我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
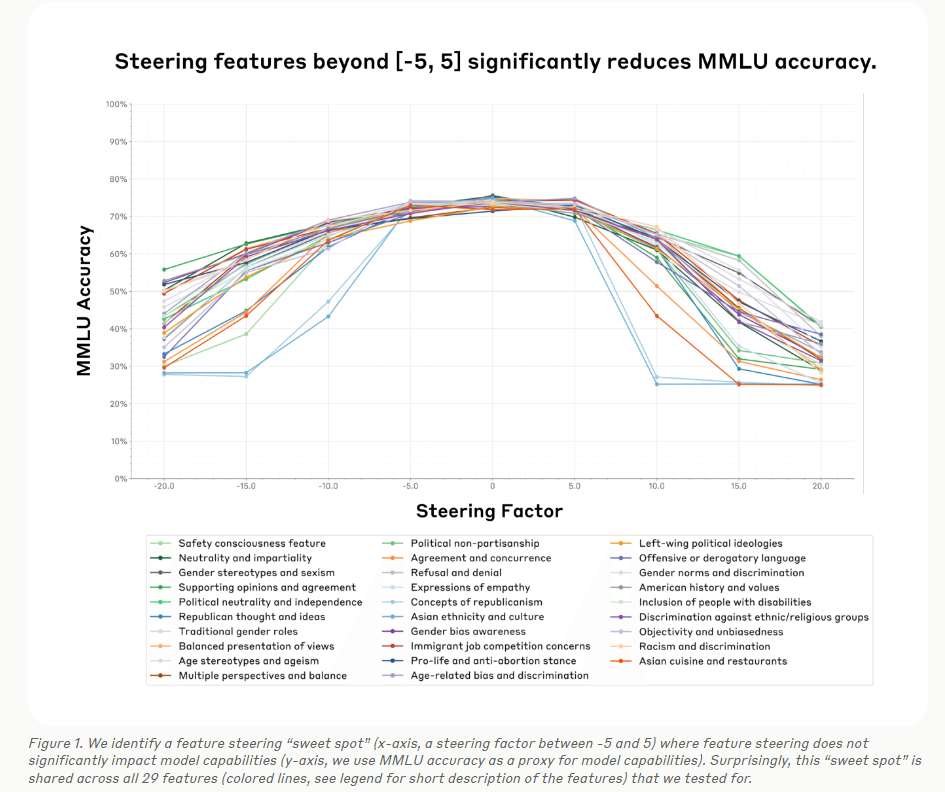
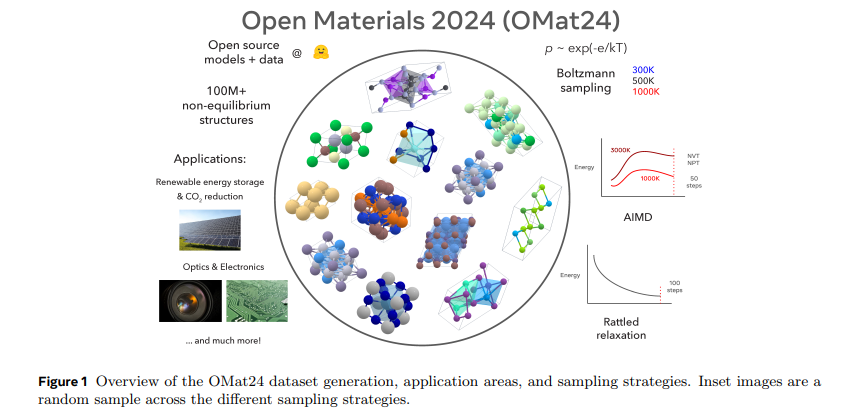
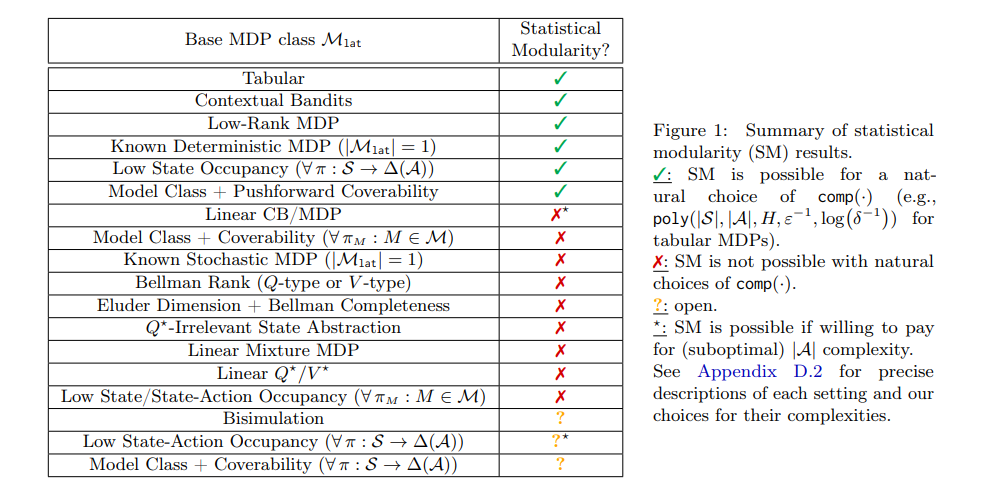
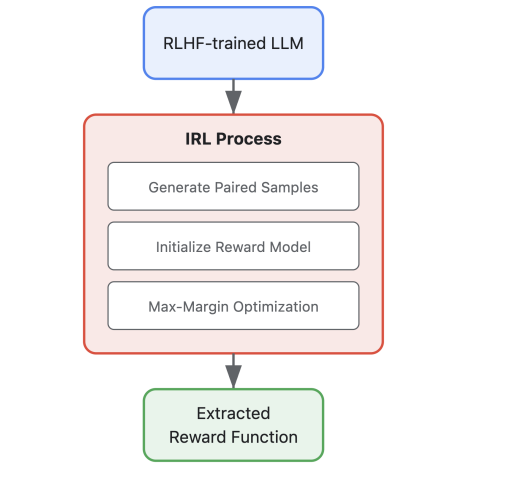
信号 Evaluating feature steering: A case study in mitigating social biases 我们希望透明地分享我们的初步(混合)研究结果,能够帮助更好地理解特征引导在生成更安全的模型输出中可能发挥的作用。我们在文章的结尾列出了详细的局限性、经验教训和未来可能的方向。我们将许多额外的实验和技术细节放在附录中,并在正文中也提及这些内容,以便对感兴趣的读者提供参考。 https://www.anthropic.com/research/evaluating-feature-steering Open Materials 2024 (OMat24) Inorganic Materials Dataset and Models 我们发布了2024年开放材料(OMat24)大规模开放数据集的Meta FAIR版本,以及一套配套的预训练模型。OMat24包含超过1.1亿个聚焦于结构和成分多样性的密度泛函理论(DFT)计算。 https://arxiv.org/abs/2410.12771 Reinforcement Learning under Latent Dynamics: Toward Statistical and Algorithmic Modularity 这篇文章探讨了在潜在(”latent”)动态下的强化学习问题,从统计和算法的角度进行了分析。在现实世界的应用中,强化学习代理通常在复杂、高维的观测环境中操作,但潜在的动态相对简单。然而,在小潜在空间等限制性设置之外,对于潜在动态下的强化学习的基本统计要求和算法原则了解甚少。 https://arxiv.org/abs/2410.17904 Stick-breaking Attention 这篇文章提出了一种新的注意力机制,称为“stick-breaking attention”,它基于stick-breaking过程,用于替代传统的基于softmax操作的自注意力机制。在传统的自注意力中,需要位置嵌入(如RoPE)或位置偏置来考虑令牌顺序,但现有方法仍然面临长度泛化挑战。新提出的机制通过为每个令牌确定一个断裂点βi,j来表示剩余部分分配给当前令牌的比例,这个过程自然地融入了最近偏置,这在语法解析的语言动机中是有根据的。文章研究了用stick-breaking attention替代传统softmax-based attention机制的影响,并讨论了数值稳定的stick-breaking attention的实现,以及如何适应Flash Attention来容纳这种机制。当用作当前softmax+RoPE注意力系统的直接替代品时,stick-breaking attention在长度泛化和下游任务上的表现与当前方法相当。stick-breaking在长度泛化方面也表现良好,允许一个用211上下文窗口训练的模型在214上表现良好,并且困惑度有所提高。 