我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
Practical Deep Learning
Fast.ai 课程提供深入的深度学习教育,涵盖从基础到高级的各种主题。课程使用PyTorch框架,教授如何构建、训练和优化深度学习模型。技术细节包括卷积神经网络(CNN)、循环神经网络(RNN)、迁移学习和数据增强等。课程强调实践,通过代码示例和项目帮助学生掌握实际技能。除了理论讲解,课程还提供了优化技巧、模型调试方法和高效训练策略,确保学员能够在真实项目中应用所学知识。
 https://course.fast.ai/
https://course.fast.ai/
Diffusion Inference Optimization
本系列文章探讨了作者在试图优化最近Toyota研究院的Diffusion Policy论文推断延迟方面的学习成果。作者深入研究了GPU架构的复杂性,并将这些学习应用到加速TRI论文中的U-Net上。文章附带了相应的代码,可以在此系列的GitHub存储库中找到。
 https://www.vrushankdes.ai/diffusion-inference-optimization
https://www.vrushankdes.ai/diffusion-inference-optimization
使用AutoTrain训练物体检测模型
AutoTrain简化了物体检测模型的训练流程,支持本地和云端训练。以下是关键步骤:
-
UI方法:创建包含图片和metadata.jsonl文件的Zip文件,metadata.jsonl包含边界框和类别信息(COCO格式)。
-
CLI方法:将图片和metadata.jsonl文件分别放在训练和验证文件夹中。
-
基本参数:如图片尺寸、批处理大小、训练轮数、学习率等。
-
高级参数:如优化器、学习率调度、权重衰减、混合精度等。
-
CLI训练:创建配置文件,运行
autotrain命令。
-
UI训练:本地或在Hugging Face空间上启动AutoTrain UI。
AutoTrain通过简化数据准备和参数配置,使物体检测模型训练变得更容易。所有模型都可以通过API推理和推理端点进行部署。
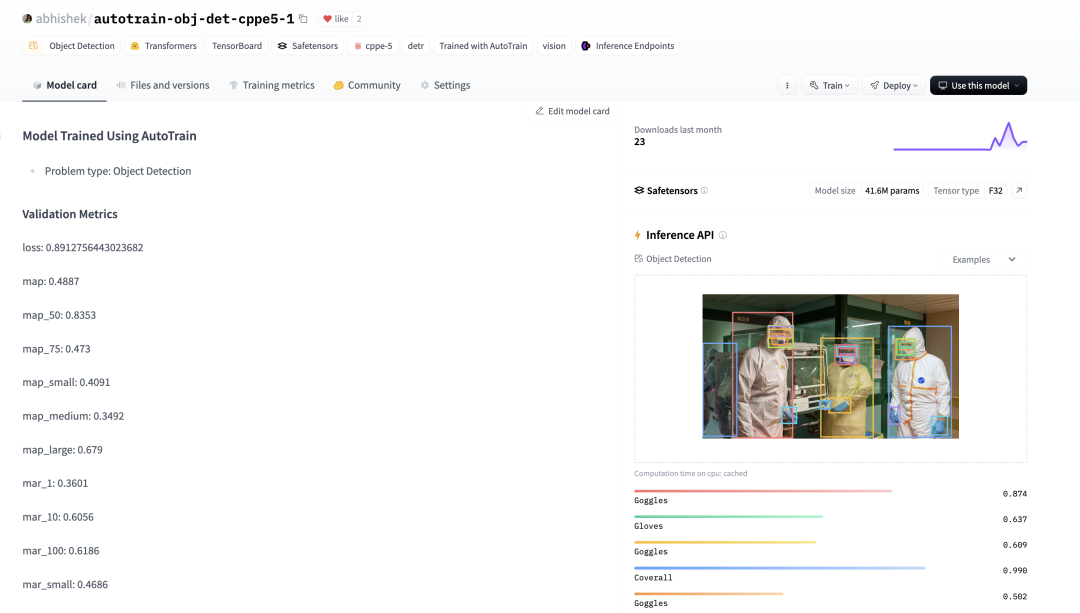 https://huggingface.co/blog/abhishek/object-detection-autotrain
LLM帮助理解整个Github Repository提高Coding效率的进展和挑战
https://huggingface.co/blog/abhishek/object-detection-autotrain
LLM帮助理解整个Github Repository提高Coding效率的进展和挑战
大语言模型(LLMs)在理解和处理整个 GitHub 仓库代码方面取得了进展,但仍存在挑战。进步包括上下文长文本的实现、推理成本的降低、软件工程框架的成熟和读取 – 理解 – 生成(RAG)技术的逐渐成熟。技术细节涉及如何通过 LLMs 处理代码层级关系、注意力分配和多模态数据对齐问题,以及如何解决缺乏人类反馈数据和微调阶段数据复杂性不足的问题。相关论文和工具提出了基于知识图谱、Topological 数据构建和迭代检索生成等解决方案,目标是让 LLMs 更像人类一样进行精确的代码设计和优化。作者正在从事自动反思工程,旨在提升 LLMs 在代码生成和优化中的自主能力。
 https://zhuanlan.zhihu.com/p/701989753?utm_psn=1782097799741050880
https://zhuanlan.zhihu.com/p/701989753?utm_psn=1782097799741050880
Torchao 稀疏性
