
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


资讯
Yann LeCun:ViT慢且效率低,实时图像处理还得看卷积
 https://mp.weixin.qq.com/s/VO_AgwBJYrZHOgVXVqG3Ew
https://mp.weixin.qq.com/s/VO_AgwBJYrZHOgVXVqG3Ew开源模型进展盘点:最新Mixtral、Llama 3、Phi-3、OpenELM到底有多好?
 https://mp.weixin.qq.com/s/bgdDYkGHbPZMMSJPIutFSQ
https://mp.weixin.qq.com/s/bgdDYkGHbPZMMSJPIutFSQHugging Face称检测到对其人工智能模型托管平台的”未经授权访问”
多模态大模型不够灵活,谷歌DeepMind创新架构Zipper:分开训练再「压缩」
 https://mp.weixin.qq.com/s/F8wstkJyYiNJCbSqYq3Pbw
https://mp.weixin.qq.com/s/F8wstkJyYiNJCbSqYq3Pbw“最强ATM”中东,投了中国独角兽智谱AI
 https://mp.weixin.qq.com/s/DpLur3pBbVhp6uXcWCjCbw
https://mp.weixin.qq.com/s/DpLur3pBbVhp6uXcWCjCbw翠贝卡电影节将首映使用 OpenAl Sora 制作的五部短片