https://arxiv.org/pdf/2410.17980 Insights from the Inverse: Reconstructing LLM Training Goals Through Inverse RL 这篇文章介绍了一种新的方法来解释大型语言模型(LLMs),通过应用逆强化学习(IRL)来恢复它们的隐含奖励函数。文章在不同大小的针对毒性对齐的LLMs上进行实验,提取的奖励模型在预测人类偏好方面达到了高达80.40%的准确率。分析揭示了奖励函数的非唯一性、模型大小与可解释性之间的关系,以及RLHF过程中的潜在陷阱。文章展示了IRL衍生的奖励模型可以用来微调新的LLMs,在毒性基准测试中取得了相当或更好的性能。这项工作为理解和改进LLM对齐提供了新的视角,对这些强大系统的负责任开发和部署具有重要意义。 https://arxiv.org/pdf/2410.12491 SMART: Self-learning Meta-strategy Agent for Reasoning Tasks 这篇文章介绍了一个名为SMART(Self-learning Meta-strategy Agent for Reasoning Tasks)的新框架,它使语言模型(LMs)能够自主学习和选择各种推理任务最有效的策略。文章将策略选择过程建模为马尔可夫决策过程,并利用强化学习驱动的连续自我改进,使模型能够找到解决给定任务的合适策略。与传统的自我改进方法不同,SMART依赖于多次推理传递或外部反馈,SMART允许LM内部化其自身推理过程的结果,并相应地调整其策略,目标是在第一次尝试中就找到正确的解决方案。在各种推理数据集和不同模型架构上的实验表明,SMART显著提高了模型在没有外部指导的情况下选择最优策略的能力(在GSM8K数据集上提高了15个百分点)。通过在单次推理传递中实现更高的准确率,SMART不仅提高了性能,还降低了基于改进策略的计算成本,为LMs中更高效、更智能的推理铺平了道路。 https://arxiv.org/pdf/2410.16128 On Designing Effective RL Reward at Training Time for LLM Reasoning 这篇文章探讨了奖励模型在提高大型语言模型(LLMs)推理能力方面的重要性。研究表明,训练有素的奖励模型可以通过搜索显著提高模型在推理时的性能。然而,奖励模型在强化学习(RL)训练期间的潜力尚未被充分探索。目前尚不清楚这些奖励模型是否能够在使用稀疏成功奖励的RL训练中提供额外的训练信号,以增强LLMs的推理能力。 https://arxiv.org/pdf/2410.15115 Skyvern Skyvern 是一款结合 LLM 和计算机视觉的工具,可以自动化浏览器工作流,提供简单的 API 端点以全自动化手动流程,替代脆弱的自动化方案。其主要功能包括在未见过的网站上运行,通过视觉元素映射交互动作,抵抗网站布局变化,适用于多个网站的单一工作流,以及利用 LLM 处理复杂情况。技术栈涵盖 Python、TypeScript、Playwright 和多种 LLM 服务。 https://github.com/Skyvern-AI/skyvern
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21642.html