我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
制作一个单一的、多功能的基于物理的控制器,可以为各种场景中的交互式角色注入生命力,代表了角色动画中令人兴奋的前沿。理想的控制器应该支持多种控制模式,例如稀疏目标关键帧、文本指令和场景信息。虽然以前的工作提出了物理模拟、场景感知控制模型,但这些系统主要集中于开发控制器,每个控制器专门负责一组狭窄的任务和控制模式。这项工作提出了 MaskedMimic,这是一种新颖的方法,它将基于物理的角色控制表述为一般的运动修复问题。我们的主要见解是训练一个统一的模型来根据部分(屏蔽的)运动描述合成运动,例如屏蔽的关键帧、对象、文本描述或其任何组合。这是通过利用运动跟踪数据并设计可扩展的训练方法来实现的,该方法可以有效地利用不同的运动描述来生成连贯的动画。通过这个过程,我们的方法学习了一个基于物理的控制器,它提供了直观的控制界面,而不需要对所有感兴趣的行为进行繁琐的奖励工程。由此产生的控制器支持广泛的控制模式,并实现不同任务之间的无缝转换。通过运动修复来统一角色控制,MaskedMimic 可创建多功能的虚拟角色。这些角色可以动态适应复杂的场景,并根据需要做出多样化的动作,从而实现更具互动性和沉浸感的体验。

https://x.com/_akhaliq/status/1838429483231064136
Zero-shot Cross-lingual Voice Transfer for TTS
在本文中,我们介绍了一种零样本语音传输(VT)模块,该模块可以无缝集成到多语言文本转语音(TTS)系统中,以跨语言传输个人的语音。我们提出的 VT 模块包括一个处理参考语音的说话者编码器、一个瓶颈层和连接到预先存在的 TTS 层的剩余适配器。我们比较这些组件的各种配置的性能,并报告跨语言的平均意见得分 (MOS) 和说话者相似度。使用每个说话者的单一英语参考语音,我们在九种目标语言中实现了 73% 的平均语音传输相似度得分。声音特征对个人身份的构建和感知有很大贡献。由于身体或神经系统疾病而失去声音可能会导致深刻的失落感,影响一个人的核心身份。作为一个案例研究,我们证明我们的方法不仅可以转移典型语音,还可以恢复构音障碍患者的声音,即使只有非典型语音样本可用 – 对于那些从未有过典型语音或存储声音的人来说,这是一个有价值的实用工具。

https://x.com/_akhaliq/status/1838436253168963753
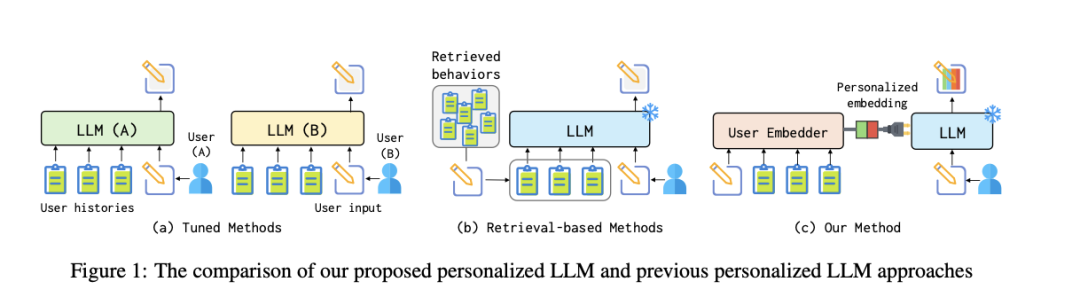
LLMs + Persona-Plug = Personalized LLMs
个性化在许多语言任务和应用程序中起着至关重要的作用,因为具有相同需求的用户可能会根据个人兴趣更喜欢不同的输出。这导致了各种个性化方法的发展,旨在适应大型语言模型(LLM)以生成符合用户偏好的定制输出。其中一些涉及为每个用户微调独特的个性化LLM,这对于广泛应用来说过于昂贵。替代方法通过检索用户的相关历史文本作为演示,以即插即用的方式引入个性化信息。然而,这种基于检索的策略可能会破坏用户历史的连续性,并且无法捕获用户的整体风格和模式,从而导致性能次优。为了应对这些挑战,我们提出了一种新颖的个性化 LLM 模型,ours{}。它通过轻量级插件用户嵌入器模块对每个人的所有历史上下文进行建模,为每个人构建特定于用户的嵌入。通过将这种嵌入附加到任务输入中,法学硕士可以更好地理解和捕获用户习惯和偏好,从而产生更个性化的输出,而无需调整自己的参数。对语言模型个性化 (LaMP) 基准中的各种任务进行的广泛实验表明,所提出的模型显着优于现有的个性化 LLM 方法。
https://arxiv.org/abs/2409.11901Controllable Character Video Synthesis with Spatial Decomposed
角色视频合成旨在在逼真的场景中生成可动画角色的逼真视频。作为计算机视觉和图形领域的一个基本问题,3D 作品通常需要多视图捕获来进行逐例训练,这严重限制了它们在短时间内建模任意角色的适用性。最近的 2D 方法通过预先训练的扩散模型打破了这一限制,但它们在姿势通用性和场景交互方面存在困难。为此,我们提出了 MIMO,一种新颖的框架,它不仅可以合成具有由简单用户输入提供的可控属性(即角色、动作和场景)的角色视频,而且还可以同时实现对任意角色的高级可扩展性、对新颖 3D 的通用性动作以及在统一框架中对交互式现实世界场景的适用性。其核心思想是考虑到视频发生的固有 3D 性质,将 2D 视频编码为紧凑的空间代码。具体来说,我们使用单目深度估计器将 2D 帧像素提升为 3D,并根据 3D 深度将视频剪辑分解为分层中的三个空间分量(即主要人物、底层场景和浮动遮挡)。这些成分进一步被编码为规范的身份代码、结构化运动代码和全场景代码,用作合成过程的控制信号。空间分解建模的设计实现了灵活的用户控制、复杂的运动表达以及场景交互的3D感知合成。实验结果证明了该方法的有效性和鲁棒性。

