我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
大型语言模型(LLM)的最新进展引发了人们对其形式推理能力的兴趣,尤其是在数学方面。GSM8K 基准被广泛用于评估模型在小学水平问题上的数学推理能力。虽然近年来LLM 在GSM8K上的表现显着提高,但尚不清楚它们的数学推理能力是否真正提高了,这引发了人们对报告指标可靠性的质疑。为了解决这些问题,研究者对几个 SOTA 开放和封闭模型进行了大规模研究。为了克服现有评估的局限性,引入了GSM-Symbolic,这是一种改进的基准,由允许生成多样化问题的符号模板创建。研究结果表明,LLM 在回答同一问题的不同实例时表现出明显的差异。具体而言,当在GSM-Symbolic 基准中仅改变问题中的数值时,所有模型的性能都会下降。此外,研究者研究了这些模型中数学推理的脆弱性,并表明随着问题中子句数量的增加,它们的性能会显著下降。研究者假设这种下降是因为当前的LLM无法进行真正的逻辑推理;它们从训练数据中复制推理步骤。添加一个似乎与问题相关的子句会导致所有最先进模型的性能显著下降(高达65%),即使该子句对最终答案所需的推理链没有贡献。总的来说,笔者们的工作提供了对 LLM 在数学推理方面的能力和局限性的更细致的理解。
https://arxiv.org/abs/2410.05229
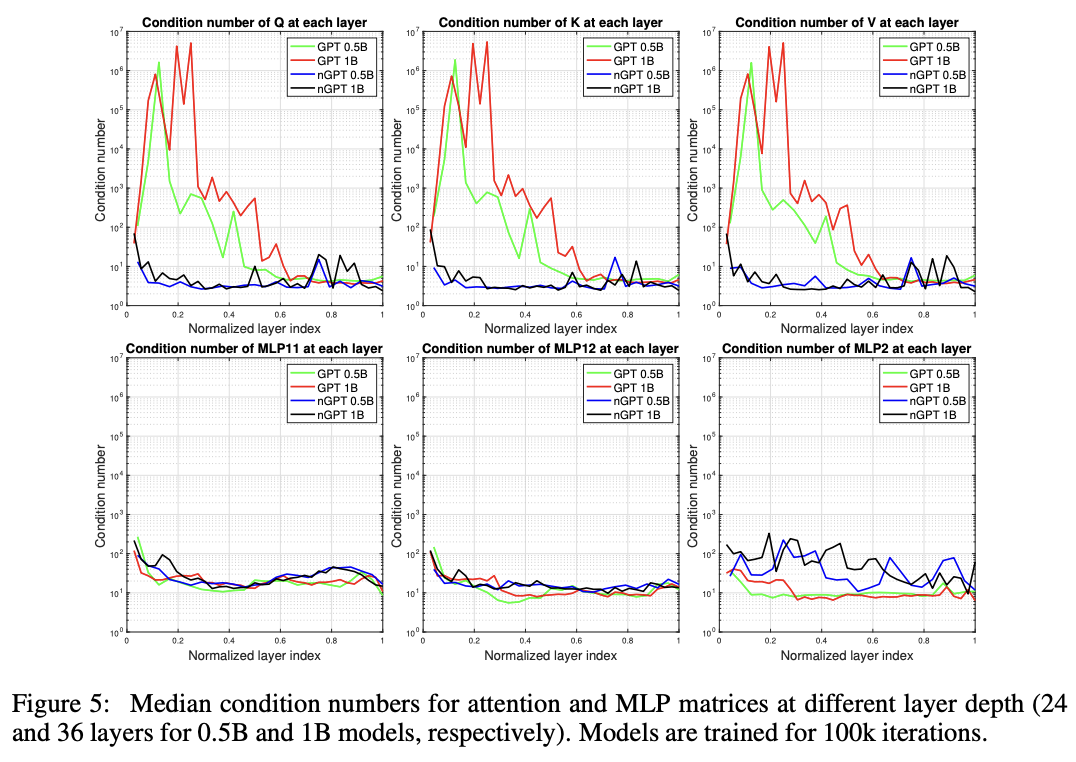
nGPT: Normalized Transformer with Representation Learning on the Hypersphere
本研究提出了一种新颖的神经网络架构,即在超球面上进行表征学习的正则化 Transformer (nGPT)。在 nGPT 中,形成嵌入、MLP、注意矩阵和隐藏状态的所有向量都是单位范数正则化的。输入的 token 流在超球面上传播,每一层都会向目标输出预测贡献一个位移。这些位移由 MLP 和注意块定义,它们的向量分量也位于同一个超球面上。实验表明,nGPT 的学习速度要快得多,根据序列长度,将实现相同准确度所需的训练步骤数减少了 4 到 20 倍。
https://arxiv.org/abs/2410.01131
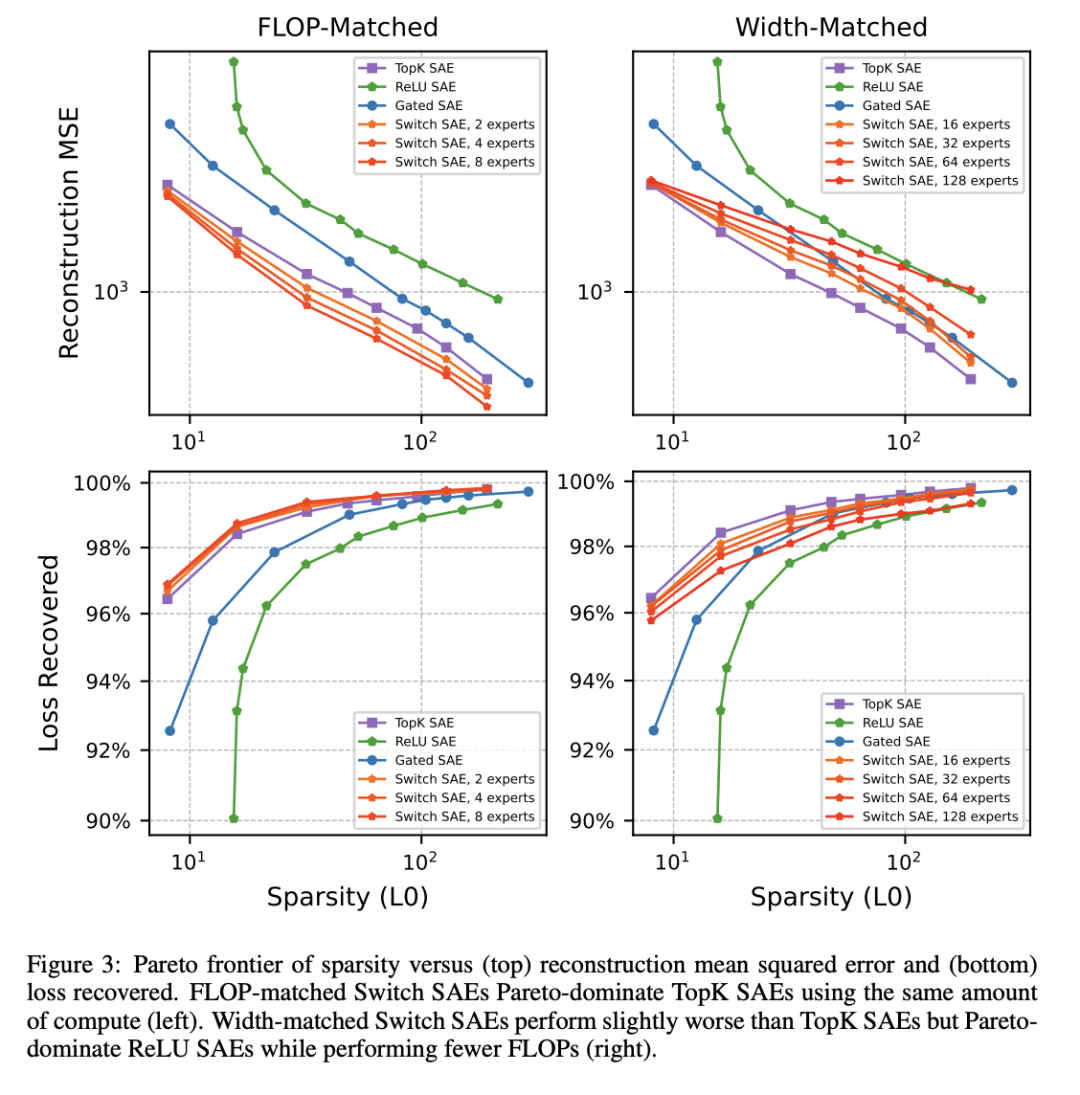
Efficient Dictionary Learning with Switch Sparse Autoencoders
