我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
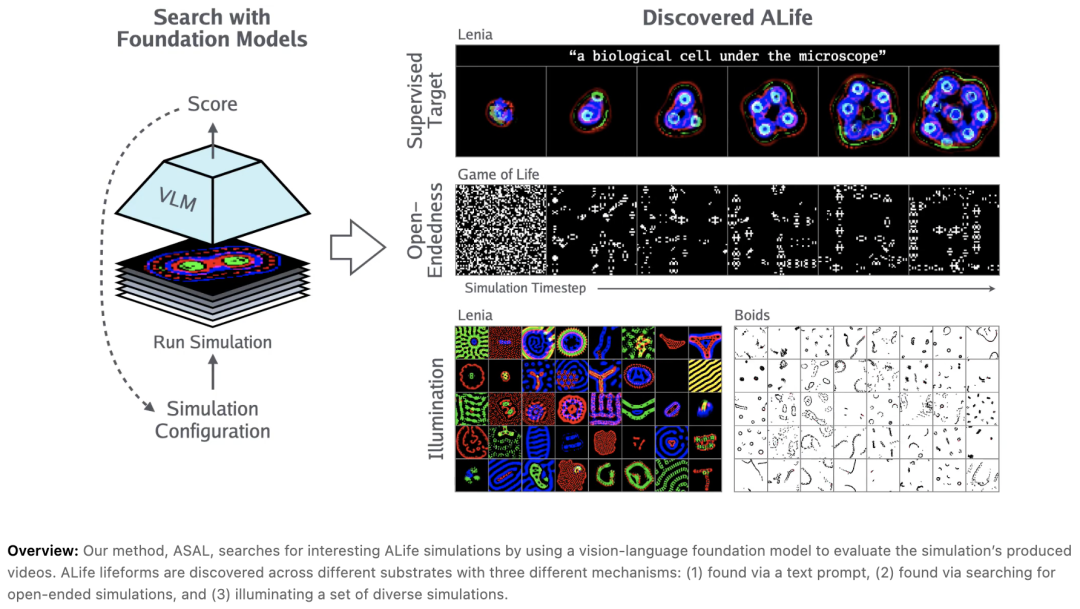
Automating the Search for Artificial Life with Foundation Models
随着最近诺贝尔奖因蛋白质发现领域的重大进展而颁发,用于探索大型组合空间的FM有望彻底改变许多科学领域。人工生命 (ALife) 尚未整合 FM,因此为该领域提供了一个重大机会,以减轻主要依靠手动设计和反复试验来发现逼真模拟配置的历史负担。本文首次介绍了使用视觉语言 FM 成功实现这一机会的方法。所提出的方法称为自动搜索人工生命,(1) 找到产生目标现象的模拟,(2) 发现产生时间开放的新颖性的模拟,以及 (3) 照亮整个有趣多样的模拟空间。由于 FM 的通用性,ASAL 可在各种 ALife 基质中有效工作,包括 Boids、粒子生命、生命游戏、Lenia 和神经细胞自动机。突出该技术潜力的主要成果是发现了以前从未见过的 Lenia 和 Boids 生命形式,以及像康威生命游戏一样开放式的细胞自动机。此外,使用 FM 可以以人为本的方式量化以前定性的现象。这种新范式有望加速 ALife 研究,超越仅靠人类智慧所能实现的范围。
链接:https://arxiv.org/abs/2412.17799
ResearchFlow链接:https://rflow.ai/flow/2e80e9aa-e660-4d58-a438-a48d19ad724d
Mamba2D: A Natively Multi-Dimensional State-Space Model for Vision Tasks
状态空间模型 (SSM) 最近成为长期存在的 Transformer 架构的强大而有效的替代方案。然而,现有的 SSM 概念化保留了源自自然语言处理的根源的根深蒂固的偏见。这限制了它们适当地模拟视觉输入的空间相关特征的能力。本文通过从原生多维公式开始重新推导现代选择性状态空间技术来解决这些限制。目前,先前的工作尝试通过依赖任意组合的一维扫描方向来捕获空间依赖性,将原生的一维 SSM 应用于二维数据。相比之下,Mamba2D 通过单个二维扫描方向对此进行了改进,该方向原生地考虑了输入的两个维度,在构建隐藏状态时有效地模拟了空间依赖性。在使用 ImageNet-1K 数据集进行标准图像分类评估时,Mamba2D 表现出与之前针对视觉任务的 SSM 改编相当的性能。
链接:https://arxiv.org/abs/2412.16146
ResearchFlow链接:https://rflow.ai/flow/abfd7bba-8ab0-4d29-ab6d-e2cb2cf27218
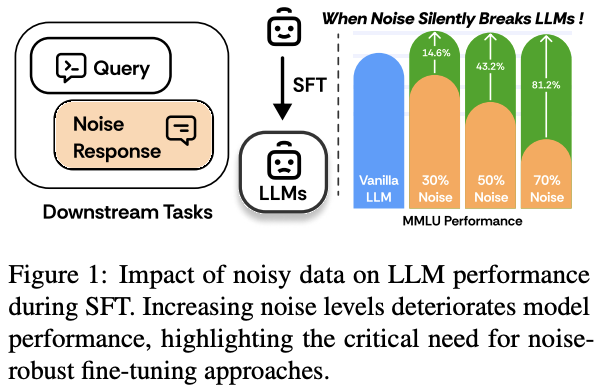
RobustFT: Robust Supervised Fine-tuning for Large Language Models under Noisy Response
