我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
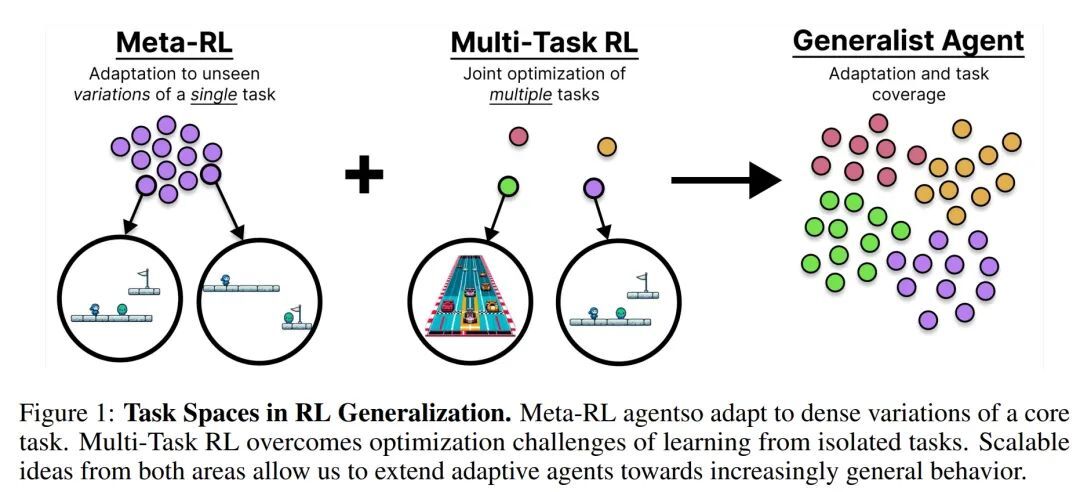
AMAGO-2: Breaking the Multi-Task Barrier in Meta-Reinforcement Learning with Transformers
这篇文章探讨了“多任务障碍”,并说明诸如值分类等抗规模损失函数有助于修复它,而无需任何新的假设。强化学习可以通过借用序列建模的细节来改进,而不需要将强化学习变成监督学习。有一种RL 技巧可以将 Q 学习转化为分类,还可以快速解决多任务强化学习最不必要的问题:每个任务的训练损失的规模随着时间的推移而变化不均匀。这种情况发生在监督学习中会很奇怪,而损失函数的改变可以在强化学习中修补它。多任务强化学习有更好的解决方案,但上下文适应需要修正,因为它最适合解决的问题涉及太多任务。我们会训练一个序列模型,以适应之前的尝试的记忆。这里的实验陷入了狭窄的领域。我们需要更多任务来泛化。
https://x.com/__jakegrigsby__/status/1866987546355601875
学术报告链接:https://arxiv.org/abs/2411.11188
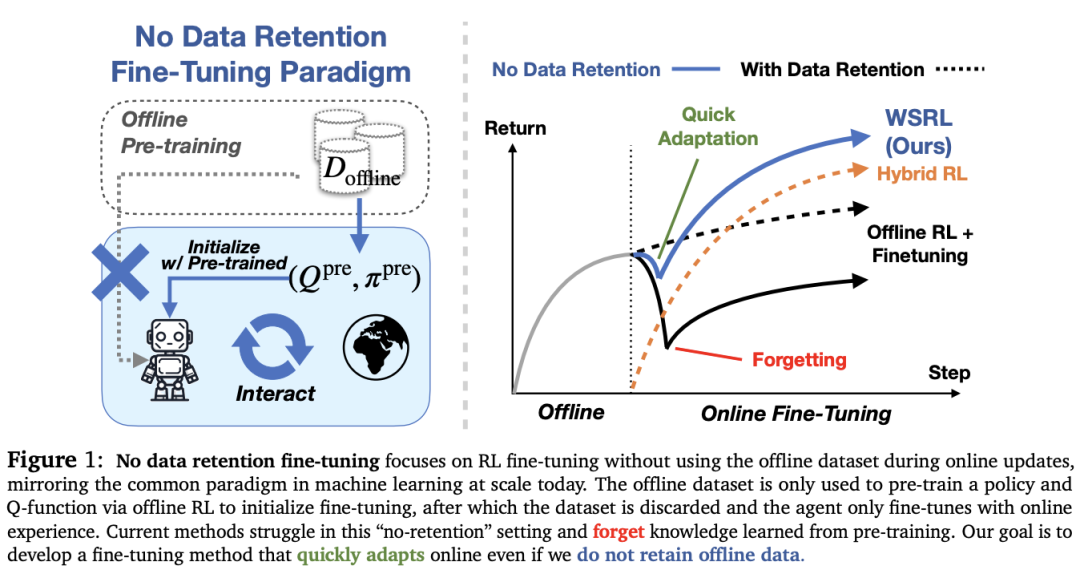
Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data
本篇论文研究没有离线数据保留的 RL 在线微调,称之为无保留微调的范式。论文对现有的离线到在线 RL 进行了详细分析方法并发现在微调过程中经常需要离线数据来减轻 Q 值发散以及由于分布偏移而导致的遗忘,而且也会逐渐减慢微调速度。论文演示一种结合预热阶段来初始化重放缓冲区的简单方法从预训练的离线强化学习策略进行少量转换,然后运行简单的在线强化学习该算法可以有效地进行样本高效的微调,而不会忘记预先训练的初始化。
学术报告链接:https://arxiv.org/abs/2412.07762v1
Mobile-TeleVision: Predictive Motion Priors for Humanoid Whole-Body Control
论文引入了 PMP(预测运动先验),使用条件变分自动编码器 (CVAE) 进行训练,以有效地表示上半身运动。运动策略是根据这种上半身运动表示进行训练的,确保系统在操作和运动方面都保持稳健。CVAE 特征对于稳定性和稳健性至关重要,并且在精确操作方面明显优于基于 RL 的全身控制。通过精确的上半身运动和强大的下半身运动控制,操作员可以远程控制人形机器人四处走动并探索不同的环境,同时执行各种操作任务。
学术报告链接:https://arxiv.org/abs/2412.07773v1