稀疏自动编码器 (SAE) 是一种将神经网络激活分解为人类可解释特征的最新技术。然而,为了让 SAE 识别边界模型中表示的所有特征,必须将它们扩展到非常高的宽度,这对计算提出了挑战。在这项工作中,研究者引入了 Switch 稀疏自动编码器,这是一种新颖的 SAE 架构,旨在降低训练 SAE 的计算成本。受稀疏混合专家模型的启发,Switch SAE 在较小的“专家”SAE 之间路由激活向量,使 SAE 能够有效地扩展到更多特征。我们进行了将 Switch SAE 与其他 SAE 架构进行比较的实验,发现在给定的固定训练计算预算下,Switch SAE 在重构与稀疏边界方面实现了显着的帕累托改进。我们还研究了跨专家的特征几何形状,分析了跨专家重复的特征,并验证了 Switch SAE 特征与其他 SAE 架构发现的特征一样可解释。
https://arxiv.org/abs/2410.08201
Optima: Optimizing Effectiveness and Efficiency for LLM-Based Multi-Agent System Models
基于大型语言模型 (LLM) 的多智能体系统 (MAS) 在协作解决问题方面表现出巨大潜力,但它们仍然面临着严峻的挑战:通信效率低、可扩展性差以及缺乏有效的参数更新优化方法。本文提出了 Optima,这是一个新颖的框架,通过 LLM 训练显著提高基于 LLM 的 MAS 中的通信效率和任务效率来解决这些问题。Optima 采用迭代生成、排名、选择和训练范式,奖励函数平衡任务性能、令牌效率和通信可读性。研究者探索了各种 RL 算法,包括监督微调、直接偏好优化及其混合方法,深入了解了它们的有效性-效率权衡。研究者集成了蒙特卡洛树搜索启发的技术来生成 DPO 数据,将对话轮次视为树节点以探索不同的交互路径。在常见的多智能体任务(包括信息不对称问答和复杂推理)上进行评估后,Optima 显示出与单智能体基线和基于 Llama 3 8B 的 vanilla MAS 相比持续且显著的改进,在需要大量信息交换的任务上以不到 10% 的 token 实现了高达 2.8 倍的性能提升。此外,Optima 的效率提升为更有效地利用推理计算开辟了新的可能性,从而改善了推理时间缩放定律。通过解决基于 LLM 的 MAS 中的基本挑战,Optima 展示了可扩展、高效和有效 MAS 的潜力。
https://arxiv.org/abs/2410.08115
-
-
-
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21576.html