏好优化(DPO)及其变体在使语言模型与人类偏好对齐时出现的一个反直觉现象——即在训练过程中,优选响应的似然性反而下降,这一现象被称为“似然位移”。文章揭示了这种现象的原因和影响,指出它可能导致概率质量从优选响应转移到相反意义的响应上。例如,训练一个模型更偏好“No”而不是“Never”,可能会意外地增加“Yes”的概率。此外,当试图让模型拒绝不安全的提示时,这种位移可能无意中导致模型不再对齐,从而增加有害响应的概率。文章通过理论分析发现,这种似然位移是由诱导相似嵌入的偏好驱动的,并提出了一个中心化隐藏嵌入相似性(CHES)评分来量化这一点。实验证明,过滤掉那些CHES评分高的样本可以有效减轻无意中的不对齐问题。 https://arxiv.org/abs/2410.08847
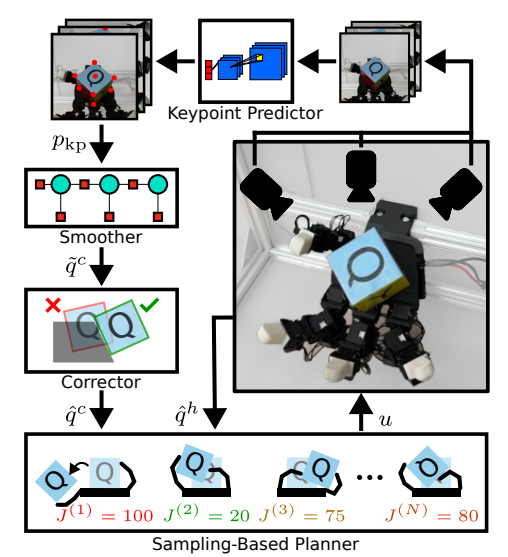
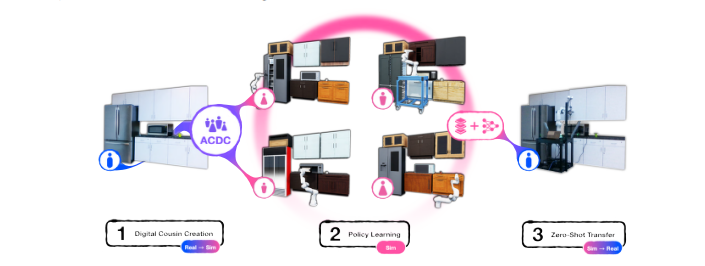
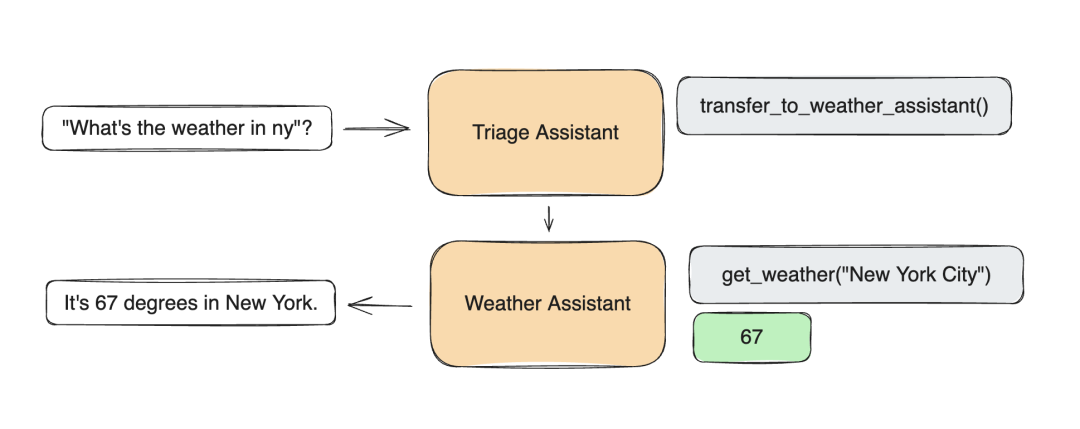
Uncovering Latent Memories: Assessing Data Leakage and Memorization Patterns in Frontier AI Models 这份报告包含了加州大学伯克利分校机器学习入门课程的讲义,涵盖了多种分类和回归方法,以及一些聚类和降维技术。它内容精炼,仅包含在一个学期内可以讲授的内容,并且选择了特别有用和流行的算法进行讲解。 https://arxiv.org/abs/2406.14549 ARCap: Collecting High-quality Human Demonstrations for Robot Learning with Augmented Reality Feedback 这篇文章介绍了一种名为ARCap的便携式数据收集系统,它通过增强现实(AR)提供视觉反馈和触觉警告来指导用户收集高质量的演示数据。ARCap旨在解决使用便携设备进行数据收集时缺乏机器人实时反馈的问题,使得即使是新手用户也能收集到符合机器人运动学要求且避免场景碰撞的数据。实验表明,使用ARCap收集的数据可以帮助机器人执行复杂的任务,如在杂乱环境中操作物体以及跨不同机器人形态的长时间操作。ARCap是完全开源的,并且易于校准,所有组件都是由现成产品构建而成。 https://arxiv.org/abs/2410.08464 ACDC: Automated Creation of Digital Cousins for Robust Policy Learning 这篇文章提出了一种名为“数字表亲”(digital cousins)的概念,它是一种虚拟资产或场景,虽然不像数字孪生那样精确复制现实世界中的对应物,但仍然保留了相似的几何和语义属性。通过这种方式,数字表亲可以降低创建类似虚拟环境的成本,并且通过提供一系列相似的训练场景来提高从仿真到现实世界的迁移鲁棒性。文章还介绍了一种自动创建数字表亲的方法ACDC(Automatic Creation of Digital Cousins),以及一个全自动的真实-仿真-真实流水线,用于生成完全交互式的场景并训练机器人策略,这些策略可以在原始场景中零样本部署。实验表明,使用ACDC训练的策略在零样本仿真到现实世界的迁移中表现优于使用数字孪生训练的策略。 https://arxiv.org/abs/2410.07408 SWARM Swarm 是一个知识性内容,探索多智能体编排的人性化和轻量级方法。它提供了两个基本内容:智能体和交接。智能体包含指令和工具,可以随时选择将对话交给另一个智能体。这些足以表达工具和智能体网络之间的丰富动态,使用户能够构建可扩展的实际解决方案,同时避免过于复杂的学习。 https://github.com/openai/swarm
Genaiscript GenAIScript 是一个功能强大的脚本环境,专门为构建和管理大型语言模型 (LLM) 提示而设计。无论是开发人员、数据科学家还是研究人员,GenAIScript 都提供了相对应的工具来高效地创建、调试和共享脚本。 https://github.com/microsoft/genaiscript LLM PLSE paper 这个 GitHub 项目是一个关于使用大语言模型(LLM)进行代码分析和软件工程应用的研究合集。该项目涵盖了多个方向,包括漏洞检测、代码生成、代码推理、测试和调试等。 https://github.com/wcphkust/LLM-PLSE-paper
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21586.html