https://x.com/_akhaliq/status/1838794123270086890
Reward-Robust RLHF in LLMs随着大型语言模型 (LLM) 不断向更高级的智能形式发展,人类反馈强化学习 (RLHF) 越来越被视为实现通用人工智能 (AGI) 的关键途径。然而,由于奖励模型(RM)固有的不稳定性和缺陷,对基于奖励模型(RM)的对齐方法的依赖带来了重大挑战,这可能导致奖励黑客和与人类意图不一致等关键问题。在本文中,我们介绍了一个奖励稳健的 RLHF 框架,旨在解决这些基本挑战,为法学硕士更可靠、更有弹性的学习铺平道路。我们的方法引入了一种新颖的优化目标,通过结合贝叶斯奖励模型集成(BRME)来对奖励函数的不确定性集进行建模,仔细平衡性能和鲁棒性。这使得该框架能够整合名义性能和最小奖励信号,即使在奖励模型不完善的情况下也能确保更稳定的学习。实证结果表明,我们的框架在各种基准测试中始终优于传统的 RLHF,显示出更高的准确性和长期稳定性。我们还提供了理论分析,证明奖励稳健的 RLHF 接近恒定奖励设置的稳定性,这在随机案例分析中被证明是有效的。这些贡献共同凸显了框架提高 LLM 与 RLHF 一致性的性能和稳定性的潜力。
 https://x.com/_akhaliq/status/1838802758264029362
https://x.com/_akhaliq/status/1838802758264029362
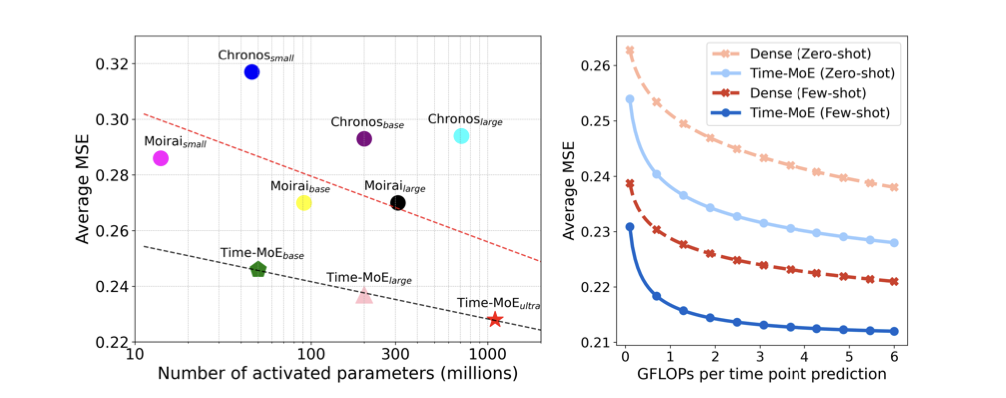
Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts
过去几十年来,时间序列预测的深度学习取得了重大进展。然而,尽管大规模预训练在语言和视觉领域取得了成功,但预训练时间序列模型的规模仍然有限,并且运行成本很高,阻碍了在实际应用中开发更强大的预测模型。为此,我们引入了 Time-MoE,这是一种可扩展且统一的架构,旨在预训练更大、能力更强的预测基础模型,同时降低推理成本。通过利用稀疏专家混合 (MoE) 设计,Time-MoE 通过仅激活每个预测的网络子集来提高计算效率,从而在保持高模型容量的同时减少计算负载。这使得 Time-MoE 能够有效地扩展,而不会相应增加推理成本。 Time-MoE 包含一系列仅解码器变压器模型,这些模型以自回归方式运行,并支持具有不同输入上下文长度的灵活预测范围。我们在新引入的大规模数据 Time-300B 上对这些模型进行了预训练,该数据跨越 9 个领域,涵盖超过 3000 亿个时间点。我们首次将时间序列基础模型扩展至 24 亿个参数,显着提高了预测精度。我们的结果验证了时间序列预测背景下训练标记和模型大小的缩放法则的适用性。与具有相同数量的激活参数或等效计算预算的密集模型相比,我们的模型始终大幅优于它们。这些进步使 Time-MoE 成为最先进的解决方案,能够以卓越的功能、效率和灵活性应对现实世界的时间序列预测挑战。
https://arxiv.org/abs/2409.16040
学习
Robot Data第一季的访谈围绕机器人数据金字塔展开,探讨了从低质量的互联网和合成数据,到高质量但获取难度大的机器人遥操作数据之间的不同数据层级。核心内容集中在数据的获取、融合和优化上。以下是技术细节的总结:
EP1和EP4探讨了如何利用互联网视频数据(如YouTube)来训练机器人大模型。ATM工作提出将视频转化为粒子的集合,通过建模粒子运动来提取物理信息,为机器人控制提供先验知识,而无需关注画面的精细度。MimicPlay通过高层次的轨迹规划,从人类视频中学习任务策略,而不是直接模仿动作,从而减少数据需求并提升系统效率。
EP5、EP6和EP8涉及合成数据与真实数据的结合。HumanPlus将仿真数据与真实遥操作数据结合,通过强化学习生成大规模仿真数据,同时利用真实数据提升控制精度。Eureka利用LLM自动生成奖励函数和域随机化参数,实现从仿真到现实的策略转移。RoboGen通过可微分模拟优化刚体与柔性物体的交互,并自动化奖励函数设计,解决了仿真与现实之间的差距问题。
EP2和EP4强调了动作捕捉数据的重要性。UMI通过便携式设备解决了机器人数据采集的可移植性问题,大大简化了多样化环境中的数据获取。DexCap通过高精度的电磁传感器和SLAM技术,实现了毫米级的手部动作捕捉,用于机器人动作控制。
EP3和EP5讨论了机器人遥操作的创新方法。Open-TeleVision通过沉浸式3D视觉和活动颈部技术,提升了操作的直观性和效率。Mobile Aloha利用少量真实数据通过高效模仿学习,让机器人快速掌握各种任务。
EP9总结了如何处理多模态和跨领域的数据。PoCo通过任务层、领域层和行为层的组合策略,提升了机器人数据的通用性。通过跨域数据的融合,解决了机器人形态多样、数据分散的问题,为训练更具通用性的机器人模型奠定了基础。

