我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
行云季宇:谁困住了 AI 产业—— 大型机化的计算机形态与变革的可能性 | 奇绩潜空间活动报名 【奇绩潜空间】 是 GenAI 时代冲得最快的一批科研学者/从业者/创业者聚集的 AI 人才社 区,潜空间定期邀请大模型前沿创业者分享产品实践探索,邀请前沿科研学者分享最新技术进展。
第五季第二期潜空间邀请到的嘉宾是行云创始人兼 CEO —— 季宇 ,在本次活动中季宇将在北京现场与大家面对面交流,他分享的主题是《谁困住了 AI 产业——大型机化的计算机形态与变革的可能性。
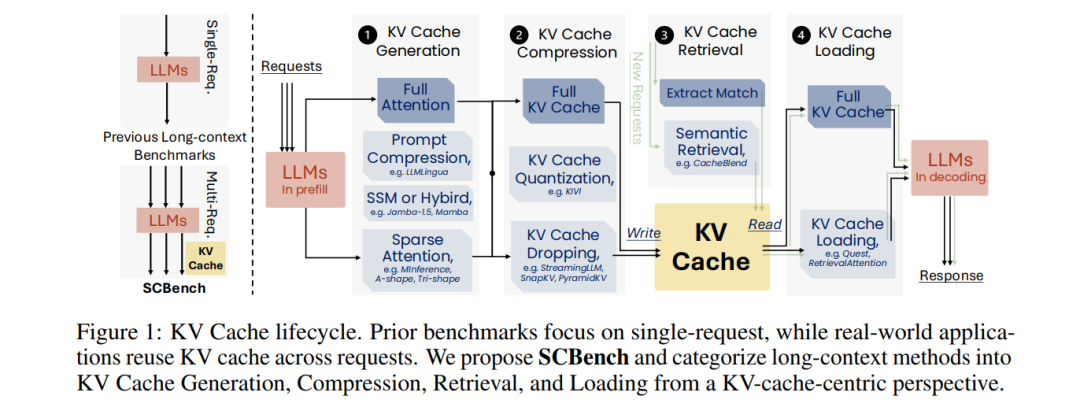
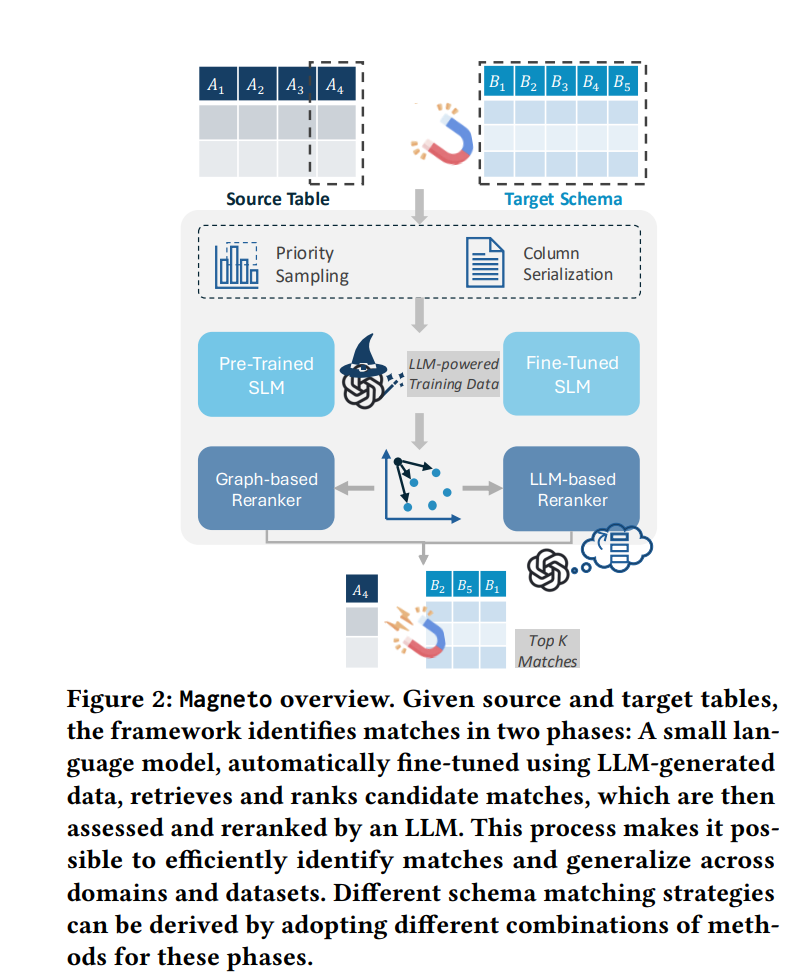
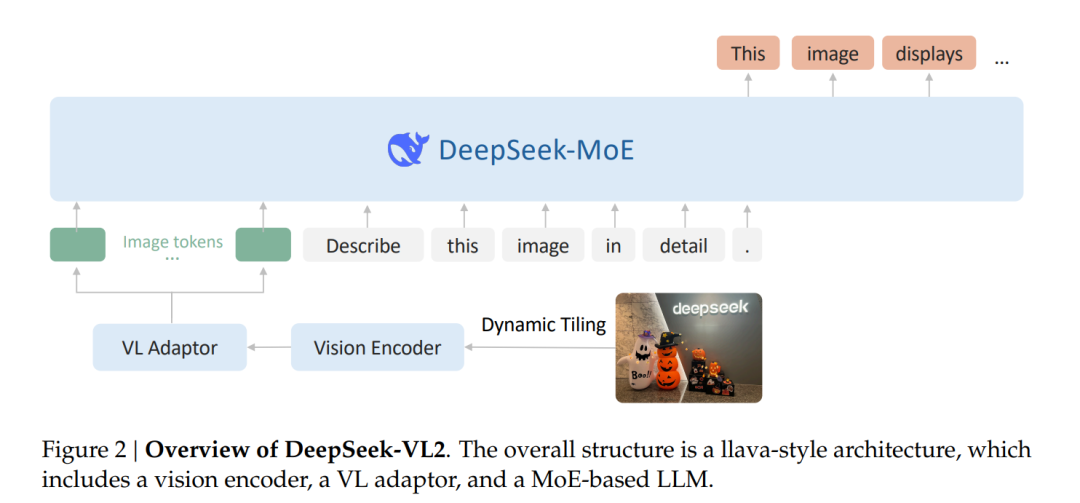
信号 SCBench: A KV Cache-Centric Analysis of Long-Context Methods 本文提出了一个新的基准测试平台SCBench,用于评估长上下文方法在多轮交互和多请求场景中的表现,特别是在共享上下文和KV缓存重用的实际应用中。传统的长上下文方法多集中在单请求基准测试上,而SCBench能够涵盖KV缓存生命周期的完整过程,从KV缓存的生成、压缩、检索到加载,填补了现有评估的空白。长上下文模型(LLMs)在处理长输入时面临计算成本和内存需求的挑战,因此,开发了多种高效的长上下文方法,这些方法通过利用KV缓存中的稀疏性来降低内存和计算开销。 本文首先从KV缓存的四个关键阶段进行分析:1)KV缓存生成,即预填充阶段,提出了稀疏注意力方法以降低注意力操作的复杂性;2)KV缓存压缩,采用剪枝技术减少内存消耗;3)KV缓存检索,通过跳过生成阶段直接从历史缓存中检索来提高推理效率;4)KV缓存加载,通过逐步加载缓存部分来节省内存和计算资源。虽然这些方法在单请求场景下取得了一定成果,但它们未能涵盖多轮交互和多个请求的长上下文应用,尤其是涉及到KV缓存的重用和前缀缓存的问题。 SCBench通过设计12个任务并涵盖四种长上下文能力,提供了全面的评估标准。这四种能力包括:1)字符串检索能力,测评模型从长输入中准确检索相关上下文的能力;2)语义检索能力,评估模型理解长文本语义并进行有效检索的能力;3)全局信息能力,测量模型处理和聚合全局信息的能力,如多次上下文学习、摘要生成和长数组统计;4)多任务能力,测试模型在共享上下文下执行多任务的能力。此外,SCBench还设计了两种共享上下文模式:多轮模式和多请求模式,以便测试长上下文模型如何在不同类型的交互中重用缓存。 