我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
我在vLLM团队的2024冒险
游凯超分享了自己与vLLM团队合作的经历,讲述了自己如何从视频压缩研究转向大语言模型(LLM)的研究,并参与了vLLM团队的项目。在过去的一年里,游凯超放弃了即将毕业的机会,选择延期一年专注于LLM,最终在导师的帮助下联系到了vLLM项目的指导教授Ion Stoica,开始了与vLLM团队的合作。
在vLLM团队中,他首先参与了性能基准测试(performance benchmark)的设计,面对的挑战主要来自于两类不同的目标用户:vLLM开发者和LLM从业者。前者希望通过基准测试评估新代码的性能变化,而后者关注vLLM与其他开源项目之间的性能对比。游凯超设计了两套基准测试,分别用于展示vLLM内部性能变化以及与其他开源项目(如LMDeploy、TGI等)的对比。尽管在进行测试时遇到不少挑战,尤其是在与TensorRT-LLM进行对比时,最终他成功地实现了自动化性能测试,并为vLLM团队提供了第一版性能测试工具,虽然初版存在不完全公平的问题,但为进一步优化提供了基础。
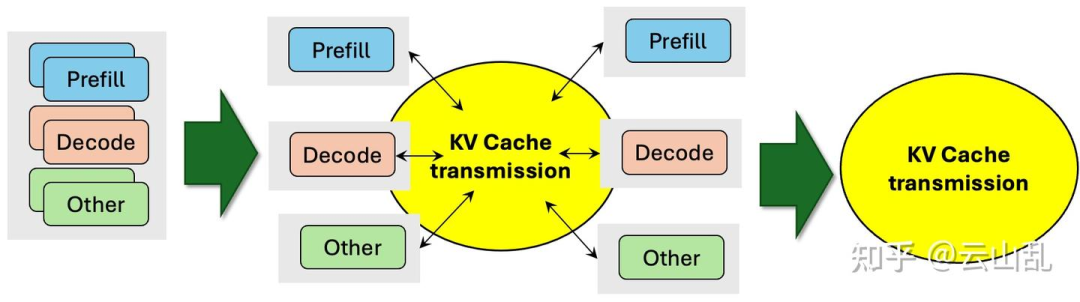
在完成基准测试后,游凯超转向了更具挑战性的研究方向——分布式推理中的KV cache传输问题。基于PD分离技术,他提出了将不同功能放在不同机器上的解决方案,从而优化了不同vLLM实例间的KV cache传输。与以往的方案相比,他的实现方式对vLLM核心代码的改动非常小(不到100行)。这一研究方向的灵感来自于他的博士课题组的另一个项目LMCache,后者正致力于扩展和优化vLLM中的KV cache存储及其互联功能。
通过与多个团队(如Mooncake、SGLang、NVIDIA等)进行广泛讨论,游凯超逐步完善了KV cache传输的设计,并认识到,优化传输的核心不在于单独实现,而在于为第三方实现提供规范接口,确保与vLLM的高效融合。
此外,游凯超还探讨了开源在学术研究中的重要性。他认为,做开源项目虽然会牺牲一定的论文产出,但能提供宝贵的工程视角,有助于研究者发现真正有价值的科研问题,并推动工业界和学术界的深度融合。开源让研究者能够接触到真实的应用场景,得到来自社区和工业界的反馈,从而更好地进行顶尖的系统研究。
https://zhuanlan.zhihu.com/p/15177057416
2024 年终总结:Agent,Coding 与 AI infra
今年,尽管作者在博客上的文章明显减少,但这并不代表失去了表达的欲望,而是由于时间变得愈发宝贵。随着工作压力增加,作者将更多精力投入到健身和陪伴家人的时间上,尤其是在作者的爱人经历了健康问题和朋友的家庭不幸之后,深刻感受到了生活的无常。在恢复锻炼后,作者每周坚持5次训练,虽然体型变化不大,但整体健康和精力有了明显提升。
除了锻炼,学习LLM的新变化成为了作者最近的兴趣所在。相比过去,作者对这个领域感到更加兴奋,仿佛重新找回了大一时接触编程的那种新鲜感。特别是“Agent”概念的理解上,作者有了更清晰的看法。两年前,作者曾分享过Agent是AI未来发展的重要方向,这一观点至今仍成立。具体来说,LLM在与作者交互时,更多时候作者是希望它成为自己的执行者,而不是自己的老师。作者举了使用Poe与Claude的例子,说明在编程场景中,LLM帮助作者解决问题,但不能直接代替其执行代码的过程。
