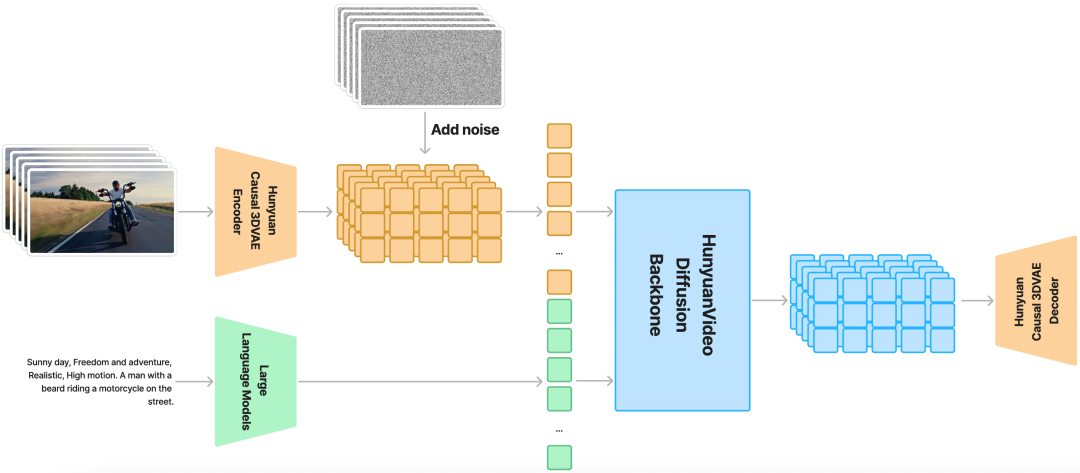
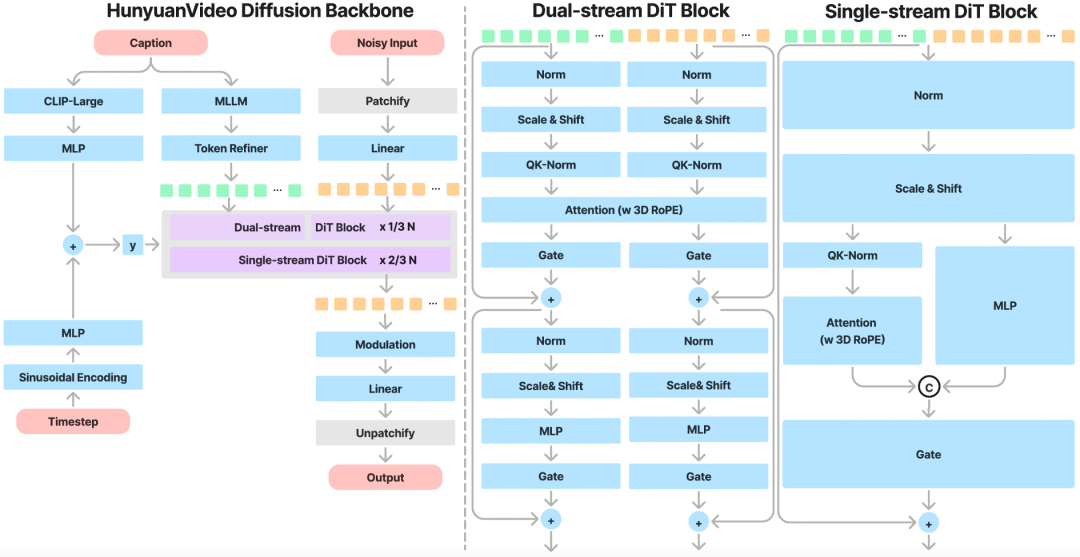
混元视频是一种新颖的开源视频基础模型,其视频生成性能可与领先的闭源模型相媲美,甚至优于它们。HunyuanVideo 具有一个综合框架,该框架集成了多项关键贡献,包括数据管理、图像-视频联合模型训练以及旨在促进大规模模型训练和推理的高效基础设施。此外,通过有效的模型架构和数据集扩展策略,我们成功训练了一个具有超过 130 亿个参数的视频生成模型,使其成为所有开源模型中最大的模型。混元视频进行了大量的实验,并实施了一系列有针对性的设计,以确保高视觉质量、运动多样性、文本-视频对齐和生成稳定性。根据专业人工评估结果,HunyuanVideo 的表现优于之前的先进模型,包括 Runway Gen-3、Luma 1.6 和 3 个表现最好的中文视频生成模型。通过发布基础模型及其应用程序的代码和权重,我们旨在弥合闭源和开源视频基础模型之间的差距。这一举措将使社区中的每个人都能尝试自己的想法,从而培育一个更具活力和生机的视频生成生态系统。https://huggingface.co/tencent/HunyuanVideo 推荐阅读 — END —1. The theory of LLMs|朱泽园ICML演讲整理