FiVA: Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
论文提出了一个全面的细粒度视觉属性数据集,其特征精心描绘各种视觉属性的图像。在注释现实世界图像时,论文建议利用先进的 2D 生成模型用于数据收集的自动数据生成管道。论文开发了一种系统方法,包括属性和主题定义、提示创建、基于 LLM 的过滤和人工验证构建一个数据集,在大约 1 M 幅图像中标注有不同的视觉属性。每张图片可以进一步分为由不同种子生成的 2×2 子图像,可用于采样期间训练。在此数据集的基础上,论文引入了细粒度的视觉属性适应框架旨在控制生成过程中的细粒度视觉属性。具体来说,论文建议将多模态编码器 Q-former 集成到图像特征编码器中在插入交叉注意模块之前。这种集成有助于理解标签或提取图像信息的简要说明。
学术报告链接:https://arxiv.org/abs/2412.07674v1
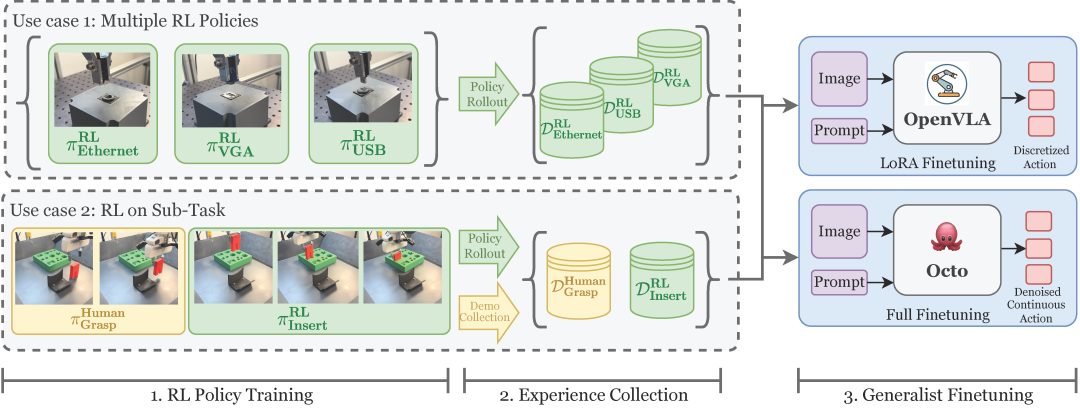
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
RLDG 是一个将专业 RL 策略提炼为通用机器人策略的框架。通过这种方式训练的通用机器人比使用人类演示的传统微调方法表现出更高的性能,并且比提炼出来的 RL 策略具有更强的泛化能力。
学术报告链接:https://generalist-distillation.github.io/
HuggingFace&Github
GPUStack 开源 GPU 集群管理器
-
GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。
-
主要特点:广泛的硬件兼容性:可在 Apple MacBook、Windows PC 和 Linux 服务器中运行不同品牌的 GPU。
-
广泛的模型支持:从 LLM 和扩散模型到音频、嵌入和重新排序模型。
-
随着您的 GPU 库存进行扩展:轻松添加更多 GPU 或节点来扩大您的操作。
-
分布式推理:支持单节点多 GPU 和多节点推理和服务。
-
多推理后端:支持 llama-box(llama.cpp)和 vLLM 作为推理后端。
-
轻量级 Python 包:最小的依赖性和操作开销。
-
与 OpenAI 兼容的 API:提供与 OpenAI 标准兼容的 API。
-
用户和 API 密钥管理:简化用户和 API 密钥的管理。
-
GPU 指标监控:实时监控 GPU 性能和利用率。
-
令牌使用情况和速率指标:跟踪令牌使用情况并有效管理速率限制。

https://github.com/gpustack/gpustack
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/25717.html