我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


资讯
奇绩创坛 2024 秋季路演日,多模态、数据、具身、仿真等 60 家前沿创业项目
2024年秋季,奇绩创坛在北京中关村国际创新中心举办了创业营路演日,60家受奇绩投资并加速的公司参与。这些公司主要集中在大模型(49家)、多模态(28家)、数据(24家)、具身智能(14家)和仿真(4家)等领域。创始人平均年龄29岁,64%拥有硕士及以上学历,12%为女性。录取率为1%。
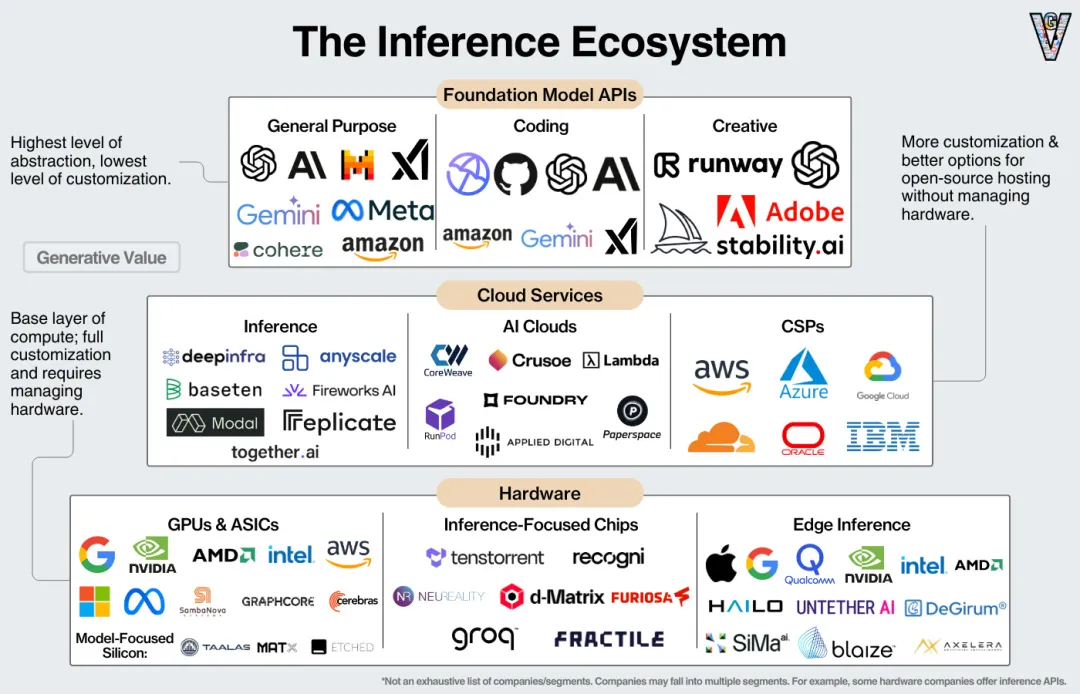
生成式AI推理技术、市场与未来
OpenAI的o1、QwQ-32B-Preview和DeepSeek R1-Lite-Preview的发布标志着生成式AI研究的重心从预训练转向推理(Inference)。推理作为AI的逻辑推理能力的体现,将推动上层应用的进展,成为AI发展的下一个阶段。随着推理技术的逐步成熟,AI在企业应用中的角色愈加重要。红杉资本预测,推理的计算能力将在未来成为核心竞争力,这也为AI推理市场的迅速崛起提供了基础。
推理市场的发展受益于计算成本的降低和行业竞争的激烈。推理与传统的训练工作流有显著差异,推理是将新数据输入已训练的模型以进行预测,要求快速响应和高效处理,因此推理通常是在边缘计算或边缘云环境中进行。这一过程具有较低的硬件要求,且系统互依性较小,因此新兴半导体公司能够在此领域迅速崛起。
推理市场的竞争格局复杂,各类企业提供不同的推理服务。最简单的是基础模型API,企业通过调用OpenAI等提供的API实现推理,但灵活性较低。推理服务提供商,如Fireworks AI和DeepInfra,专注于跨云平台优化推理服务,帮助企业定制和运行开源模型。AI云服务提供商则通过GPU和推理即服务(Inference-as-a-Service)提供更强大的计算能力,而硬件供应商如Nvidia和AMD也在推理硬件领域不断加码,以提高推理性能和系统优化能力。
推理的市场参与者不仅限于云服务商,还包括硬件厂商和初创公司。Nvidia通过收购推理服务公司OctoAI进一步巩固其市场地位,而像Cerebras、Groq等公司则通过提供专门的推理硬件,占领了推理计算的高地。推理服务的选择主要基于成本、性能和延迟的综合考量。特别是在边缘推理领域,随着模型的轻量化和硬件的进步,推理将不再依赖中心化计算,而是转向边缘设备运行,从而减少企业的资本和运营支出,同时让消费者享受更高效的本地推理服务。
推理市场的未来将由AI应用的规模和复杂度决定。如果大公司如OpenAI、Google等主导市场,推理价值将向这些垂直整合公司集中,硬件需求也将集中在其底层硬件上。若AI市场碎片化,小型公司将推动推理服务的多样化,提供更多定制化选项。随着边缘计算的发展,轻量化AI模型将在边缘设备上运行,推理硬件将逐步走向大众化,推动整个行业向去中心化和分布式计算转型。这些变化将引发AI推理市场的不断演化,未来的推理技术将趋向更加智能化和高效化。