 https://www.hollywoodreporter.com/business/business-news/tribeca-festival-short-films-made-openai-1235912280/
https://www.hollywoodreporter.com/business/business-news/tribeca-festival-short-films-made-openai-1235912280/单GPU训练一天,Transformer在100位数字加法上就达能到99%准确率
 https://mp.weixin.qq.com/s/zHx_pMk6sHmIm-AJCS_sRA
https://mp.weixin.qq.com/s/zHx_pMk6sHmIm-AJCS_sRA超长小说可以用AI翻译了,新型多智能体协作系统媲美人工翻译
 https://mp.weixin.qq.com/s/q6qm0Pd0XAKZ2oUNna53vw
https://mp.weixin.qq.com/s/q6qm0Pd0XAKZ2oUNna53vw推特
ElevenLabs发布最新模型,用声效来创造丰富和沉浸式的内容
 https://x.com/elevenlabsio/status/1796567542565118151?s=46&t=GRStLXDcUNuun8J5Noyw4Q
https://x.com/elevenlabsio/status/1796567542565118151?s=46&t=GRStLXDcUNuun8J5Noyw4Q
FineWeb技术报告:详细解释了每一个处理决策,并介绍最新数据集FineWeb-Edu
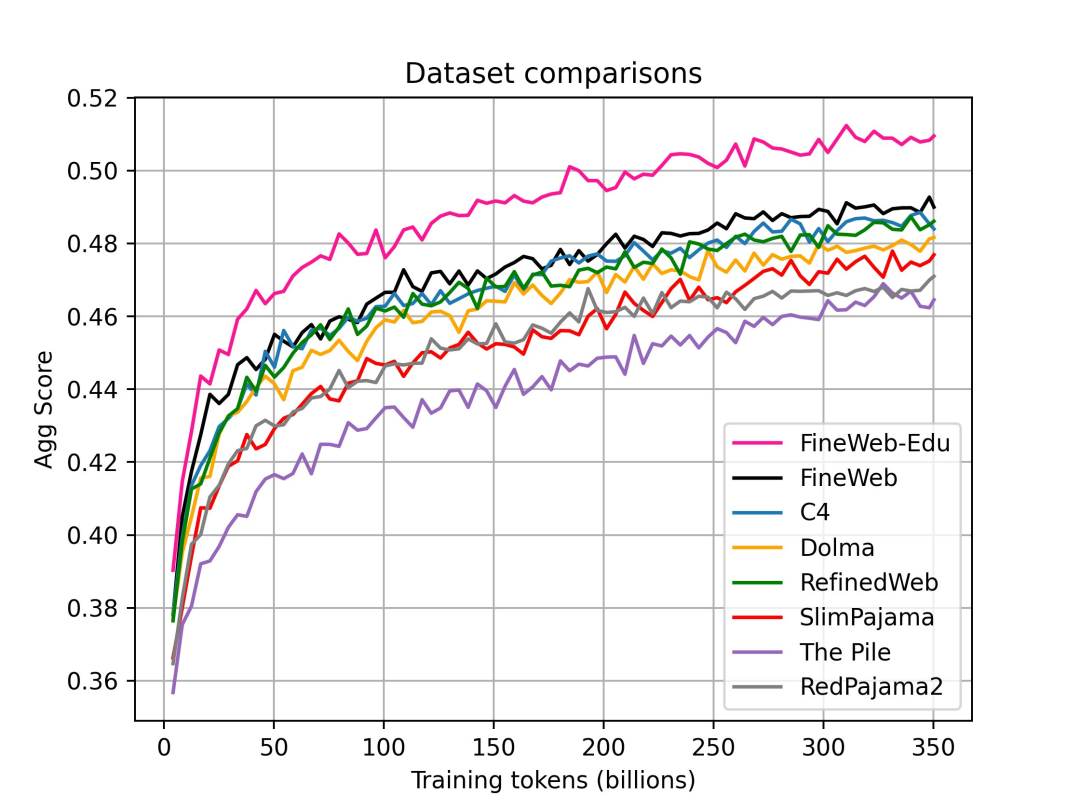 https://x.com/gui_penedo/status/1797173053123916036
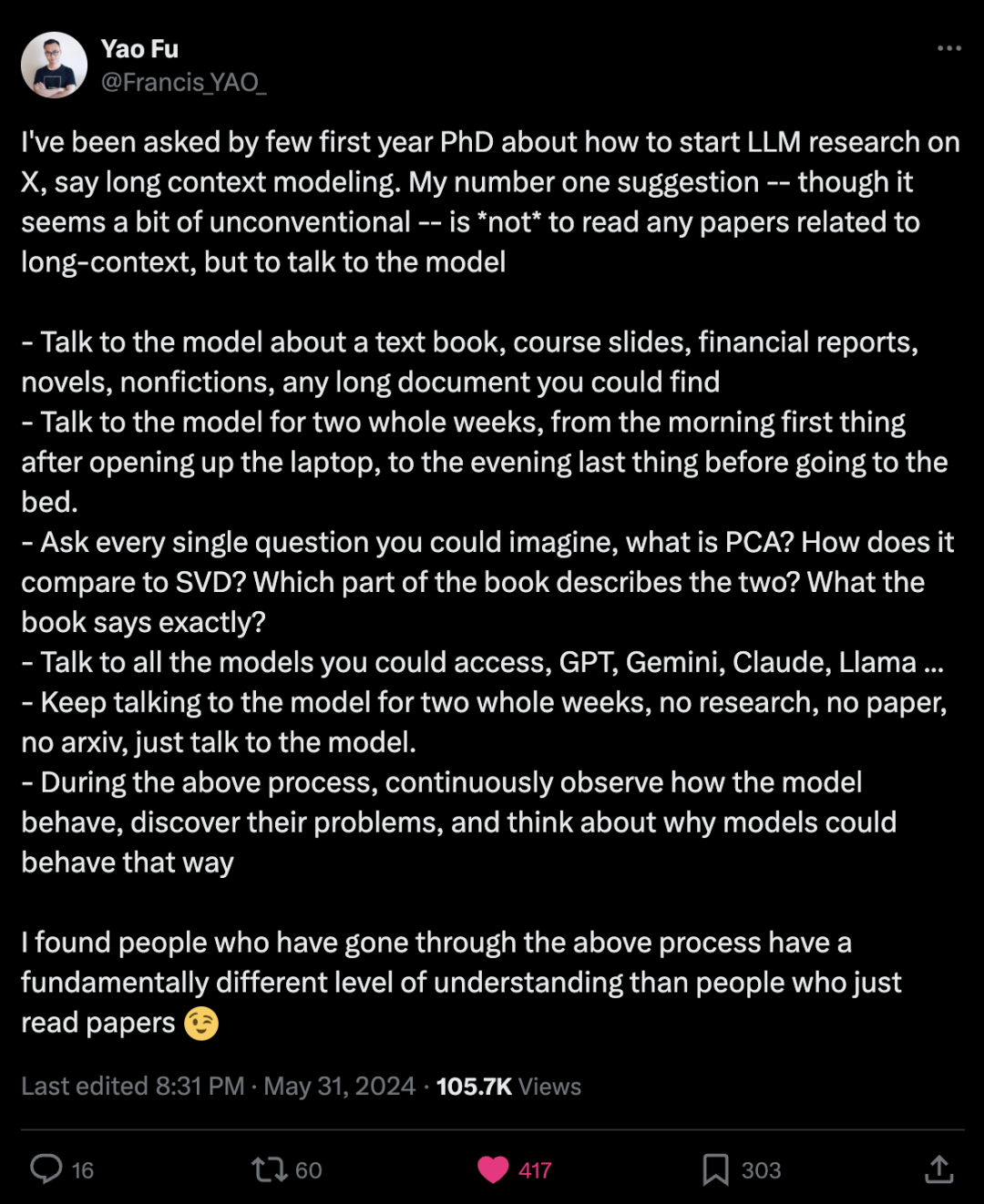
https://x.com/gui_penedo/status/1797173053123916036Yao Fu分享建议:不要阅读任何与长文本相关的论文,而是与模型对话
-
与模型讨论教科书、课程幻灯片、财务报告、小说、非小说类书籍,以及你能找到的任何长文档。 -
整整两周每天都与模型对话,从早上打开笔记本的第一件事,到晚上睡前的最后一件事。 -
问你能想到的每一个问题,什么是PCA?它与SVD有何比较?书中的哪一部分描述了这两者?书上具体怎么说的? -
与你能接触到的所有模型对话,GPT、Gemini、Claude、Llama…… -
持续两周与模型对话,不做研究,不看论文,不看arxiv,只是与模型对话。 -
在上述过程中,不断观察模型的行为,发现它们的问题,并思考为什么模型会这样表现。
 https://x.com/francis_yao_/status/1796519894814453827?s=46&t=GRStLXDcUNuun8J5Noyw4Q
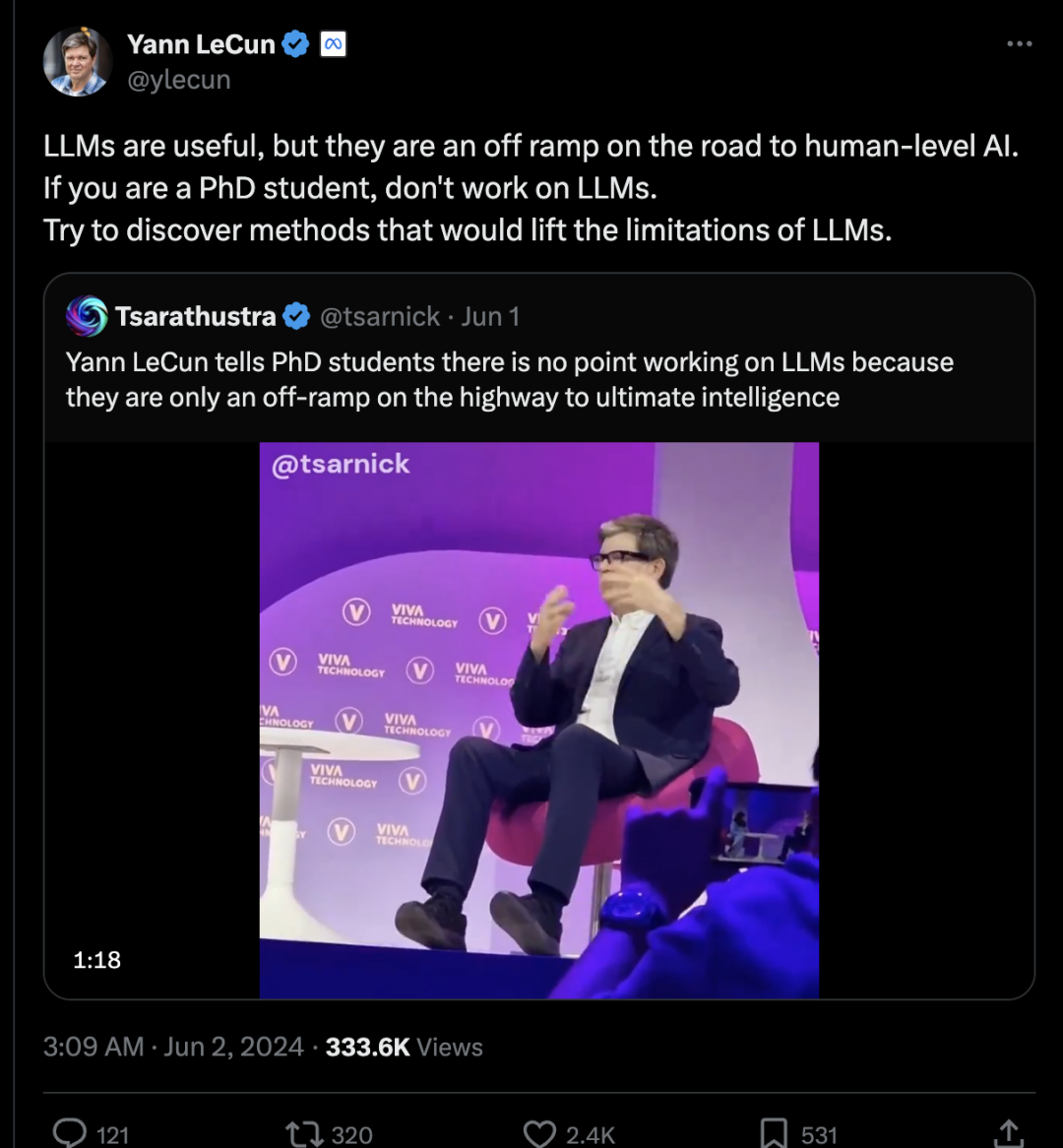
https://x.com/francis_yao_/status/1796519894814453827?s=46&t=GRStLXDcUNuun8J5Noyw4QLeCunn再声明:如果你是博士生,不要研究LLMs,试着发现能够突破LLMs限制的方法
