我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
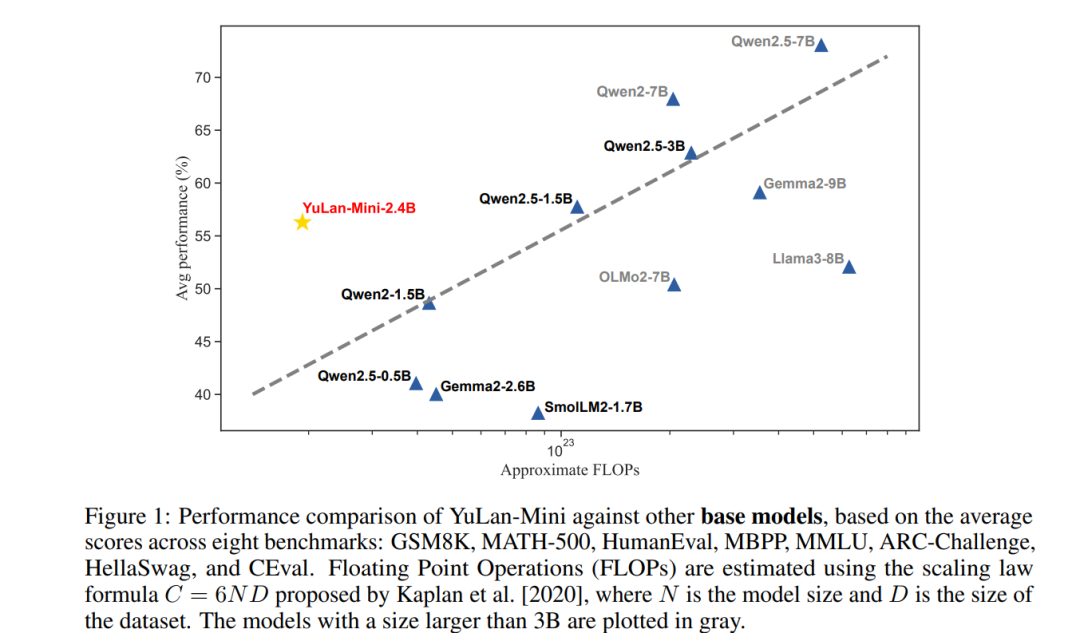
YuLan-Mini: An Open Data-efficient Language Model
近年来,大型语言模型(LLM)取得了显著的进展,成为人工智能领域的重要技术突破。与传统的专用机器学习方法不同,LLM能够在多个领域和任务中展现其作为通用模型的潜力。LLM的构建通常通过预训练和后训练相结合的方式,其中预训练被认为是建立语言模型基础能力的关键。针对基于Transformer架构的语言模型,当前普遍采用的预训练方法是对大规模未标注文本进行下一个词预测。然而,这种方法在实施过程中面临着诸多技术难题,包括数据处理管道的设计和训练过程中可能出现的优化问题,如梯度爆炸或损失波动,甚至可能导致训练失败。
尽管许多行业公司已经发布了大规模的模型检查点,然而其中的技术细节大多未公开,因此外界对高水平语言模型的训练过程知之甚少。为了解决这些问题,研究界已在开放数据资源和预训练方法的透明度方面做出了显著努力,部分公开了数据集和训练过程的文献。然而,开放的LLM模型在性能上通常不如行业对手,且由于计算资源的限制,复现这些模型往往需要相同数量的资源,难以在资源有限的学术环境中实施。因此,如何在有限的资源下开发具有竞争力的LLM仍然是一个挑战。
为此,本文提出了一种新的方法,旨在通过提升开放LLM的性能和训练效率,克服数据和计算资源的限制,推动LLM预训练的开放性。具体而言,研究集中在开发一个相对小型的语言模型,参数规模在1B到3B之间,且仅使用公开数据和有限的计算资源。本文介绍了一款具有2.42B参数的基准模型YuLan-Mini,该模型在同类规模的模型中取得了领先的性能。为提高训练效率,本文提出了三个主要的创新点:一是精心设计的数据处理管道,结合了数据清洗和数据调度策略;二是系统化的优化方法,有效减轻了训练不稳定性;三是有效的退火方法,结合了定向数据选择和长上下文训练。
在提升YuLan-Mini性能的过程中,本文还大量使用了合成数据,包括类似“o1”的长思考数据。此外,研究还探讨了多个可能导致训练不稳定的因素,并通过两个版本的检查点支持4K和28K上下文的训练。在一系列基准测试中,YuLan-Mini表现优异,尤其是28K版本,在MATH-500、HumanEval和MMLU等任务中取得了优异成绩,分别为37.80、64.00和49.10。
为了支持研究的可复现性,本文详细报告了YuLan-Mini的完整训练过程,并公开了训练阶段的数据组成。相关的资源可通过项目链接获取,以供进一步研究和复现。
https://arxiv.org/abs/2412.17743
ResearchFlow链接:https://rflow.ai/flow/33d49f1c-d930-48e4-96d0-a3a0d743a3a4
System-2 Mathematical Reasoning via Enriched Instruction Tuning
大型语言模型(LLM)被认为是实现通用人工智能(AGI)的重要突破,因为它们在多种智能活动中的潜力以及随着数据集、模型规模和计算预算的增加性能提升。然而,目前最强大的LLM,如GPT-4,仍然在处理基本数学问题时频繁出错,尤其是在涉及复杂数学推理时,这暴露了LLM在进行系统-2推理方面的不足。系统-2推理是较慢、较有逻辑的推理过程,通常用于解决复杂问题,而LLM目前大多依赖于下一词预测(类似于系统-1的直觉推理),在简单任务中表现良好,但在复杂任务中存在局限性。