https://mp.weixin.qq.com/s/vBmjT_9_K8SDmuTwo1WCOA
Cerebras在上半年推出了CS-3,一款为大模型训练和推理打造的第三代晶圆级AI加速器。CS-3的体积非常庞大,面积相当于56个NVIDIA H100。CS-3基于台积电5nm工艺,拥有超过4万亿个晶体管,集成了90万个AI核心和44GB片上内存,具备21Pbps的内存带宽。相较于前代产品,CS-3的速度提升了2倍。
CS-3的可扩展性依赖于SwarmX互连技术,可以将多达2048个CS-3系统链接在一起,构建出高达256 exaflops的AI超级计算机。同时,MemoryX存储体系支持24TB至1200TB的外部内存,允许单个系统训练多达24万亿参数的模型,这意味着CS-3可以在不到一天的时间内训练Llama2-70B模型,而在传统的GPU集群上,这需要大约一个月。
SwarmX互联与Weight Streaming架构
CS-3采用了spine-leaf拓扑结构,通过400/800G以太网支持RDMA协议。其独特的Weight Streaming架构将整个集群抽象为一个芯片,简化了分布式计算的复杂性。
WSE-3内核增加了2倍的计算能力,每个内核配置8-way FP/BF16 SIMD单元、16-way INT8 SIMD单元,并支持稀疏加速与数据流调度。每个芯片通过2D网格结构连接所有核心,确保芯片与晶圆级统一互联,支持高效的数据传输。
在推理方面,CS-3大内存设计突破了推理中的内存墙限制,相比NVIDIA的DGX-H100,CS-3在Llama3.1-8B模型推理中实现了20倍的性能提升,并且支持多用户并行推理。Cerebras独特的架构设计降低了训练与推理中的延迟,使其能够更好地应对大型AI模型的需求。
CS-3的设计理念是“大计算+大内存”,通过内存与计算分离、片上互联减少通信开销等技术,确保高扩展性和高吞吐。CS-3还支持多种稀疏结构的加速,包括静态、动态、结构化与非结构化的稀疏计算,加速了大规模AI模型的训练与推理。
总结来看,Cerebras CS-3通过创新的设计与技术突破了传统计算架构的限制,展现了AI计算的巨大潜力。

https://zhuanlan.zhihu.com/p/721998906
-
-
-
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/21245.html