Agent与LLM结合的方式,是通过与环境交互不断学习和优化行为,以解决具体问题,而不是充当纯粹的“军师”。这种方式提高了自动化水平,也使得Agent成为未来发展的必然趋势。尤其在编程领域,GitHub Copilot的演进代表了Agent在coding场景中的应用。从最初的代码补全到现在的多文件修改,Agent的能力逐步提升,但真正的全自动化仍然距离我们较远,尤其是在代码审核和质量保证上,人的参与仍不可或缺。
在AI基础设施(AI Infra)方面,作者认为易用性已经不再是大多数场景下的核心问题。随着技术的发展,AI基础设施越来越以机器为中心,尤其是大模型训练和推理的规模已不再是小团队的考虑范围。如今,AI的核心需求是提高机器利用率,类似FlashInfer、PagedAttention、RadixAttention等工作聚焦于此。这一领域的发展让作者想起了Hadoop刚出现时,学术界的热烈反响和工业界的实际应用价值。
AI Infra领域逐步转向系统层面,易用性问题在训练和推理场景中显得不那么重要。然而,在低代码和无代码领域,易用性依然是最重要的。对于没有AI背景的普通用户,如何更轻松地使用AI工具仍是一个关键问题。比如Skypilot作为AI基础设施的创新尝试,旨在简化Kubernetes的使用,并通过提供更合理的UI/UX设计,为AI应用提供更加灵活的调度和管理
https://zhuanlan.zhihu.com/p/15161317229
LLM(卅一):序列并行的典型方案与实现细节
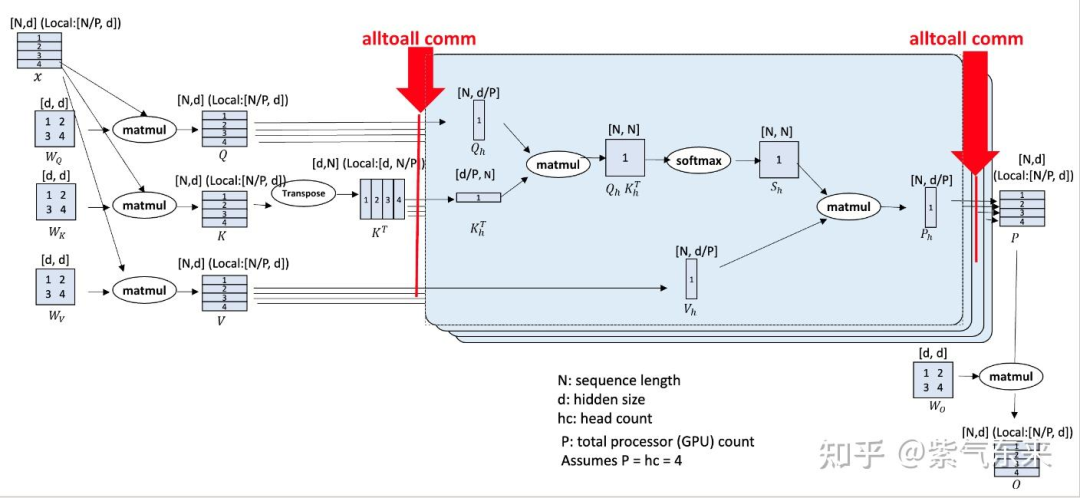
序列并行(Sequence Parallelism)是在长文本处理中的一种并行化策略,主要用于在序列维度进行切分,结合不同设备来提升效率。两种主流实现方式是Ring-Attention和DeepSpeed Ulysses,前者采用环形通信(Ring Communication)模式,后者则使用all2all通信模式。本文主要讨论这些方法的原理、实现细节以及它们的优缺点。
Ring-Attention的基本思想是将输入序列按设备数量分割,并通过环形通信将数据交换。最初的实现如ColossalAI的Sequence Parallelism和MegatronLM的Context Parallelism,采用了Allgather和Reduce-Scatter范式,将序列数据收集到所有设备,计算完成后再分发。这种方法的主要问题是计算和通信的开销较大,特别是在显存较大的情况下,可能导致性能瓶颈。
Ring-Attention在计算时利用迭代方式处理Softmax,采用LogSumExp(LSE)技术避免数值溢出,在空间尺度上分块计算,从而减少内存使用并优化计算效率。通过将Q、K、V拆分成不同的块并分配到多个设备,每个设备在不同时间段完成部分计算,最终通过更新LSE来汇总结果。尽管这种方法较为简单,但由于Allgather的聚合操作,它在显存上的占用仍然较大,限制了其在大规模模型中的应用。
Ring-Attention的优化之一是通信和计算的重叠。通过将通信时间与计算时间并行化,减少了通信带来的瓶颈。具体而言,可以通过设置CUDA_DEVICE_MAX_CONNECTIONS来确保计算和通信在GPU上并行执行,从而减少等待时间。此外,Stripe Attention和Zigzag Ring Attention是Ring-Attention的变体,它们通过重新划分计算任务,消除了负载不均衡的问题,提高了计算效率。
DeepSpeed Ulysses采用的是一种简单的全序列切分策略,使用all2all操作进行数据交换。每个GPU只处理序列的一部分,在计算前,首先进行一次all2all操作将序列划分到不同的注意力头上,计算后再进行一次all2all操作将结果汇聚。相比于Ring-Attention,Ulysses的优点在于它的all2all通信方式能够提供更高的通信效率,特别是在大规模分布式训练中。此外,Ulysses实现相对简单,不需要复杂的迭代计算或环形操作。