针对这一问题,现有的研究可分为两类:基于微调的方法和基于提示的方法。基于微调的方法通过对LLM进行参数更新来提高其推理能力,但这类方法通常依赖于复杂的数据增强策略,可能导致性能难以归因且降低了模型的可扩展性。基于提示的方法则通过在上下文中引导LLM进行推理,但往往面临事实幻觉和错误传播的问题。
为了改善LLM的数学推理能力,本文提出了一种结合人类反馈(LHF)和AI反馈(LAIF)的方法,称为EIT(Enriched Instruction Tuning)。该方法通过人类和AI的协作,生成高质量的推理数据集,用于微调开源LLM。在这一方法中,首先通过人类反馈生成复杂数学问题的解答,然后利用LLM生成详细的推理计划和步骤,并通过AI反馈进一步补充推理过程中的遗漏部分,形成更为流畅的推理轨迹。
实验结果表明,EIT方法在MATH和GSM8K等数学基准测试中表现优异。EIT在MATH数据集上取得了32.5%的准确率,在GSM8K数据集上达到了84.1%的准确率,较MetaMath提高了2.7%。此外,EIT与使用外部工具的方法在GSM8K基准测试中的表现相当,甚至超越了MathCoder。这表明,细粒度的推理轨迹和数据的完整性同样对模型性能至关重要,为LLM的数学推理能力提升提供了新的见解。
https://arxiv.org/abs/2412.16964
ResearchFlow链接:https://rflow.ai/flow/515f9513-9adc-41e3-bbc3-cdb9b31e2f80
Token-Budget-Aware LLM Reasoning
推理在使大型语言模型(LLM)有效执行各类任务中起着至关重要的作用。为增强LLM的推理能力,已提出多种方法,其中链式推理(CoT)是最具代表性和广泛应用的方案。CoT通过引导LLM逐步分解问题并依次解决每个步骤,从而提高模型回答的可靠性。然而,尽管CoT显著提升了LLM的性能,它也带来了显著的额外开销,主要表现为生成的token数量增加。这种增加的token数量导致了计算资源的浪费,延长了推理时间,最终带来了较高的成本。
针对这一问题,本文提出了一种基于token预算的推理压缩方法,旨在减少CoT推理过程中的token成本。我们发现,通过在提示中加入token预算,限制token数量,能够有效压缩推理过程中生成的tokens。然而,token预算的选择在压缩效果中起着关键作用。例如,适当的token预算(如50个tokens)可以显著减少CoT推理的token数量,从258个减少至86个,同时保持推理结果的正确性。而当token预算设置过小(如10个tokens)时,LLM无法有效遵循预算,导致实际token消耗远超预算,甚至比较大的token预算下的token消耗还要多。这种现象被称为“token弹性”。
为了解决这一问题,本文提出了一种名为TALE(Token-Budget-Aware LLM rEasoning)的方法。TALE方法利用token预算来引导推理过程,根据问题的推理复杂性动态分配token预算。具体来说,TALE首先估算适当的token预算,然后通过该预算引导LLM进行推理。实验结果表明,TALE能够显著减少LLM链式推理中的token消耗,同时大幅保持答案的正确性。与传统方法相比,TALE平均减少了68.64%的token使用量,同时准确性仅下降了不到5%。这一结果表明,TALE方法有效解决了LLM推理过程中高token成本的问题,并为推理过程的高效性提供了新的思路。
https://arxiv.org/abs/2412.18547
ResearchFlow链接:https://rflow.ai/flow/a79792ff-e4cf-454b-8bba-e2dad8add3df