 https://x.com/ylecun/status/1796982509567180927?s=46&t=GRStLXDcUNuun8J5Noyw4Q
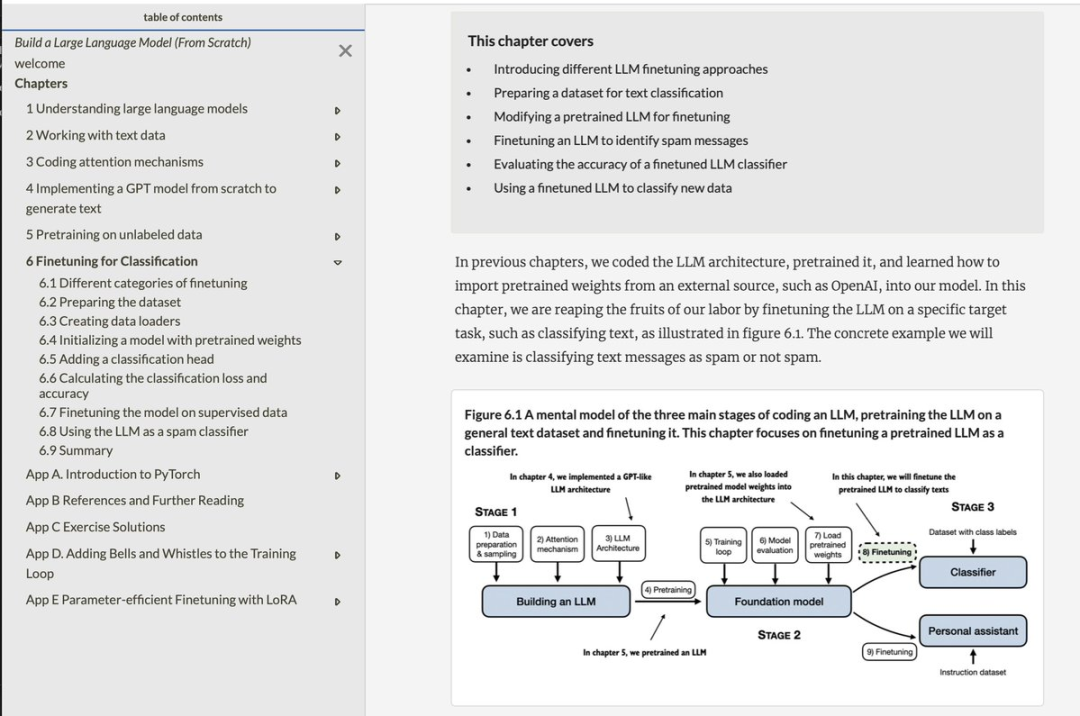
https://x.com/ylecun/status/1796982509567180927?s=46&t=GRStLXDcUNuun8J5Noyw4QSebastian Raschka分享:《从头开始构建大型语言模型》第六章,LLMs的微调分类
 https://x.com/rasbt/status/1796517550303371459
https://x.com/rasbt/status/1796517550303371459一致性角色:创建给定角色在不同姿势下的图像
 https://x.com/fofrAI/status/1796547108478038355
https://x.com/fofrAI/status/1796547108478038355
产品
Artizyou
 https://promo.artizyou.com/
https://promo.artizyou.com/Linked CRM
 https://linkedcrm.ai/
https://linkedcrm.ai/原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14927.html