然而,Ulysses也存在一定的局限性,特别是在head大小较大的情况下。它的计算瓶颈通常出现在head数量较多时,因为每个GPU处理的序列长度较短,限制了计算的并行性。尽管如此,Ulysses仍然优于Ring-Attention,尤其是在需要处理超大规模模型时,其高效的通信机制和简洁的实现使得它在某些场景下成为更好的选择。
综上所述,Ring-Attention和DeepSpeed Ulysses各有优缺点。Ring-Attention适合于灵活的参数切分和对大规模模型的处理,但其较低的通信效率可能成为瓶颈。DeepSpeed Ulysses通过高效的all2all通信克服了这一问题,但其受限于head大小的约束。在实际应用中,可能需要结合这两种方法的优点,根据任务的特定需求进行选择和优化。
https://zhuanlan.zhihu.com/p/14665512019
使用float8和FSDP2加速大规模模型训练的技术进展
本文介绍了通过结合float8精度和FSDP2技术,提升大规模模型训练效率的最新实践。以Meta的LLaMa模型为例,文章展示了如何在不牺牲训练精度的情况下,显著提升训练吞吐量。文章的核心技术创新在于使用FSDP2、DTensor、torch.compile以及torchao的float8操作,使得训练过程更加高效,并能在多个GPU集群上稳定运行。
技术细节方面,float8精度的引入,由NVIDIA、ARM和Intel等技术公司推动,利用新一代GPU(如NVIDIA Hopper系列)的原生支持,实现了超过2倍的训练吞吐量提升。相比传统的bf16精度训练,float8精度不仅减少了存储需求,还在大规模模型训练中表现出了显著的性能优势。文章中展示的实验结果表明,使用float8精度的训练在多个模型规模(从1.8B到405B)中,均能保持与bf16训练相似的训练损失曲线,确保了模型的质量不受影响。
进一步的实验验证表明,float8训练在多个GPU集群环境下均能有效提高吞吐量,尤其在矩阵乘法和注意力机制等计算密集型任务中,float8精度展现了其巨大的性能潜力。此外,结合FSDP2框架和torchao的优化,使得大规模分布式训练可以高效进行,进一步推动了在浮动精度下的训练效率提升。
https://pytorch.org/blog/training-using-float8-fsdp2/
HuggingFace&Github
AI Agent创意团队
我们的故事是由专门的人工智能代理编写的,每个代理都有自己的角色:
SpecificationsAgent:分析故事需求并保持叙述一致性
ProductionAgent:生成内容并实施创意变更
ManagementAgent:协调代理之间并跟踪创意流程
ResearcherAgent:在线进行研究以确保世界构建的技术有效性
DeduplicationAgent:删除整个项目中的重复信息
RedundancyAgent:确保原创性并防止冗余
IntegrationAgent:确保小说的一致性
真正的人工智能自主:智能体积极协作并做出创造性决策,无需直接人工干预
实时开发:观看整个创作过程的展开,展示人工智能代理如何应对复杂的叙事挑战
哲学深度:通过全新的视角探索意识、伦理和人与人工智能的关系
https://github.com/Lesterpaintstheworld/terminal-velocity
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29166.html