AI 驱动的纯数学和理论物理研究:自上而下、自下而上和元数学
在过去的五年中,人工智能(AI)在纯数学和理论物理领域的应用取得了显著进展,尤其在自动定理证明、机器辅助推理以及大型语言模型(LLMs)方面的研究。这些进展表明,尽管AI可能不会完全取代数学家,但它在推动理论科学研究中的作用日益重要。文章提出了三种数学和理论物理的AI驱动研究方式:自下而上的自动定理证明、自上而下的机器辅助直觉和基于元数学的大型语言模型。
自下而上的方法强调从最基本的公理出发构建数学体系。现代自动定理证明(ATP)技术正是对这一传统方法的现代化回应,借助计算机的力量解决了许多复杂的数学问题,如四色定理和群分类。尽管如此,完备的数学知识库和自动定理证明的普及仍需时间。元数学则通过分析已存在的数学论文和研究,帮助识别学科间的规律。大型语言模型在这一领域的应用,特别是通过自然语言处理(NLP)技术,能够识别和理解不同数学领域的差异性。例如,Word2Vec技术展示了其在区分主流和非主流科学思想中的潜力。随着LLMs的快速发展,DeepMind的AlphaGeo成功地生成了欧几里得几何中的证明,进一步推动了这一技术的应用。
自上而下的数学方法则侧重于从经验和直觉出发提出猜想,再进行正式的证明。许多重要的数学发现都是基于这种灵感驱动的方式,例如牛顿和欧拉在微积分领域的工作。AI在此方法中的应用,尤其是在模式识别和直觉形成方面,已展现出潜力。例如,AI系统在数列预测中的表现优异,能够迅速识别出潜在的数学模式和规律。
尽管AI在数学研究中表现出强大的潜力,但如何评估AI驱动的数学发现仍然是一个挑战。文章提出了“Brich测试”标准,要求AI发现必须满足自动性、可解释性和非平凡性三个条件。尽管当前的AI辅助发现有时无法完全满足这些标准,但通过深度学习技术和模型改进,AI在一些数学问题上的贡献正变得日益显著。
诺奖得主辛顿最新演讲:数字智能比生物智能效率高10万倍,但进化方向不同,成名研究成果归功于博士弟子天团
深度学习的成功依赖于优秀的研究生: 辛顿强调其研究成果很大程度上归功于他招募的优秀博士生。
对人工智能的担忧: 辛顿表达了对人工智能快速发展的担忧,尤其关注其潜在的生存威胁,认为目前的恐惧程度远远不够。他以2006年其深度学习论文被NIPS拒稿为例,说明当时人们对神经网络的兴趣低迷,如今却面临着相反的极端。
模拟神经网络的潜力与挑战: 辛顿探讨了模拟神经网络相较于数字计算的优势(低功耗、廉价的硬件),以及其面临的挑战(反向传播的困难、知识转移的低效)。他认为,模拟计算可能通过生物学方法(基因改造技术)实现。
