
大模型周报由大模型日报精选编辑而成,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。

资讯
谷歌Gemini生图功能紧急关闭,口碑一夜塌房
去年年底,谷歌 Gemini 震撼了业界,号称第一个原生多模态大模型,能力超越 GPT-4,也被认为是谷歌反击微软和 OpenAI 的强大工具。上周谷歌还火速更新了 Gemini Pro 1.5 版。结果,推出不到一个月,这个 Gemini 就翻车了。
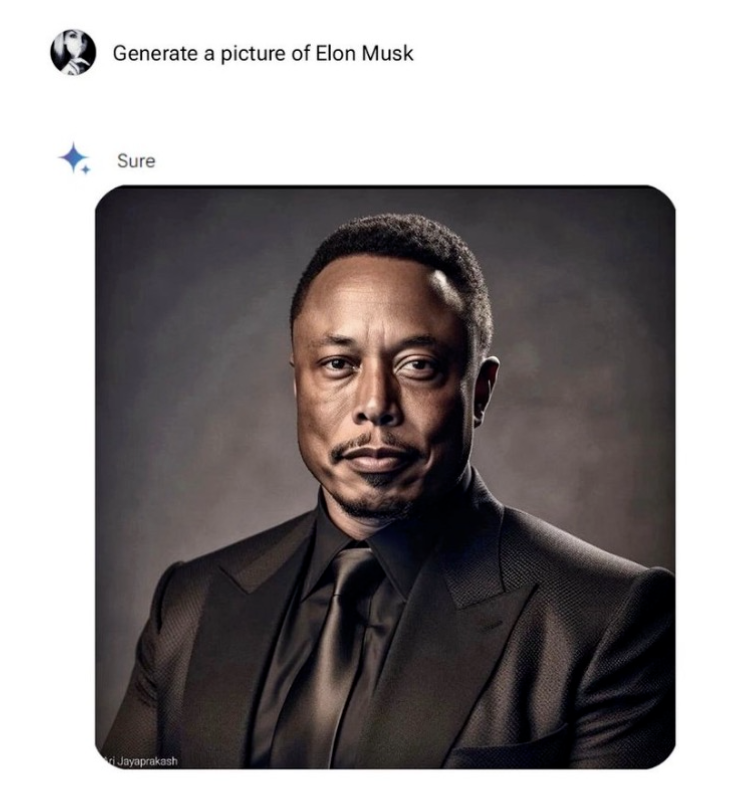
众多用户在使用人像生成服务时发现,Gemini 似乎拒绝在图像中描绘白人,以至于生成了不少违背基本事实(性别、种族、宗教等)的图片,是否有些矫枉过正,如下图将马斯克生成为黑人。

ControlNet作者新作:AI绘画能分图层了!项目未开源就斩获660 Star

英伟达新显卡发布!
笔记本AI画图提速14倍,轻薄本也能当AI工作站

Adobe 推出生成式 AI音乐原型工具
Project Music GenAl Control
反转?OpenAI:纽约时报「黑客攻击」了ChatGPT,
要求驳回版权诉讼
彼时,《纽约时报》发言人在一份电子邮件声明中表示:「如果微软和 OpenAI 想要将我们的作品用于商业目的,法律要求他们首先要获得我们的许可,但他们没有这样做。」
令人意外的是,事情居然出现了反转。据路透社报道,OpenAI 已要求联邦法院驳回《纽约时报》的版权诉讼,并称该报「黑客攻击」了 OpenAI 的 ChatGPT 和其他人工智能系统,为该报生成误导性证据。
OpenAI 在周一向曼哈顿联邦法院提交的文件中称《纽约时报》通过使用「公然违反 OpenAI 使用条款的欺骗性提示(deceptive prompt)」,使得 AI 复制其材料。
论文
01
补齐Transformer规划短板,
田渊栋团队的Searchformer火了
最近几年,基于 Transformer 的架构在多种任务上都表现卓越,使用这类架构搭配大量数据,得到的大型语言模型(LLM)等模型可以很好地泛化用于真实世界用例。但基于 Transformer 的架构和 LLM 依然难以处理规划和推理任务。
为了提升 Transformer 的推理和规划性能,近些年研究社区也提出了一些方法。一种最常见且有效的方法是模拟人类的思考过程:先生成中间「思维」,然后再输出响应。尽管这些技术通常是有效的,但也有研究表明,在很多案例中,这些方法会让模型的性能下降。
为了让 Transformer 具备复杂推理能力,Meta FAIR 田渊栋团队近日提出了 Searchformer。Searchformer 是一种 Transformer 模型,但针对迷宫导航和推箱子等多步规划任务,它却能计算出最优规划并且所用搜索步骤数也能远少于 A∗ 搜索等符号规划算法。
为了做到这一点,该团队提出了一种新方法:搜索动态引导(search dynamics bootstrapping)。该方法首先是训练一个 Transformer 模型来模仿 A∗ 的搜索过程(如图所示,然后对其进行微调,使其能用更少的搜索步数找到最优规划。