通过对13种长上下文方法(包括新提出的Tri-shape稀疏注意力方法)在8个开源LLM上的评估,本文的实验揭示了几个重要发现:1)在多轮解码中,使用次O(n)内存的稀疏解码方法在首轮表现良好,但随后的请求中准确度下降;相比之下,O(n)内存的稀疏编码方法能够在多个查询中接近全注意力的表现;2)任务性能的下降趋势因任务类型而异,稀疏KV缓存方法在需要全局信息的任务中表现更好,而O(n)内存则对精确匹配的检索任务至关重要;3)在压缩率降低时,所有长上下文方法都会出现性能下降,但像RetrievalAttention和KIVI这样保持O(n)内存的稀疏解码方法在高压缩率下仍能维持较高的性能;4)长生成任务面临分布偏移问题,随着生成长度和轮次的增加,KV缓存的重要性分布发生显著变化,导致即便是O(n)内存的方法在扩展任务中也会出现性能下降。 总之,本文的创新贡献在于:提出了一个新的长上下文方法评估基准SCBench,涵盖了多轮和多请求的场景,提供了更具现实意义的评估;设计了一系列下游任务,全面评估长上下文能力;并从KV缓存的视角系统分类和评估了多种长上下文方法,揭示了稀疏性在编码和解码过程中的作用及任务复杂度等方面的重要见解。 https://arxiv.org/abs/2412.10319 Magneto: Combining Small and Large Language Models for Schema Matching 随着结构化数据量的快速增长,来自科学文献、公共政府数据门户等多个来源的数据需要进行集成,以回答复杂问题。然而,现有的模式匹配方法(Schema Matching,SM)依然面临显著挑战,尤其是在数据异构性和属性表示差异较大的情况下。例如,生物医学领域中的蛋白基因组学数据集在进行集成时,常因数据源中变量命名和取值的不一致而需要耗费大量人工来进行手动匹配。尽管在此领域已有一些解决方案,但这些方法普遍面临准确性不足、计算资源需求高的问题。 本论文提出了一个新的框架——Magneto,旨在通过结合小型预训练语言模型(SLM)和大型语言模型(LLM)来解决模式匹配中的问题,尤其是在高效性和准确性之间取得平衡。Magneto框架采用了两阶段策略:候选匹配的检索阶段使用SLM,之后通过LLM进行排序优化。该方法不仅减少了高成本LLM的调用频次,还通过一种自动化的过程来生成用于微调SLM的训练数据,从而避免了手动标注数据的高昂成本。 针对LLM模型的上下文窗口限制和计算成本问题,Magneto通过两阶段处理降低了成本和延迟,并通过合适的序列化和采样策略确保了大规模数据集的处理能力。此外,论文还提出了一种基于对比学习的微调管道,通过三元组损失和在线三元组挖掘提高了列嵌入的区分能力,从而提升了模式匹配的效果。 通过在两个数据集基准上进行广泛的实验,Magneto的表现优于现有的模式匹配方法,尤其是在处理生物医学数据集时,能够显著提高匹配的准确性并减少运行时间。Magneto展示了将SLM和LLM结合使用的潜力,尤其在没有事先训练数据的情况下,也能提供高效且准确的解决方案。实验结果表明,Magneto在各种领域的数据集上均表现出色,并且为生物医学领域提供了一个新的、具有挑战性的基准,推动了该领域模式匹配技术的发展。 论文的贡献包括:提出了Magneto框架,结合SLM和LLM提高模式匹配效率;提出了一种基于LLM自动生成训练数据来微调SLM的方法;通过SLM候选检索和LLM重排的结合实现了高准确度和低成本的模式匹配;并通过广泛的实验验证了该方法的有效性。 