大型语言模型的理解能力: 辛顿认为大型语言模型并非简单的自动补全工具,它们能够理解所表达的内容,并举了GPT-4解答复杂谜题的例子。他指出,人类记忆也存在“幻觉”,与大型语言模型偶尔出现错误的情况类似。
知识转移的机制: 辛顿解释了知识在大型语言模型和人类大脑中转移的机制,特别是通过多个副本共享梯度更新实现高效知识共享。他认为大型语言模型知识量巨大的原因在于此,而非仅仅是数据量的优势。
人类理解机制与大型语言模型的相似性: 辛顿认为大型语言模型的理解方式与人类相似,都基于对单词含义的特征向量及其相互作用的学习。他反驳了将大型语言模型与人类理解方式完全区分开来的观点。
人工智能的潜在风险: 辛顿强调了人工智能的潜在风险,包括被恶意行为者利用以及超级人工智能自身可能产生的威胁(争夺资源、控制权)。他呼吁不要开源大型模型。
主观体验的本质: 辛顿对“主观体验”进行了重新定义,认为它并非神秘的内部事物,而是对现实世界假设状态的描述,用以解释感知系统的输出。他认为多模态聊天机器人也可能拥有主观体验。
人工智能发展速度的不可逆转性: 辛顿认为无法有效减缓人工智能的发展速度,更重要的是研究如何使其良性发展,应对潜在风险。
机器学习硬件市场: 辛顿对英伟达在机器学习硬件市场的主导地位并不担忧,认为竞争最终会到来。
美欧亚三洲开发者联手,全球首个组团训练的大模型
Prime Intellect 在 11 月 22 日宣布完成了首个去中心化训练的 10B 模型——INTELLECT-1,并于 30 日开源了包括基础模型、检查点、后训练模型、数据、PRIME 训练框架等技术资源。这一成果展示了去中心化、大规模 AI 模型训练的可行性,为未来的开源 AGI(人工通用智能)奠定了基础。
INTELLECT-1 基于 Llama-3 架构,采用了 42 层、隐藏维度 4096、32 个注意力头和序列长度 8192。训练数据集包含 1 万亿个 token,数据来源包括 FineWeb-Edu、Stack Overflow、FineWeb、DCLM-baseline 和 OpenWebMath 等多个领域。模型训练持续了 42 天,并使用了 WSD 动态调整学习率、精细调教学习参数、max-z-loss 稳定性损失函数和 Nesterov 动量优化算法等技术,以确保高效学习。
该模型的训练涉及 3 个大洲、5 个国家,使用了 112 台 H100 GPU,计算资源的利用率高达 83%,美国本土部署时甚至达到了 96%。Prime Intellect 提出了一个去中心化训练框架 PRIME,基于 OpenDiLoCo(DeepMind 的 DiLoCo)算法,优化了计算带宽,采用了伪梯度的 int8 量化和外部优化器同步,成功将带宽需求降低了 2000 倍。此外,PRIME 还支持容错训练、动态资源管理以及优化全球分布式 GPU 网络中的通信和路由。