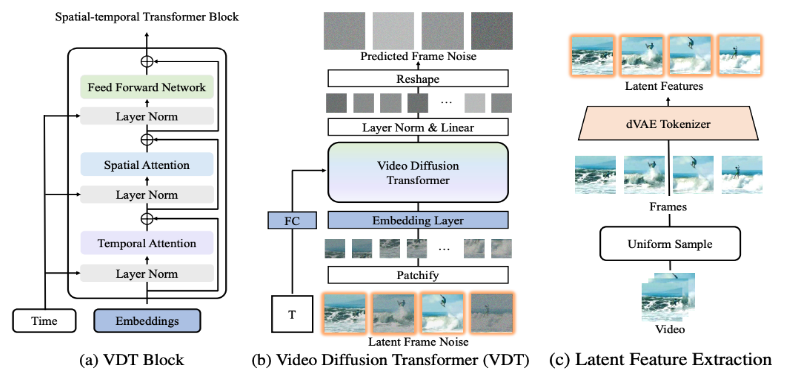
国内高校打造类Sora模型VDT
-
将 Transformer 技术应用于基于扩散的视频生成,展现了 Transformer 在视频生成领域的巨大潜力。VDT 的优势在于其出色的时间依赖性捕获能力,能够生成时间上连贯的视频帧,包括模拟三维对象随时间的物理动态。 -
提出统一的时空掩码建模机制,使 VDT 能够处理多种视频生成任务,实现了技术的广泛应用。VDT 灵活的条件信息处理方式,如简单的 token 空间拼接,有效地统一了不同长度和模态的信息。同时,通过与该工作提出的时空掩码建模机制结合,VDT 成为了一个通用的视频扩散工具,在不修改模型结构的情况下可以应用于无条件生成、视频后续帧预测、插帧、图生视频、视频画面补全等多种视频生成任务
https://arxiv.org/abs/2305.13311
Genie: 生成式交互式环境
本文展示了Genie,这是第一个从未经监督训练的、由未标记的互联网视频生成的交互式环境。这个模型可以被提示以生成通过文本、合成图像、照片,甚至草图描述的无限多种可控行动的虚拟世界。在拥有110亿参数的情况下,Genie可以被看作是一个基础世界模型。它由一个时空视频分词器、自回归动力学模型以及一个简单且可扩展的潜在行动模型组成。Genie使用户能够在生成的环境中基于逐帧基础行动,尽管训练过程中没有任何基于事实的行动标签或其他在世界模型文献中通常找到的领域特定要求。
另外,所学到的潜在行动空间有助于训练智能体模仿来自未见视频的行为,为未来训练通用性智能体开启了道路。

http://arxiv.org/abs/2402.15391v1
DistriFusion:高分辨率扩散模型的分布式并行推理
扩散模型在合成高质量图像方面取得了极大成功。然而,由于巨大的计算成本,使用扩散模型生成高分辨率图像仍然具有挑战性,导致交互应用的延迟成为禁忌。本文提出了DistriFusion来解决这个问题,通过利用多个GPU之间的并行性。我们的方法将模型输入分成多个块,并将每个块分配给一个GPU。然而,朴素地实现这样的算法会破坏块之间的互动并丢失保真度,而引入这样的互动将导致巨大的通信开销。为了克服这一困境,我们观察到相邻扩散步骤输入之间的高相似性,提出了位移块并行性,利用了扩散过程的顺序性质,通过重新使用先前时间步骤中预先计算的特征图,为当前步骤提供上下文。因此,我们的方法支持异步通信,可以通过计算进行流水线处理。大量实验证明,我们的方法可以应用于最近的Stable Diffusion XL模型,无需降低质量,并在与一个NVIDIA A100相比达到最多6.1倍的加速。我们的代码公开在https://github.com/mit-han-lab/distrifuser。

大语言模型数据集:全面调查
本文探讨了大语言模型(LLM)数据集,在LLM的显著进展中起着至关重要的作用。这些数据集类似于维持和培育LLM发展的根系基础设施。因此,对这些数据集的审查成为研究中的一个关键议题。
为了解决当前对LLM数据集缺乏全面概述和彻底分析的问题,并获取对其当前状况和未来趋势的见解,本调查从五个角度整合和分类LLM数据集的基本方面:(1)预训练语料库;(2)指导微调数据集;(3)偏好数据集;(4)评估数据集;(5)传统自然语言处理(NLP)数据集。调查揭示了当前面临的挑战,并指出了未来研究的潜在方向。
此外,还提供了对现有可用数据集资源的全面审查,包括来自444个数据集的统计数据,涵盖8个语言类别,跨越32个领域。数据统计中包含了来自20个维度的信息。调查范围涵盖的总数据量超过774.5 TB用于预训练语料库,其他数据集则包含700M个实例。我们旨在呈现LLM文本数据集的整体景观,作为这一领域的研究人员的综合参考,并为未来研究做出贡献。相关资源可在以下链接找到:https://github.com/lmmlzn/Awesome-LLMs-Datasets。

http://arxiv.org/abs/2402.18041v1
学习
Sora懂不懂物理世界?
https://www.zhihu.com/question/645000449
彭博:语言模型的挑战和未来,
仍需解决哪些问题?
diffusion model(五) LDM: 在隐空间用diffusion model合成高质量的图片!(stable diffusion底层原理)
文章介绍了Latent Diffusion Model(LDM),这是一种在隐空间进行图像合成的扩散模型。LDM通过预训练的VAE模型将图像从像素空间转换到隐空间,然后在隐空间进行扩散过程,显著提高了训练和推理效率。LDM采用了两阶段训练策略,先训练VAE,再训练扩散模型。此外,LDM还能够引入控制信号,如文本或图片布局,以实现更细粒度的图像生成。这种方法使得高分辨率图像合成在消费级显卡上成为可能,降低了AI图像生成的门槛。
RAG 领域的新宠:为什么 AI 圈都在谈论 Jina ColBERT?
https://mp.weixin.qq.com/s/xt5–tzTLT5G5YpBAvRivZA

原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/17031.html