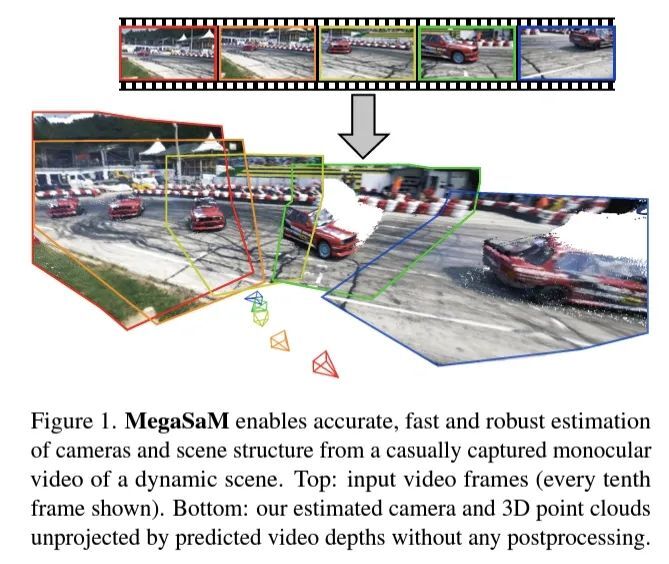
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
我们提出了一个系统,该系统可以从动态场景的随意单目视频中准确、快速、稳健地估计相机参数和深度图。大多数传统的运动结构和单目 SLAM 技术都假设输入视频以具有大量视差的静态场景为主。在没有这些条件的情况下,这种方法往往会产生错误的估计。最近的基于神经网络的方法试图克服这些挑战;然而,当在具有不受控制的相机运动或未知视野的动态视频上运行时,这种方法要么计算成本高,要么很脆弱。我们展示了深度视觉 SLAM 框架的惊人有效性:通过对其训练和推理方案进行仔细修改,该系统可以扩展到具有不受约束的相机路径的复杂动态场景的真实世界视频,包括具有很小相机视差的视频。对合成视频和真实视频进行的大量实验表明,与之前和并发工作相比,我们的系统在相机姿势和深度估计方面明显更准确、更稳健,运行时间更快或相当。https://arxiv.org/abs/2412.04463 推荐阅读 — END —1. The theory of LLMs|朱泽园ICML演讲整理