PRIME 训练框架包含多个关键特性,如 ElasticDeviceMesh(用于容错训练)、异步分布式检查点、实时恢复、自定义 Int8 All-Reduce 内核等,能最大化带宽利用率,并通过 PyTorch FSDP2 和 DTensor ZeRO-3 提升计算效率。在不同地理位置的节点部署下,计算效率仍能维持在高水平,如美国境内集群的同步延迟仅为 103 秒,全球分布式节点下也能保持 83% 的计算效率。
训练完成后,Prime Intellect 与 Arcee AI 合作进行了后训练,包括 16 轮的监督微调(SFT)、8 轮的直接偏好优化(DPO)以及 MergeKit 整合训练成果,进一步提升了模型性能和任务特定能力。
Prime Intellect 的目标是将去中心化训练框架推广至更大规模,最终实现开源 AGI。为此,他们计划继续扩大全球计算网络,激励更多社区参与,并进一步优化 PRIME 框架以支持更大规模的模型。
总之,INTELLECT-1 的发布展示了去中心化、大规模训练的巨大潜力,推动了开源 AI 发展的前沿,并为未来的 AGI 研究提供了有价值的参考。
https://mp.weixin.qq.com/s/L5RLnPGvE9IcEXmhLen8qg
推特
00Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
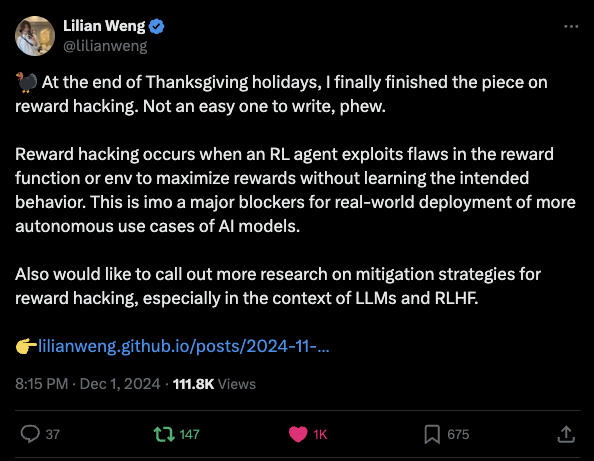
Lilian Weng分享Reward Hacking文章:这会是AI 模型更广泛应用于现实世界中更自主的场景时的一个主要障碍
🦃 在感恩节假期的最后,我终于完成了关于Reward Hacking的文章。这可真不容易写,呼。
Reward Hacking是指强化学习(RL)代理通过利用奖励函数或环境中的漏洞来最大化奖励,而不学习预期行为的现象。在我看来,这种问题是 AI 模型更广泛应用于现实世界中更自主的场景时的一个主要障碍。
同时,我也希望能有更多关于奖励黑客的缓解策略的研究,特别是在大语言模型(LLMs)和基于人类反馈的强化学习(RLHF)的背景下。
👉 https://lilianweng.github.io/posts/2024-11-28-reward-hacking/
https://x.com/lilianweng/status/1863436864411341112
Ravenwolf分享基准测试发现:将 max_tokens 从默认的 2K 提高到 8K 后,小模型的量化版本得分显著提升
基准测试快完成了,明天会发布详细报告,但想马上分享一些重要发现:测试了 @Alibaba_Qwen 的 QwQ,从 3-bit 到 8-bit EXL2 在 MMLU-Pro 上的表现。将 max_tokens 从默认的 2K 提高到 8K 后,小模型的量化版本得分显著提升。它们需要更多空间来“思考”!
