我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
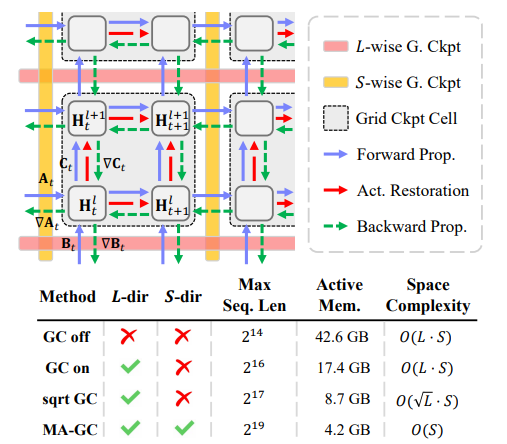
Look Every Frame All at Once: Video-Ma^2mba for Efficient Long-form Video Understanding with Multi-Axis Gradient Checkpointing
这篇文章介绍了Video-Ma2mba,这是一种新型的架构,它将状态空间模型(SSMs)整合到Mamba-2框架中,用以替代注意力机制,从而使得大型多模态模型(LMMs)在处理长视频序列时的时间和内存需求线性增加,而不是二次方增加。此外,文章还提出了多轴梯度检查点(MA-GC)方法,该方法通过在多个计算轴上仅保留必要的激活来策略性地管理内存,显著减少了与标准梯度检查点相比的内存占用。实证分析表明,Video-Ma2mba能够在单个GPU上处理相当于数百万标记或超过两小时连续序列的大量视频序列,同时保持对时间动态的详细捕捉,提高了长视频理解任务的准确性和相关性,显示出比现有框架更大的优势。
https://arxiv.org/abs/2411.19460
学术报告链接:https://rflow.ai/flow/58810a28-d17c-476f-a4a5-47da34ff240e
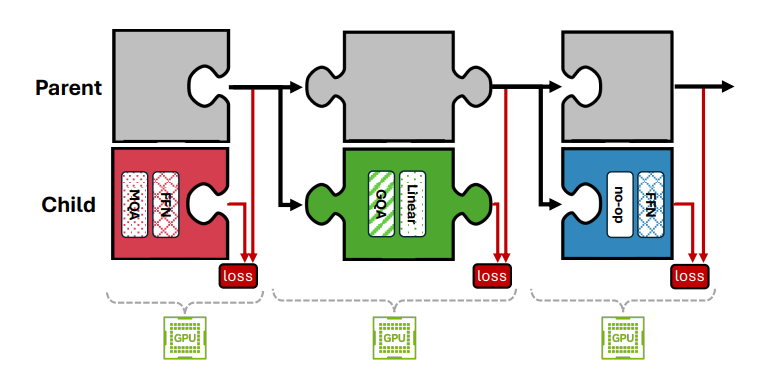
Puzzle: Distillation-Based NAS for Inference-Optimized LLMs
这篇文章介绍了Puzzle框架,这是一个用于加速特定硬件上大型语言模型(LLMs)推理的框架,同时保持模型的能力。Puzzle通过在前所未有的规模上创新性地应用神经架构搜索(NAS),系统地优化了在硬件约束下具有数十亿参数的模型。该框架利用块局部知识蒸馏(BLD)进行并行架构探索,并使用混合整数编程进行精确的约束优化。文章通过Llama-3.1-Nemotron-51B-Instruct(Nemotron-51B)模型展示了Puzzle框架的实际影响,这是一个从Llama-3.1-70B-Instruct衍生的公开可用模型。Nemotron-51B在单个NVIDIA H100 GPU上实现了2.17倍的推理吞吐量加速,同时保持了原始模型能力的98.4%。这一转变仅需要45B训练令牌,与其衍生的70B模型使用的超过15T令牌相比,显著减少了。这建立了一个新的范式,即强大的模型可以针对高效部署进行优化,而几乎不会牺牲它们的性能,表明推理性能而不仅仅是参数数量,应该指导模型选择。随着Nemotron-51B的发布和Puzzle框架的展示,实践者可以立即以显著降低的计算成本获得最先进的语言建模能力。
https://arxiv.org/abs/2411.19146
学术报告链接:https://rflow.ai/flow/2c725e23-2977-4649-accf-ac5e1514d237
Restai
RESTai 是一个开源的 AIaaS 平台,基于 LlamaIndex 和 Langchain 构建,支持多种公开和本地 LLM 模型。它提供精确的嵌入使用和调优功能,内置图像生成工具(如 Dall-E 和 Stable Diffusion),并支持多种类型的 AI 代理。该平台具备自动 VRAM 管理、完整的 API 文档(使用 Swagger 描述),以及对多种嵌入模型和向量存储的支持。
https://github.com/apocas/restai
Athina-evals
Athina-evals 是一个开源的 Python SDK,提供超过 50 种预设评估指标,用于评估大语言模型(LLM)生成的响应,同时支持自定义评估指标。该 SDK 作为 Athina IDE 的配套工具,允许用户在 IDE 中原型化管道、运行实验并比较数据集。
https://github.com/athina-ai/athina-evals
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/24238.html