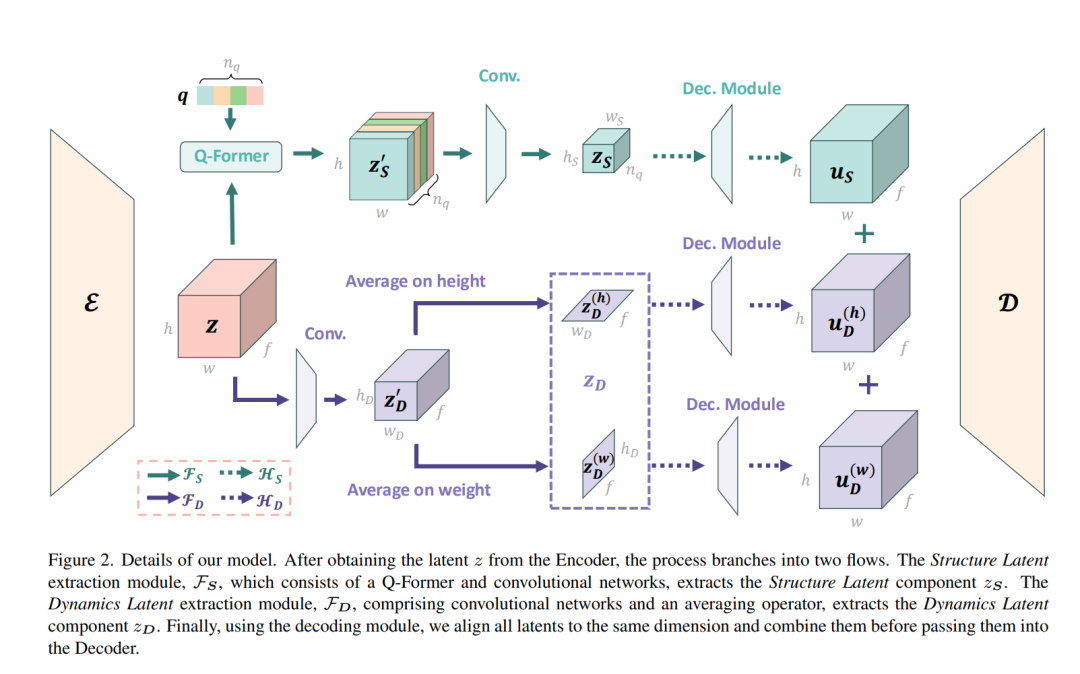
VidTwin: Video VAE with Decoupled Structure and Dynamics
近年来,潜在扩散模型(Latent Diffusion Model)在文本到图像生成领域取得了显著进展,代表性模型如Stable Diffusion系列。在这一框架中,图像自编码器通过将图像编码为紧凑的潜在空间,减轻了建模复杂度,提高了扩散模型的训练效率。近期,研究者们尝试将这一思路应用于视频潜在表示和生成任务,但由于视频比静态图像多了时间一致性,如何将视觉内容和时间依赖关系同时映射到潜在空间成为了一个难题。
以往的工作在将视频转换为潜在表示时,主要有两种设计理念。第一种是传统方法,将每一帧(或一组帧)表示为相同大小的潜在向量或token。这种方法简单,但忽视了帧之间的冗余,视频具有连续性,相邻帧的内容变化通常较小,具有很大的压缩潜力。第二种方法通过将表示分为两种类型来解决这一问题,即使用单个或少量内容帧与多个运动潜在向量,但这些方法过于简化了视频内容的动态特性,导致生成效果不佳,如出现模糊的帧。
为解决这些问题,本文提出了一种新方法,通过将视频编码为两个不同的潜在空间来有效捕捉视频的内容与动态:结构潜在空间(Structure Latent)表示全局内容与运动,而动态潜在空间(Dynamics Latent)捕捉细粒度的细节与快速运动。例如,在拧螺丝的视频中,桌面和螺丝等主要语义内容属于结构潜在空间,而颜色、纹理及螺丝的下移与旋转等快速局部运动则属于动态潜在空间。通过将这两部分潜在表示组合,能够重建出高质量的视频。
我们提出的VidTwin模型旨在有效学习这些相互依赖的潜在表示,克服了先前方法忽视动态内容的问题,能够在高压缩率的情况下保持视频重建质量。具体而言,我们采用空间-时间变换器(Spatial-Temporal Transformer)作为视频自编码器的骨干,并引入两个子模块分别提取结构潜在表示和动态潜在表示。结构潜在表示通过Q-Former架构提取时间维度的低频运动趋势,并进一步在空间维度下采样以去除冗余细节。动态潜在表示则通过对编码器获得的潜在向量进行空间下采样并沿高宽维度进行平均来进一步降低维度。此外,我们设计了一种机制,将这些潜在表示适配到扩散模型中,通过对这两种潜在向量进行patch化并拼接,作为扩散模型的训练目标。
实验结果表明,VidTwin模型在多个方面表现优异:首先,VidTwin通过解耦设计和紧凑的潜在表示,达到了约500倍的压缩率,同时保持了高质量的重建效果,从而显著减轻了下游模型在处理高维视频数据时的内存和计算负担;其次,在下游任务中的有效性也得到了验证,特别是在生成任务中,VidTwin在UCF-101数据集上的表现与一些经典模型相当,展现了较强的适应性;最后,VidTwin的潜在空间设计具有可解释性和可扩展性,这为进一步的研究和改进提供了机会。
总之,本文的主要贡献有:提出了一种新的视频编码基础模型VidTwin,采用解耦设计有效地将视频表示为结构和动态两部分;VidTwin实现了高压缩率和强重建能力,并在生成模型中得到了验证;强调了视频潜在表示在当前研究趋势中的重要性,期望VidTwin能够为相关领域的研究提供启示和帮助。
https://arxiv.org/abs/2412.17726
ResearchFlow链接:https://rflow.ai/flow/d4842896-5e95-4e66-a85e-056da7f48846
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29148.html