https://x.com/WolframRvnwlf/status/1863331342479438175
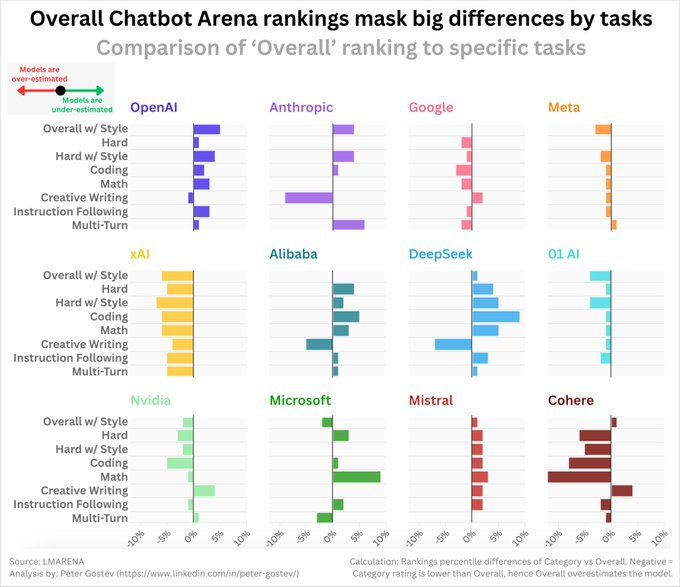
Chatbot Arena视觉化:同一模型不同任务的巨大区别
对比 @lmarena_ai 上“整体”(Overall)排名与“类别”(Category)排名。向左的条形图(负值)表示“整体”评分高估了该类别的排名,而向右的条形图(正值)表示“整体”评分低估了该类别的排名。
例如,在创意写作(Creative Writing)类别中,Anthropic 模型的排名低于其“整体”评分中的排名——老实说,没想到会这样。而 OpenAI、DeepSeek、Qwen 模型在这一指标上的表现不错,xAI 的表现则不太理想。
https://x.com/amebagpt/status/1863325620433715320
Karpathy分享表情包:图灵测试的现实
https://x.com/karpathy/status/1863284668159980007
产品
Muku.ai
Muku.ai 是全球首个 AI 网红代理机构,致力于快速、经济地生成高质量的用户生成内容(UGC)视频,用户只需提供产品链接即可。该平台大幅提高广告创作效率,节省成本,并允许用户定制虚拟代言人,以适应不同品牌形象和需求。
DataFuel.dev
DataFuel.dev 是一个 API,能够将整个网站转化为适合大型语言模型(LLM)的数据,只需一条查询即可,无需复杂的抓取代码或代理。该工具提供干净的 Markdown 格式数据,便于检索增强生成(RAG)系统使用,支持从登录页面抓取数据,并可输出 JSON 格式。
https://www.datafuel.dev/
投融资
双深科技获富瀚微数千万战略融资
双深科技,成立于2020年,专注于用AI技术颠覆传统的图像和视频压缩与处理领域。近期,双深科技获得了来自上市公司富瀚微的数千万人民币战略投资,进一步推动其技术创新和全球市场拓展。富瀚微是一家在视频监控领域具有深厚积淀的集成电路设计公司,致力于推动智能视频处理芯片的研发。此次战略投资不仅为双深科技提供了强力支持,也彰显了市场对其在AI赋能编解码技术和智能视觉领域应用的高度认可。
双深科技凭借在AI编解码领域的创新突破,已为航天、视频监控、互联网等多个行业提供完整的技术解决方案。其自研的AI Codec、AI Vision Codec+和AI ISP等算法,在压缩效率和质量上实现显著突破,较传统H.266压缩标准提升了30%。此外,双深科技还与中科大共建了“科大先研院-双深视觉智能联合实验室”,推动视觉智能技术的发展,并将其技术打造成IEEE1857.11标准,加速图像压缩格式的国际落地。
随着5G、物联网等新兴技术的广泛应用,智能视觉技术的需求正在迅速增长。双深科技与小红书等行业巨头的战略合作,使其在智能视觉和编解码领域的产业化应用得以加速。富瀚微的投资将推动双深科技在技术革新和市场扩展方面的突破,特别是在智能视觉、编解码技术、低功耗解决方案等方面的深度融合。
双深科技的最新研发成果包括“瞬析多模态大模型”,该模型将视频语义理解与自然语言处理结合,推动了“文生图”“图生图”等智能功能的实现。同时,公司还在图像和视频编解码的轻量化技术上取得了突破,优化了算法,增强了在移动设备和中低端硬件上的适配性。这些创新为智能设备、遥感图像传输等应用场景提供了高效的技术支持。
此次融资不仅证明了市场对双深科技技术潜力的高度认可,也为其在全球市场的拓展提供了有力支持。富瀚微将利用其丰富的资源和技术优势,帮助双深科技进一步推动AI算法与芯片级解决方案的深度整合,并加速产业化进程。未来,双深科技将在智能视觉领域持续创新,并通过技术研发、行业合作等多元化手段,扩大其在全球市场的影响力。
公司官网:https://www.attrsense.com/

https://36kr.com/p/3055698575675524
— END —
快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/24223.html