监督微调 (SFT) 在将LLM适配到特定领域或任务方面起着至关重要的作用。然而在实际应用中,收集的数据不可避免地包含噪声,这对模型在下游任务上的性能提出了重大挑战。因此,迫切需要一个抗噪声的 SFT 框架来增强模型在下游任务中的能力。为了应对这一挑战,本文引入了一个强大的 SFT 框架 (RobustFT),它可以对下游任务数据执行噪声检测和重新标记。对于噪声识别,本文方法采用多专家协作系统和推理增强模型来实现卓越的噪声检测。在去噪阶段,采用上下文增强策略,该策略结合最相关和最可信的知识,然后进行仔细评估以生成可靠的注释。此外,论文引入了一种基于响应熵的有效数据选择机制,确保只保留高质量样本进行微调。在五个数据集上对多个 LLM 进行的大量实验证明了 RobustFT 在嘈杂场景中的卓越性能。
链接:https://arxiv.org/abs/2412.14922
ResearchFlow链接:https://rflow.ai/flow/146da2e3-b695-4526-b998-fb331216d983
DepthLab: From Partial to Complete
缺失值仍然是深度数据在其广泛应用中面临的常见挑战。本文工作通过 DepthLab 弥补了这一空白,DepthLab 是一个由图像扩散先验驱动的基础深度修复模型。本文提出的模型具有两个显着的优势:(1)对深度不足区域具有弹性,为连续区域和孤立点提供可靠的补全;(2)在填充缺失值时,模型忠实地保持了与条件已知深度的比例一致性。利用这些优势,这种方法在各种下游任务中证明了其价值,包括 3D 场景修复、文本到 3D 场景生成、使用 DUST3R 进行稀疏视图重建以及 LiDAR 深度补全,在数值性能和视觉质量方面均超越了当前解决方案。
链接:https://arxiv.org/abs/2412.18153
ResearchFlow链接:https://rflow.ai/flow/7da320e0-58fa-483e-95b8-30a723041371
HuggingFace&Github
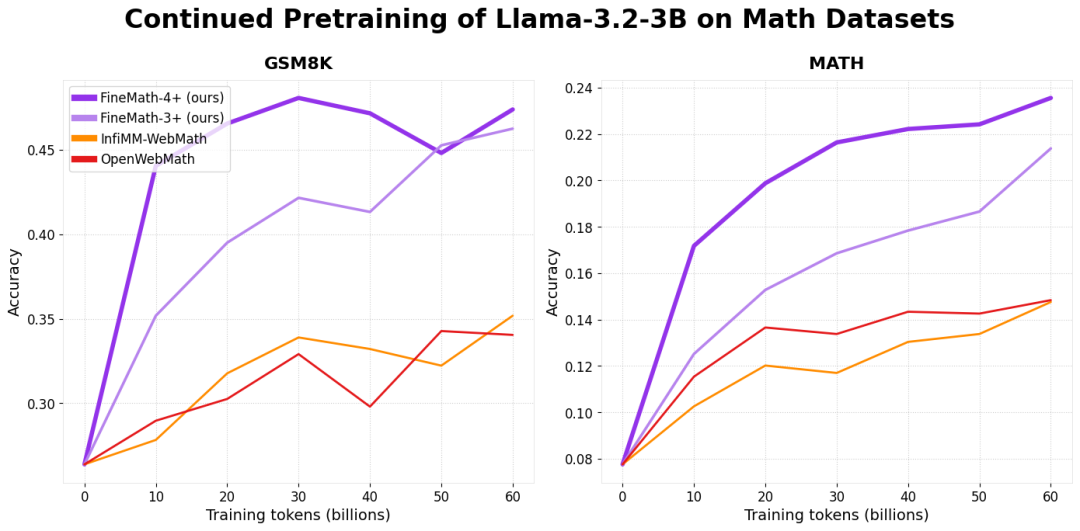
FineMath-4+ 高质量数学教育数据集
📐 FineMath 由从 CommonCrawl 中筛选出的340 亿个标记(FineMath-3+)和540 亿个标记(FineMath-3+ 和 InfiMM-WebMath-3+)数学教育内容组成。为了整理这个数据集,我们使用 LLama-3.1-70B-Instruct 生成的注释训练了一个数学内容分类器。我们使用分类器仅保留最具教育意义的数学内容,重点是清晰的解释和逐步解决问题,而不是高级学术论文。
https://huggingface.co/datasets/HuggingFaceTB/finemath
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29112.html