
MOLAR NEWS
2020年第44期
MolarData人工智能每周见闻分享,每周一更新。
联邦学习最新医疗场景发布:杨强团队与刘琦团队合作打破药物数据共享壁垒
近日,国内AI场景应用再次取得重要成果。来自同济大学生物信息系的刘琦教授课题组与微众银行杨强教授AI团队合作,通过联邦学习来进行本地药物隐私数据的保障,以及模拟多个制药机构(用户)之间的药物协同开发,助力制药机构在保障自身药物数据隐私安全的前提下进行协同药物发现。


联邦学习是近年提出的一种新的合法链接数据孤岛进行数据共享计算的协作范式,由谷歌和杨强教授团队分别在to C和to B场景率先提出。相比于传统数据加密共享方法,联邦学习基于数据可用不可见的理念,通过聚合所有用户的加密模型参数,在数据不出本地的情况下进行模型协同训练,能够更好的面对数据共享领域出现的新的问题和法律法规约束。
来源:AI科技评论
人工智能让遥感数据释放巨大潜能:人口普查中的「人工」或将被取代
Abitbol & Karsai 分别来自法国里昂高等师范学院 (ENS) 和匈牙利中欧大学(CEU),近日他们联合开发了一个神经网络模型,以实现从航拍图像中预测给定地点的社会经济状况,进而根据潜在的城市拓扑结构解释其激活图,从而缩小基于城市拓扑结构和高分辨率的社会经济地图之间预测的差距。该研究证实了卷积神经网络(CNN)针对卫星图像数据深入分析的潜能。
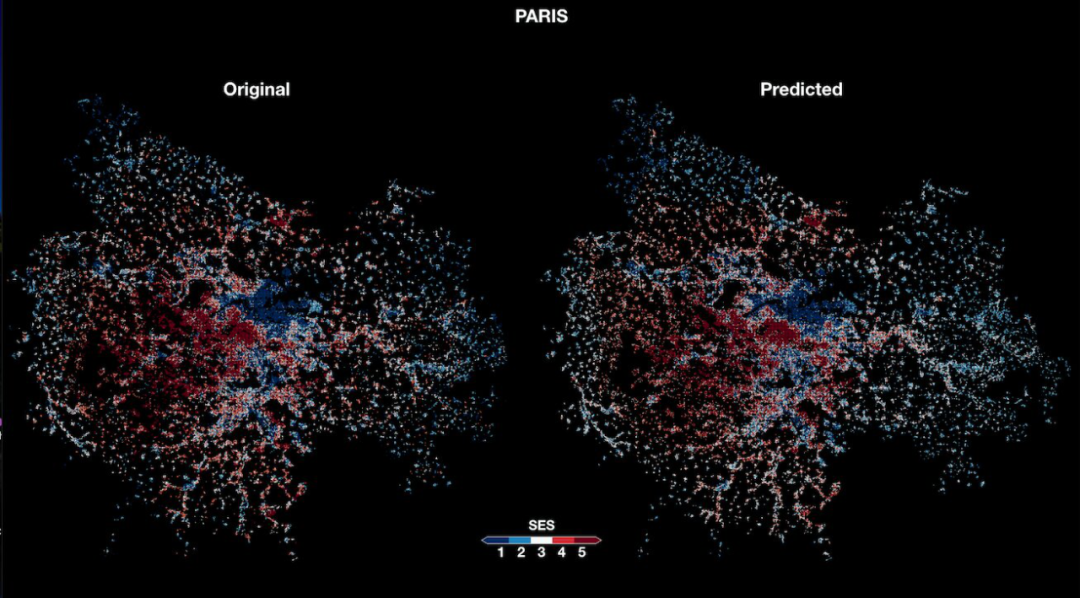
通过将高分辨率的类判别激活图投射到原始地图上,并与土地利用数据叠加,以生成经验统计的特征,使模型更为准确地预测该地区在社会经济地位方面的土地利用类别。这一方案让社会经济地位的预测范围更加广泛,同时也精确地指出了预测城市环境的真实特征。此外,它还提供了不同的城市在城市拓扑结构和财富分配之间的关联模式。
来源:机器之心
速度数百倍之差,有人断言KNN面临淘汰,更快更强的ANN将取而代之
在模式识别领域中,K – 近邻算法(K-Nearest Neighbor, KNN)是一种用于分类和回归的非参数统计方法。K – 近邻算法非常简单而有效,它的模型表示就是整个训练数据集。
近似最近邻算法(Approximate Nearest Neighbor, ANN)则是一种通过牺牲精度来换取时间和空间的方式从大量样本中获取最近邻的方法,并以其存储空间少、查找效率高等优点引起了人们的广泛关注。
近日,一家技术公司的数据科学主管 Marie Stephen Leo 撰文对 KNN 与 ANN 进行了比较,结果表明,在搜索到最近邻的相似度为 99.3% 的情况下,ANN 比 sklearn 上的 KNN 快了 380 倍。