https://arxiv.org/abs/2412.08194 DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understandin DeepSeek-VL2 是一种先进的大型 Mixture-of-Experts (MoE) 视觉-语言模型,较其前身 DeepSeek-VL 通过两个主要升级显著提升了性能和效率。首先,在视觉组件方面,DeepSeek-VL2 采用了一种动态拼接视觉编码策略,能够处理不同纵横比的高分辨率图像。这种方法避免了 DeepSeek-VL 中固定分辨率编码器的局限性,能够更好地处理具有大分辨率和复杂纵横比的图像,特别是在视觉定位、文档/表格/图表分析和特征提取等任务中表现突出。动态拼接策略通过将高分辨率图像切分为多个局部块,利用共享的视觉转换器处理每个块,并将提取的特征无缝整合到语言模型中,从而保留了视觉转换器在局部注意力上的优势,同时避免了分辨率提升时计算量指数增长的问题。 其次,语言组件采用了 DeepSeekMoE 模型,结合了多头潜在注意力(Multi-head Latent Attention,MLA)机制,该机制通过将 Key-Value 缓存压缩为潜在向量,大大降低了计算成本,提升了推理效率和吞吐量。此外,DeepSeek-VL2 还利用了 MoE 框架中的稀疏计算技术,通过高效的参数激活减少了不必要的计算,从而进一步优化了训练和推理过程的效率。DeepSeek-VL2 模型有三个变种:DeepSeek-VL2-Tiny(10亿激活参数)、DeepSeek-VL2-Small(28亿激活参数)和 DeepSeek-VL2(45亿激活参数),在相似或更少的激活参数下,DeepSeek-VL2 与现有的开源密集型和 MoE 模型相比,表现出了竞争力甚至是领先的性能。 在数据构建方面,DeepSeek-VL2 提升了视觉-语言训练数据的质量、数量和多样性,进一步扩展了模型在视觉问答、光学字符识别、文档/表格/图表理解、视觉推理等任务中的应用能力。此外,新的数据集还使得模型能够处理更复杂的任务,如视觉定位和图形用户界面(GUI)感知。 https://arxiv.org/abs/2412.10302 HuggingFace&Github NexusAI:智能协作的未来 重新定义团队协作:
一个融合人类与人工智能能力的开源平台,实现任务自动化、智能决策、全流程可视化,释放无限生产力,推动组织迈向更智能的未来。 任务自动化:使用智能代理分解和执行任务,最大限度地减少重复工作。 工作流管理:模块化工作流设计器支持复杂业务场景的多步骤任务流。 实时协作:人类和人工智能代理的无缝集成,以提高团队效率。 全球透明度:仪表板提供对任务进度、资源分配和团队活动的全面监督。 知识库支持:集成多种文档格式并自动解析内容以供代理使用。 技能扩展:自定义 Python 脚本,灵活解决特定需求。 https://github.com/EDEAI/NexusAI
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/28952.html