torchao 稀疏性部分提供了一系列工具和 API,用于实现模型的加速和内存优化。网页详细说明了稀疏性技术的目标、设计理念以及实现方法。稀疏性的关键在于选择合适的参数移除策略,以及如何通过加速核心和优化算法来实现性能提升。网页还展示了使用 torchao 稀疏性功能对 segment-anything 和 BERT 模型的加速成果,包括具体的性能指标和内存使用情况。此外,网页还提供了稀疏性相关术语的解释,以及不同稀疏性模式的比较和优化策略。
 https://github.com/pytorch/ao/tree/main/torchao/sparsity
https://github.com/pytorch/ao/tree/main/torchao/sparsity
未来HBM的核心键合技术
未来 HBM 技术的核心在于实现更高密度和带宽的 DRAM 堆叠,关键在于采用 Hybrid Bonding 技术。该技术通过铜间直接键合,去除了对 bump 的依赖,实现了 Copper Pad 到 Copper Pad 的直接结合,显著减少了连接层厚度,提升了散热性能,并支持更小的 bump pitch。Hybrid Bonding 在较低温度下完成,有助于提高晶圆的稳定性和可靠性。与传统的 Micro Bump 技术相比,Hybrid Bonding 减少了寄生参数,有利于提升传输速度和降低互联功耗。目前,HBM3/HBM3E 已实现 12 层 DRAM 堆叠,而业界正面向 HBM4,期待通过 Hybrid Bonding 技术实现更多层数的堆叠,以满足未来更大容量和更高带宽的需求。
AI + Universities
报告探讨了人工智能(AI)对高等教育的深远影响,特别是在美国大学中的应用。核心观点包括:AI 发展迅速,美国在全球处于领先地位;AI 正在改变学习和教学方式,提供个性化学习和实时反馈;未来大学将更数字化,传统教学模式将被颠覆;AI 可以显著提高教育效率,但也要求大学重新思考和调整教育策略,以应对新的挑战和机遇。
 https://www.bondcap.com/reports/aiu
https://www.bondcap.com/reports/aiu
We-MATH
We-Math是一个关于新型数学问题解决的基准测试,探索语言模型在数学推理方面的原理和局限性。团队收集了6.5K个视觉数学问题,涵盖67个知识概念和5个知识粒度层次,并提出了一个四维评估指标,包括不足知识(IK)、不足泛化(IG)、完全掌握(CM)和死记硬背(RM)。通过对现有语言模型的全面评估,发现解题步骤与具体问题表现呈负相关,但知识增强策略可以有效改善IK问题。值得注意的是,GPT-4已经从IK转向了IG,成为首个进入知识泛化阶段的语言模型,而其他模型则倾向于死记硬背。
 https://we-math.github.io/
https://we-math.github.io/
dolphin-vision-72b
dolphin-vision-72b是一个由Quan Nguyen、Eric Hartford和Cognitive Computations团队开发的强大的多模态语言模型。它拥有73.2B参数,使用BF16张量类型,支持文本生成任务。该模型是基于Qwen/Qwen2-72B进行微调的,并使用了多个数据集进行训练,包括OpenHermes-2.5、microsoft/orca-math-word-problems-200k和Locutusque/function-calling-chatml。这是一个未经审查的模型,能够对图像进行推理和评论,而其他流行的模型可能会反对。该模型得到了Crusoe Cloud和TensorWave的赞助支持,分别提供了8xH100节点用于训练和8xmi300x节点用于评估及推理。
 https://huggingface.co/cognitivecomputations/dolphin-vision-72b
https://huggingface.co/cognitivecomputations/dolphin-vision-72b
-
-
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/14363.html