来源:机器之心
谷歌:引领ML发展的迁移学习,究竟在迁移什么
迁移学习就是把一个领域已训练好的模型参数迁移到另一个领域,使得目标领域能够取得更好的学习效果。鉴于大部分的数据具有存在相关性,迁移学习可以比较轻松地将模型已学到的知识分享给新模型,从而避免了从头学习,这加快效率,也大大提高样本不充足任务的分类识别结果。

今年的 NeurIPS 上,谷歌的一支研究团队发表了一篇名为 What is being transferred in transfer learning? 的论文,揭示了关于迁移学习的最新研究进展。
具体而言,通过对迁移到块混洗图像(block-shuffled images)的一系列分析,他们从学习低层数据统计中分离出了特征复用(feature reuse)的效果,并表明当从预训练权重进行初始化训练时,该模型位于损失函数 “地图” 的同一 “盆地”(basin)中,不同实例在特征空间中相似,并且在参数空间中接近(注:basin 一词在该领域文献中经常使用,指代参数空间中损失函数相对较低值的区域)。
来源:数据实战派
FaceBook的检索增强生成方法,更好地胜任知识密集型任务
在 2020 NeurIPS 所接收的论文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 中,来自 FaceBook 的一个研究小组就介绍了他们将信息检索组件和 seq2seq 生成器结合而得的检索增强生成(RAG)架构。
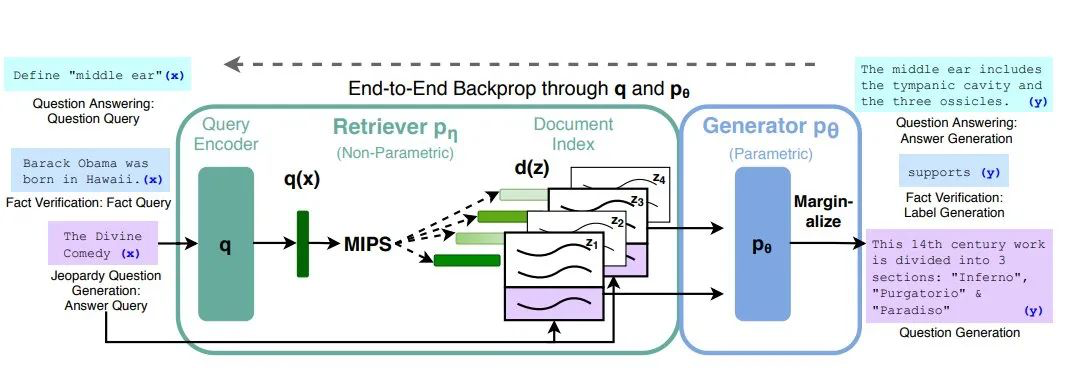
在知识密集型下游任务上,即便是与最大的预训练 seq2seq 模型相比,RAG 也能在微调之后实现新的记录。而且,与这些经过预训练模型不同,RAG 的内部知识可以轻松地随时更改甚至补充,这意味着研究者和开发人员可以控制 RAG 所知和未知的内容,从而避开重新训练整个模型的时间和财力物力成本。
来源:数据实战派
AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2020/12/8475.html